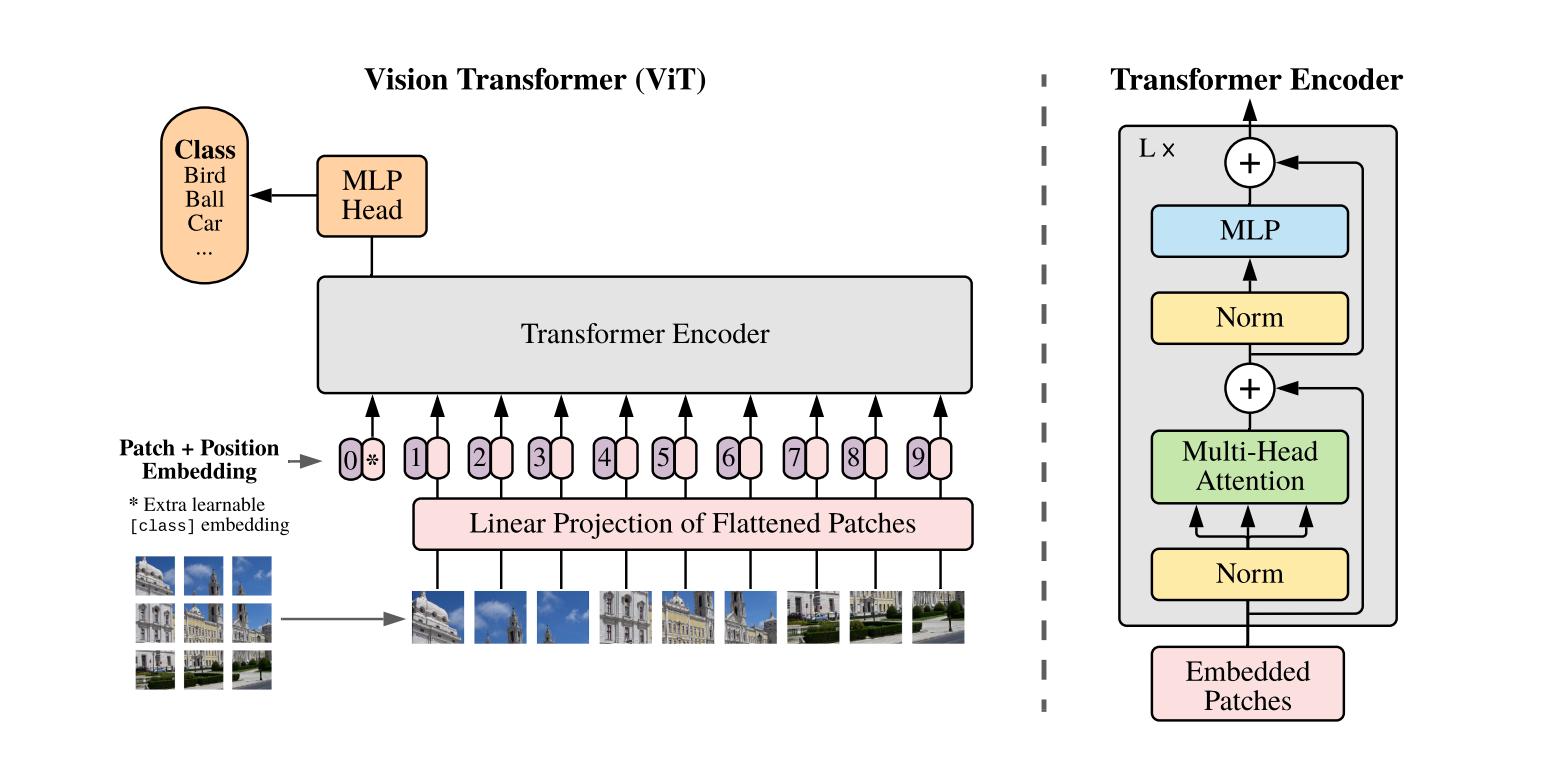
ViT
[2010.11929] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (arxiv.org)
简介
虽然Transformer架构已经成为自然语言处理任务的范式,但它在计算机视觉方面的应用仍然有限。在视觉中,注意力机制要么与卷积网络一起应用,要么用来取代卷积网络的某些模块,同时保持其整体结构。我们表明,这种对CNN的依赖是没有必要的,直接应用于图像斑块序列的纯Transformer在图像分类任务上可以表现得非常好。当对大量数据进行预训练并迁移到多个中型或小型图像识别基准(ImageNet、CIFAR-100、VTAB等)时,与最先进的卷积网络相比,Vision Transformer(ViT)获得了出色的结果,然而这需要大量的计算资源来训练。
性能指标
| Model |
Context |
Top-1 (%) |
Top-5 (%) |
Params(M) |
Train T. |
Infer T. |
Download |
Config |
Log |
| vit_b_32_224 |
D910x8-G |
75.86 |
92.08 |
86 |
619ms/step |
11.6ms/step |
model |
cfg |
log |
| vit_l_16_224 |
D910x8-G |
76.34 |
92.79 |
307 |
632ms/step |
5.37ms/step |
model |
cfg |
log |
| vit_l_32_224 |
D910x8-G |
73.71 |
90.92 |
307 |
534ms/step |
6.22ms/step |
model |
cfg |
log |
备注
- 所有的模型都是在ImageNet-1K训练集上训练的,并且在报告了validatoin集上Top-1的准确性。
- Context: GPU_TYPE x pieces - G/F, G - graph mode, F - pynative mode with ms function.
快速开始
准备
安装
请参考 installation instruction in MindCV.
准备数据集
请下载 ImageNet-1K 数据集用于模型训练和验证。
训练
-
Hyper-parameters. 用于产生报告结果的超参数配置存储在 mindcv/configs/vit . 例如,要用这些配置之一进行训练,你可以运行:
# train vit on 8 NPUs
mpirun -n 8 python train.py -c configs/vit/vit_b32_224_ascend.yaml --data_dir /path/to/imagenet
请注意,GPU/Ascends 的数量和批次大小将影响训练结果。为了最多重现训练结果,建议使用相同数量的GPU/Ascneds和相同的批次大小。
详细的可调整参数及其默认值可以在 config.py 查看。
验证
部署(可选)
请参考MindCV的部署教程。