{kind=link}
Are you sure you want to delete this task? Once this task is deleted, it cannot be recovered.
You can not select more than 25 topics
Topics must start with a chinese character,a letter or number, can include dashes ('-') and can be up to 35 characters long.
 jasonhuang
7c9b14aa93
jasonhuang
7c9b14aa93
|
1 year ago | |
|---|---|---|
| .. | ||
| README.md | 1 year ago | |
| README_CN.md | 1 year ago | |
| vit.png | 1 year ago | |
| vit_b32_224_ascend.yaml | 1 year ago | |
| vit_b32_224_ascend_pynative.yaml | 1 year ago | |
| vit_l16_224_ascend.yaml | 1 year ago | |
| vit_l32_224_ascend.yaml | 1 year ago | |
README.md
ViT
[2010.11929] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (arxiv.org)
Introduction
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to replace certain components of convolutional networks while keeping their overall structure in place. We show that this reliance on CNNs is not necessary and a pure transformer applied directly to sequences of image patches can perform very well on image classification tasks. When pre-trained on large amounts of data and transferred to multiple mid-sized or small image recognition benchmarks (ImageNet, CIFAR-100, VTAB, etc.), Vision Transformer (ViT) attains excellent results compared to state-of-the-art convolutional networks while requiring substantially fewer computational resources to train.
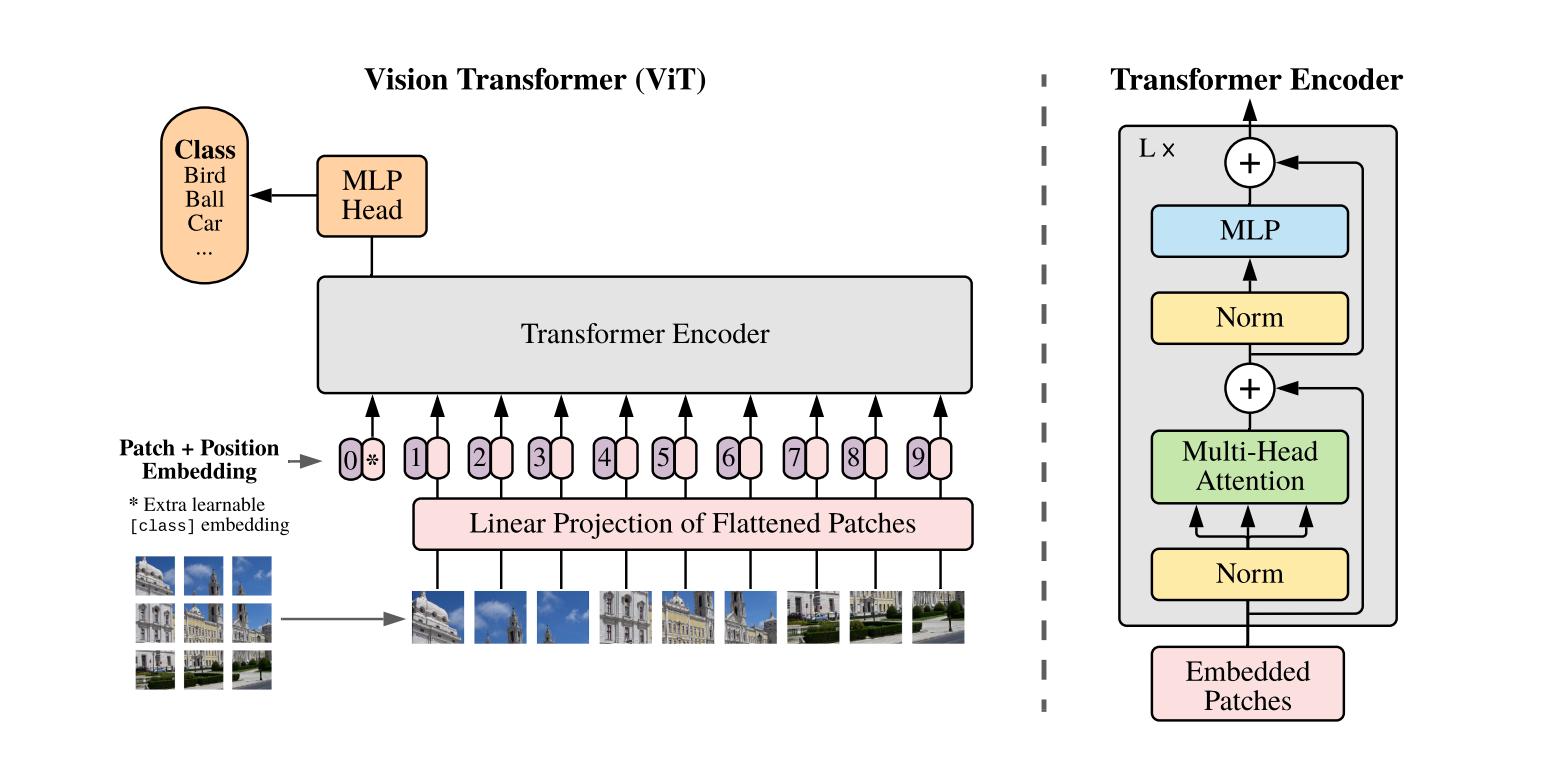
Results
| Model | Context | Top-1 (%) | Top-5 (%) | Params(M) | Train T. | Infer T. | Download | Config | Log |
|---|---|---|---|---|---|---|---|---|---|
| vit_b_32_224 | D910x8-G | 75.86 | 92.08 | 86 | 619ms/step | 11.6ms/step | model | cfg | log |
| vit_l_16_224 | D910x8-G | 76.34 | 92.79 | 307 | 632ms/step | 5.37ms/step | model | cfg | log |
| vit_l_32_224 | D910x8-G | 73.71 | 90.92 | 307 | 534ms/step | 6.22ms/step | model | cfg | log |
Notes
- All models are trained on ImageNet-1K training set and the top-1 accuracy is reported on the validatoin set.
- Context: GPU_TYPE x pieces - G/F, G - graph mode, F - pynative mode with ms function.
Quick Start
Preparation
Installation
Please refer to the installation instruction in MindCV.
Dataset Preparation
Please download the ImageNet-1K dataset for model training and validation.
Training
-
Hyper-parameters. The hyper-parameter configurations for producing the reported results are stored in the yaml files in
mindcv/configs/vitfolder. For example, to train with one of these configurations, you can run:# train vit on 8 NPUs mpirun -n 8 python train.py -c configs/vit/vit_b32_224_ascend.yaml --data_dir /path/to/imagenetNote that the number of GPUs/Ascends and batch size will influence the training results. To reproduce the training result at most, it is recommended to use the same number of GPUs/Ascneds with the same batch size.
Detailed adjustable parameters and their default value can be seen in config.py
Validation
-
To validate the trained model, you can use
validate.py. Here is an example for vit_b_32 to verify the accuracy of pretrained weights.python validate.py -c configs/vit/vit_b32_224_ascend.yaml --data_dir /path/to/imagenet --ckpt_path /path/to/ckpt
Deployment (optional)
Please refer to the deployment tutorial in MindCV.
No Description
Jupyter Notebook Python Markdown Text
Contributors (25+)
285365963@qq.com
100194830+JunyuLiu1@users.noreply.github.com
74176172+GeniusPatrick@users.noreply.github.com

 zp5070@gmail.com
83412649+spencerr221@users.noreply.github.com
zp5070@gmail.com
83412649+spencerr221@users.noreply.github.com
 jasondhuang@tencent.com
jasondhuang@tencent.com
 97332102+XuanmaiXue@users.noreply.github.com
119582555+sy-liang123@users.noreply.github.com
48508716+Baogerock@users.noreply.github.com
2441413514@qq.com
97332102+XuanmaiXue@users.noreply.github.com
119582555+sy-liang123@users.noreply.github.com
48508716+Baogerock@users.noreply.github.com
2441413514@qq.com
 74176172+geniuspatrick@users.noreply.github.com
huxiuyu1943@sina.com
74176172+geniuspatrick@users.noreply.github.com
huxiuyu1943@sina.com
 xingxjtu@gmail.com
xingxjtu@gmail.com
 110210055+xiuyu0000@users.noreply.github.com
110210055+xiuyu0000@users.noreply.github.com
 canna1102.yy@gmail.com
canna1102.yy@gmail.com

74176172+GeniusPatrick@users.noreply.github.com
zp5070@gmail.com
83412649+spencerr221@users.noreply.github.com
jasondhuang@tencent.com
97332102+XuanmaiXue@users.noreply.github.com
119582555+sy-liang123@users.noreply.github.com
48508716+Baogerock@users.noreply.github.com
2441413514@qq.com
74176172+geniuspatrick@users.noreply.github.com
huxiuyu1943@sina.com
xingxjtu@gmail.com
110210055+xiuyu0000@users.noreply.github.com
canna1102.yy@gmail.com