Are you sure you want to delete this task? Once this task is deleted, it cannot be recovered.
You can not select more than 25 topics
Topics must start with a chinese character,a letter or number, can include dashes ('-') and can be up to 35 characters long.
 xiaoxiong
080ecf7546
xiaoxiong
080ecf7546
|
2 months ago | |
|---|---|---|
| assets | 2 months ago | |
| README.md | 2 months ago | |
README.md
天数智芯GPGPU-调试任务使用指南
在OpenI启智社区上,调试任务是训练任务和推理任务的前置环节。调试任务有4小时的时长限制,具有jupyter lab界面,可以很方便的进行模型训练/推理的调试工作;训练/推理任务时长不限,基于调试好的代码和启动文件可一键启动模型训练/推理,适用于长时间的训练/推理一个模型。下面我将介绍如何在启智社区上使用天垓100训练卡来创建一个调试任务, 本次调试任务我们将会以比较经典的ResNet50在ImageNet数据集上的训练来进行演示。
一、注册启智社区
首先注册一个启智社区的账号,点击启智官方网址进行注册:https://openi.pcl.ac.cn/user/sign_up
二、每日算力积分获取(上限50分)
启智平台的算力积分获取也是非常的方便简单,每日算力积分获取的上限是50,而目前天垓 100 每小时只花费1积分,每天获取的算力积分都够用2天2夜了,完全能满足日常的使用,我这里也把每日算力积分的获取方法贴在右边了:https://openi.pcl.ac.cn/reward/point/rule
三、新建项目
当我们有了算力积分之后就可以开始新建一个项目,步骤如下:
-
请 点击这里 创建新项目。
-
进入创建项目详情界面
- 填写
项目名称,这里以resnet50为例 - 勾选
将项目设为私有,这里和在gitee或github上创建项目是一样的。 - 勾选
承诺遵守平台使用协议 - 点击
创建项目

- 填写
四、上传数据集/关联数据集
创建完项目之后,下一步当然是上传我们电脑上整理好的数据集,或者直接关联平台上已有的数据集。由于ImageNet数据集平台已经提供好了,因此我们这里就不用再花时间去上传了,直接关联数据集就ok,下面是这两个功能 ”当前数据集“ / ”关联数据集“ 的简要介绍:
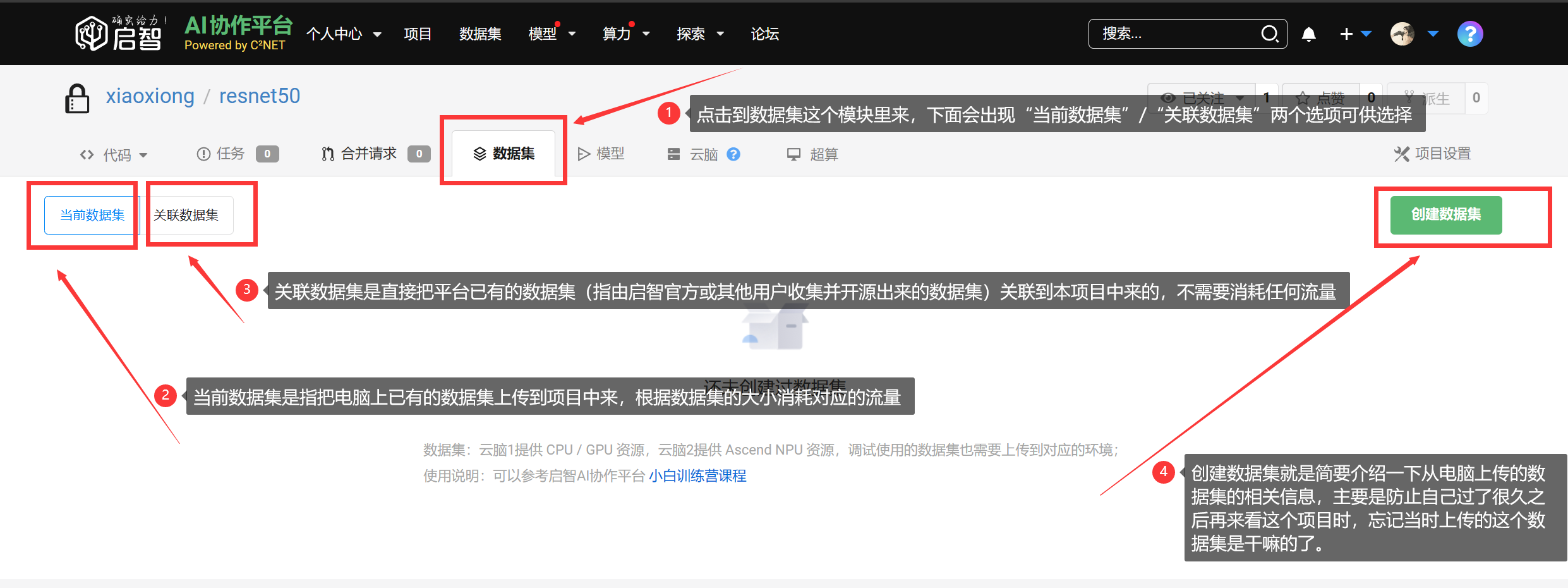
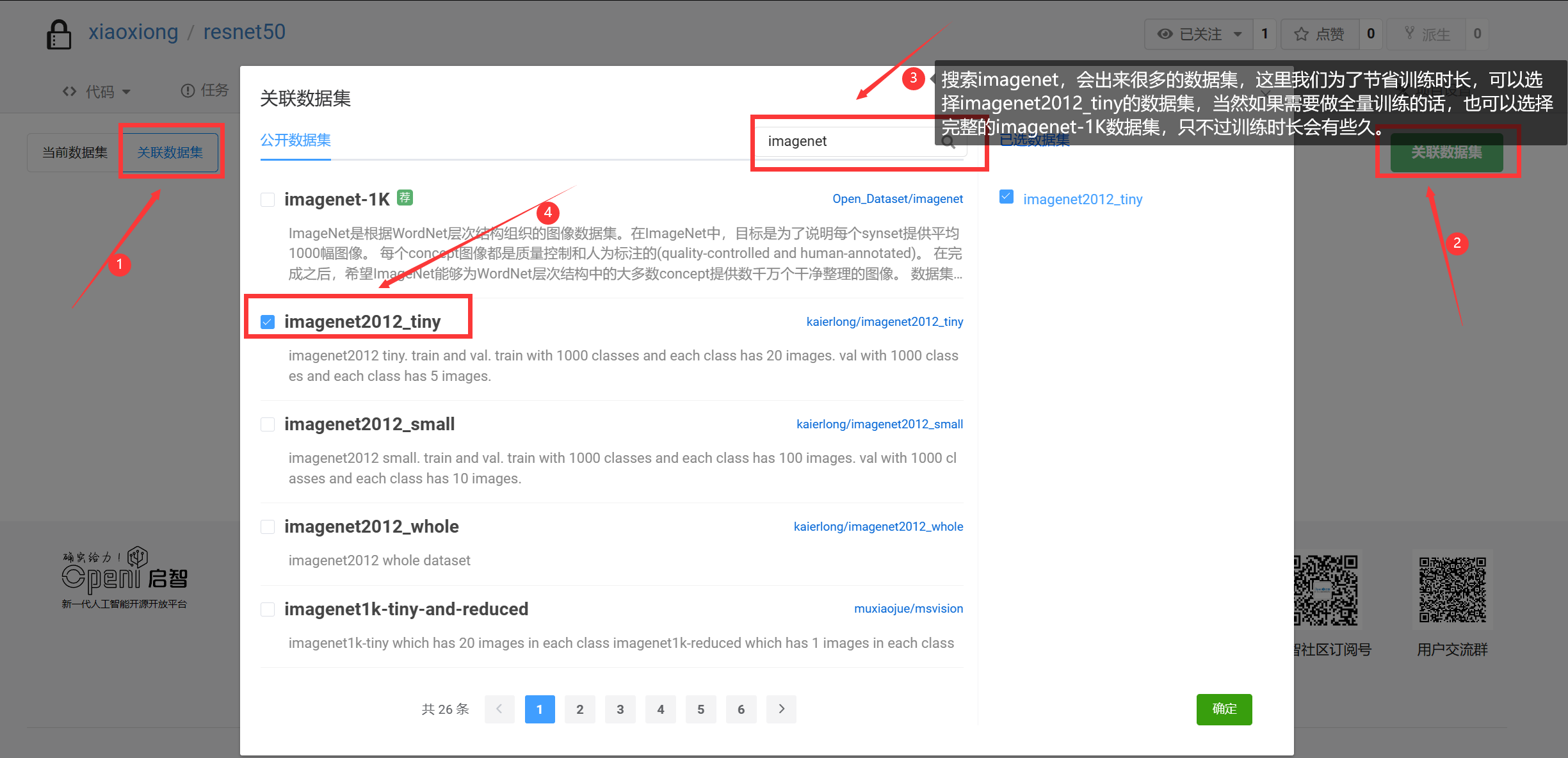
这里我们选择点击关联数据集,然后按下图的操作顺序进行,最后点击确定。
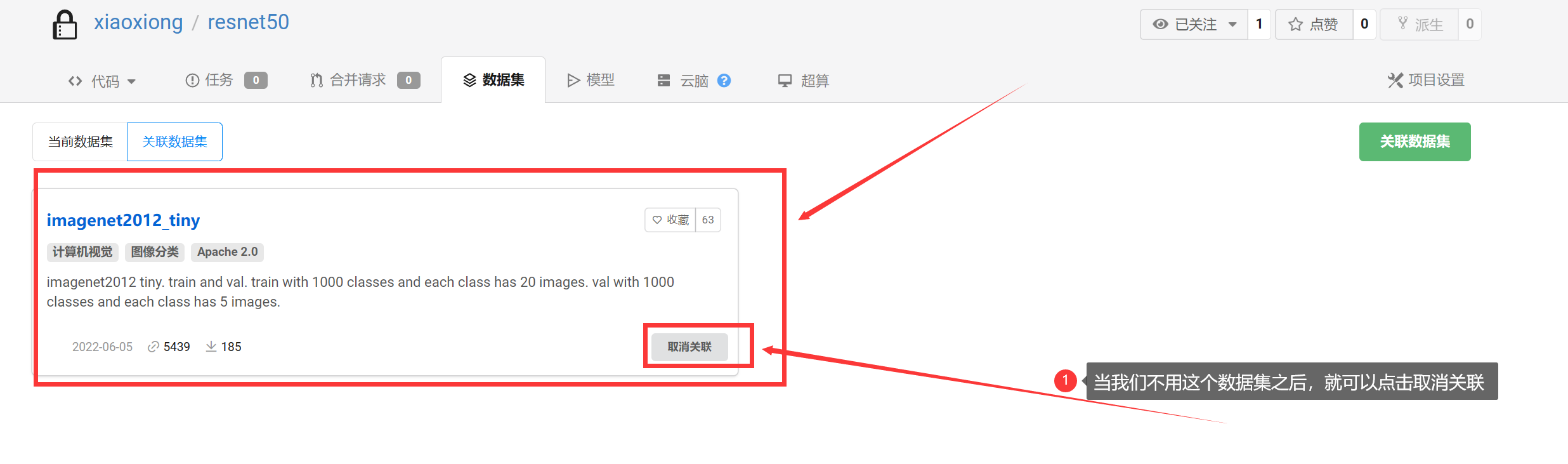
如下图所示,数据集就关联好了
五、创建任务
这里点击云脑之后,下面会出现5个任务类型可供选择。

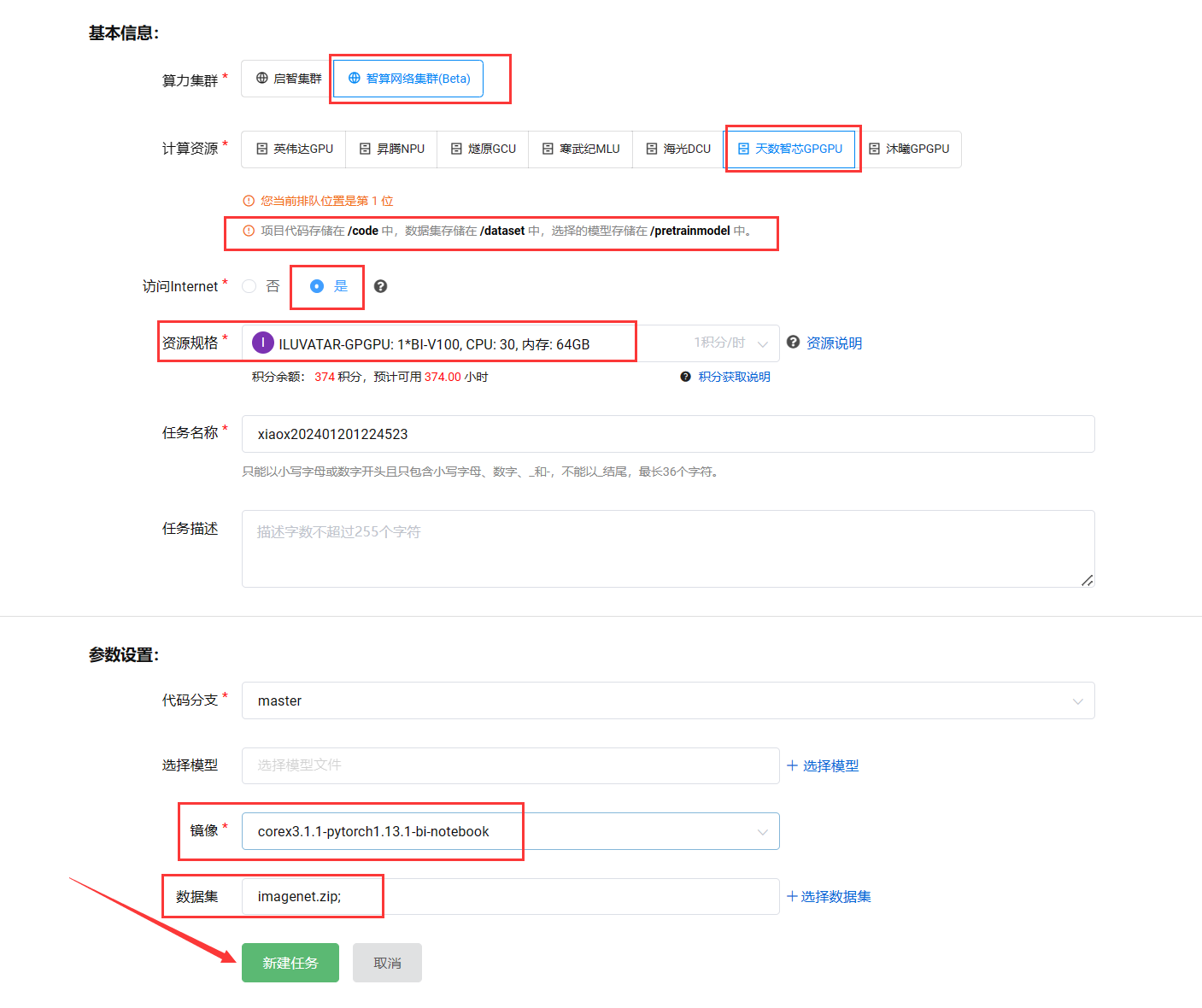
首先新建一个云脑调试任务,填入以下参数来配置你的调试环境:
-
算力集群 选择 智算集群
-
计算资源 选择 **天数智芯GPGPU **
-
访问Internet 选择 是
-
资源规格 提供
BI-V100(天垓100训练卡)和MR-V100(智铠100推理卡)算力卡,**这里我们选择 BI-V100。**如果是做推理调试,请选择 MR-V100资源。 -
任务名称 只能包含小写字母,数字,以及下划线与连接号(默认)
-
代码分支 此选项将在决定后台导入调试环境的代码仓分支(默认)
-
选择模型 可加载本项目中已导入的模型文件(一般是做模型的断点续训或者llm微调时导入,这里我们默认不导入)
-
镜像 只能选择平台提供
corex3.1.1-pytorch1.13.1-bi-notebook(这个是天垓100),corex3.2.0-pytorch1.13.1-mr-notebook(这个是智铠100) 镜像,不可生成自定义镜像,这里我们选择天垓100的镜像环境 -
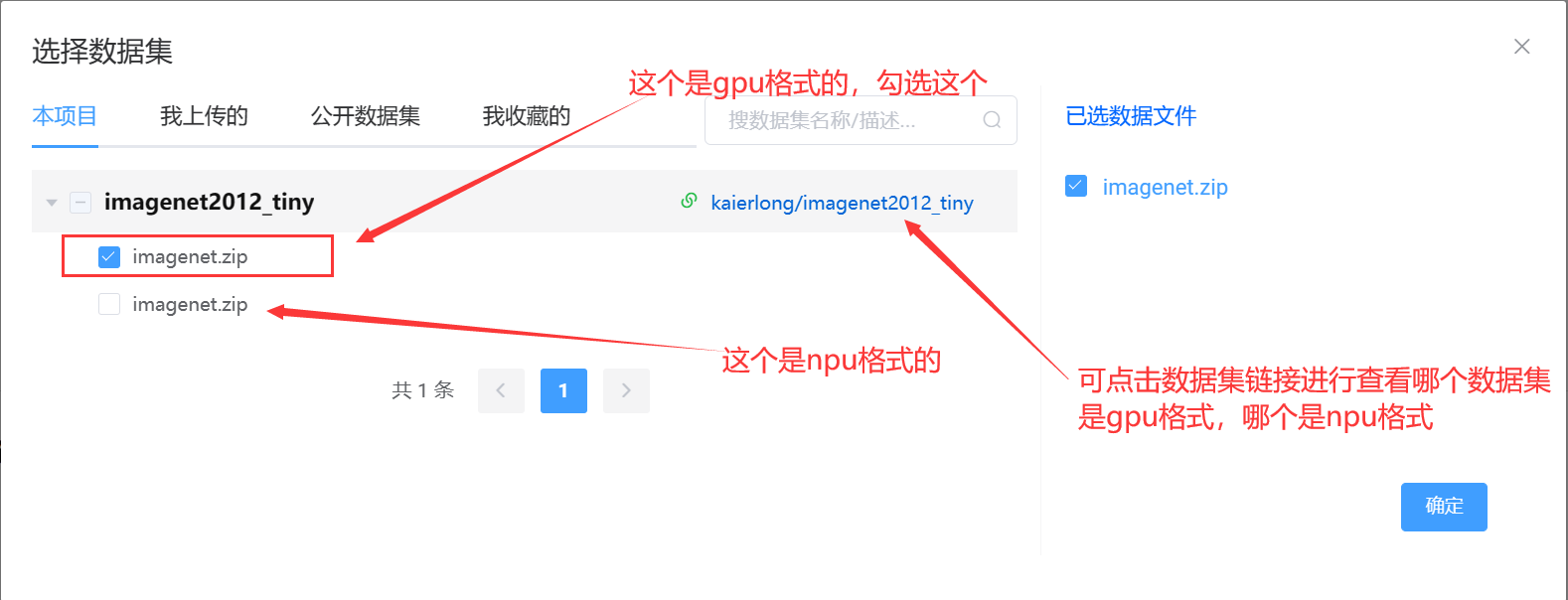
数据集:
- 若不使用数据集,可空白
- 数据集可多选,在弹窗中选中多个数据集即可,总大小不能超过 20G
- 这里我们选择第一个imagenet数据集,因为第二个同名的数据集是为华为npu准备的,如下图所示
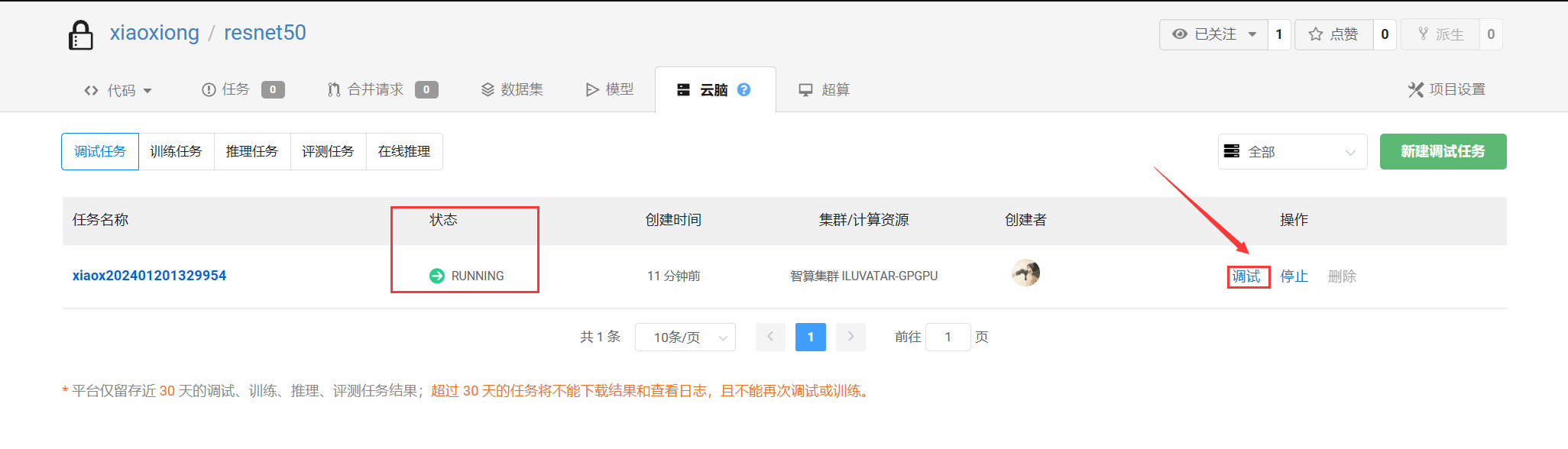
等待大约10分钟的环境加载,当状态栏的WAITING变为RUNNING时,即可点击调试按钮进行调试
六、模型训练
很快就进入了我们熟悉的jupyter lab界面,这里我们新建一个终端,然后通过git克隆DeepSparkHub这个仓库,**DeepSparkHub百大模型库是天数智芯主导的DeepSpark开源社区的核心项目,甄选了200+应用算法和模型,覆盖AI和通用计算各领域,支持主流深度学习框架包括PyTorch、TensorFlow、PaddlePaddle、MindSpore,每个模型均包括模型指导文档和运行代码,从DeepSparkHub能够获取到可在天数智芯GPGPU运行的最新开源模型,并通过启智社区的天数智芯算力资源进行调试。**DeepSparkHub目前仅适配训练模型,用于天垓100,近期将上线推理模型。
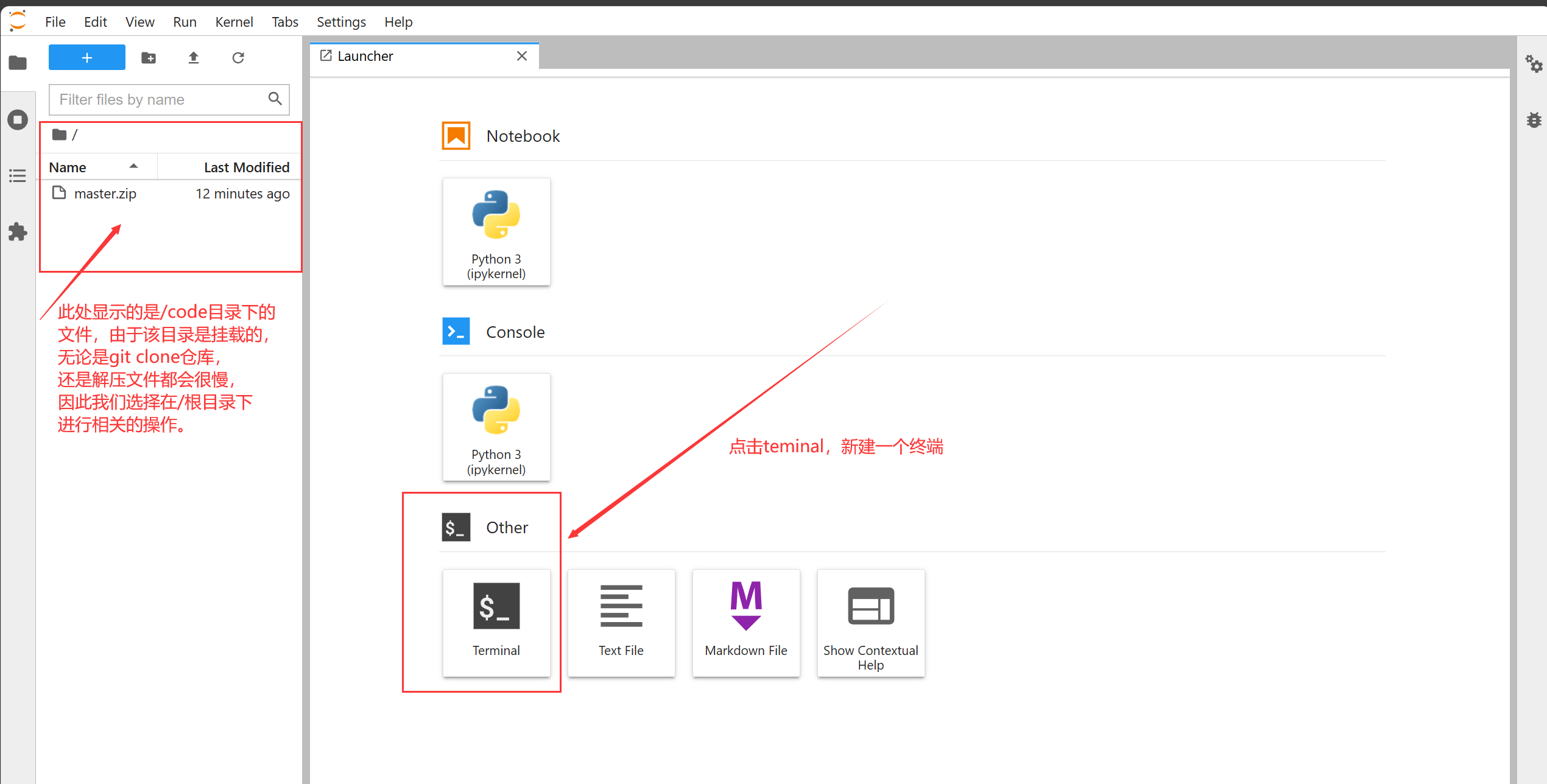
然后执行以下指令安装git
# 从sh切换到bash
bash
# 进入根目录/
cd /
# 安装git
apt install git -y
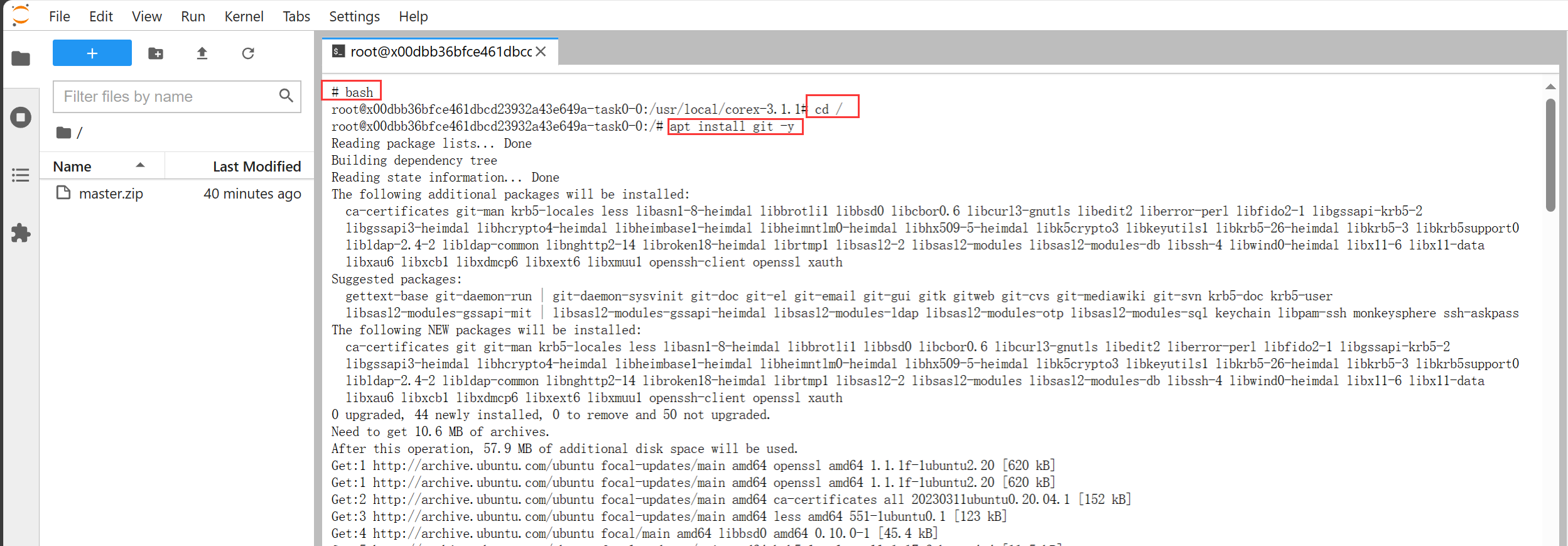
安装完git后,即可克隆DeepSparkHub百大模型库
# 克隆DeepSparkHub百大模型库
git clone https://openi.pcl.ac.cn/DeepSpark/DeepSparkHub.git
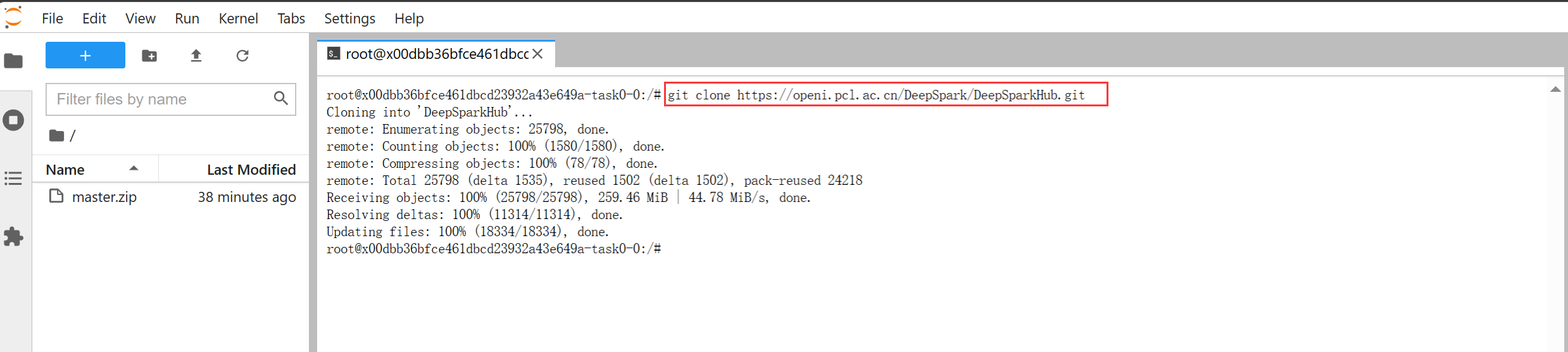
接下来打开DeepSparkHub百大模型库项目地址,查看resnet50模型的训练教程:https://openi.pcl.ac.cn/DeepSpark/DeepSparkHub
打开项目后我们在Computer Vision(计算机视觉)的子目录Classification(图像分类)中找到resnet50的pytorch框架的训练教程。
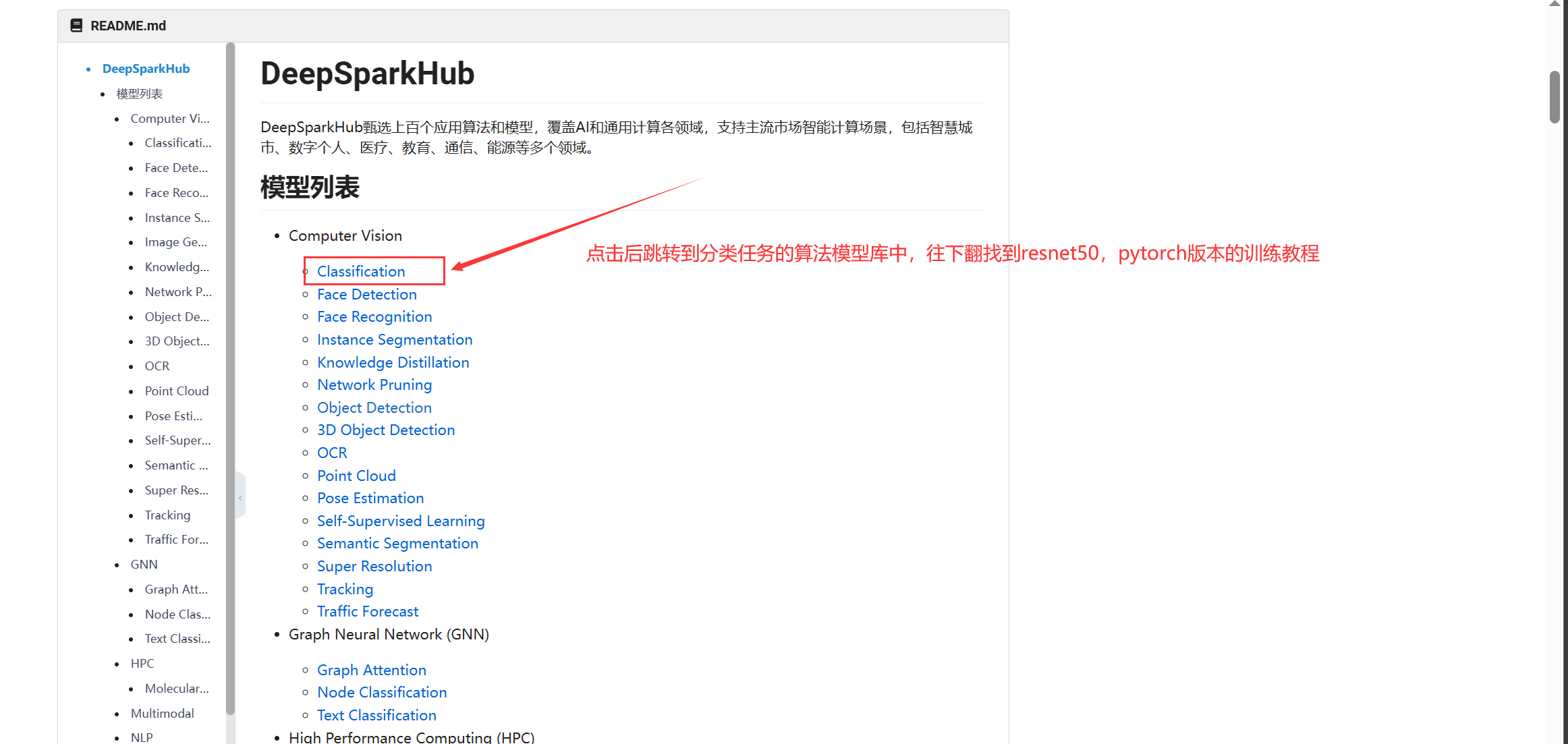
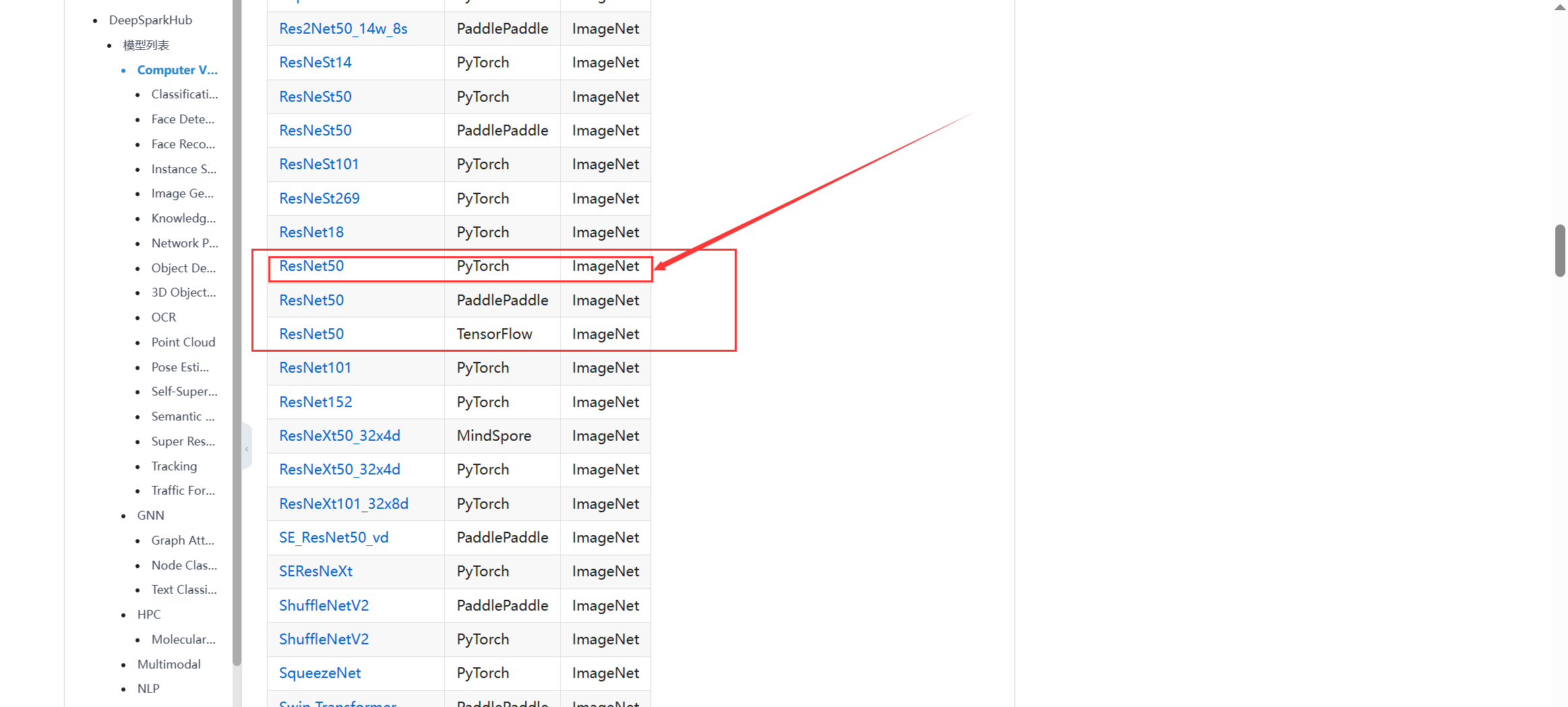
在这里,我们能看到非常简介明了的训练教程。
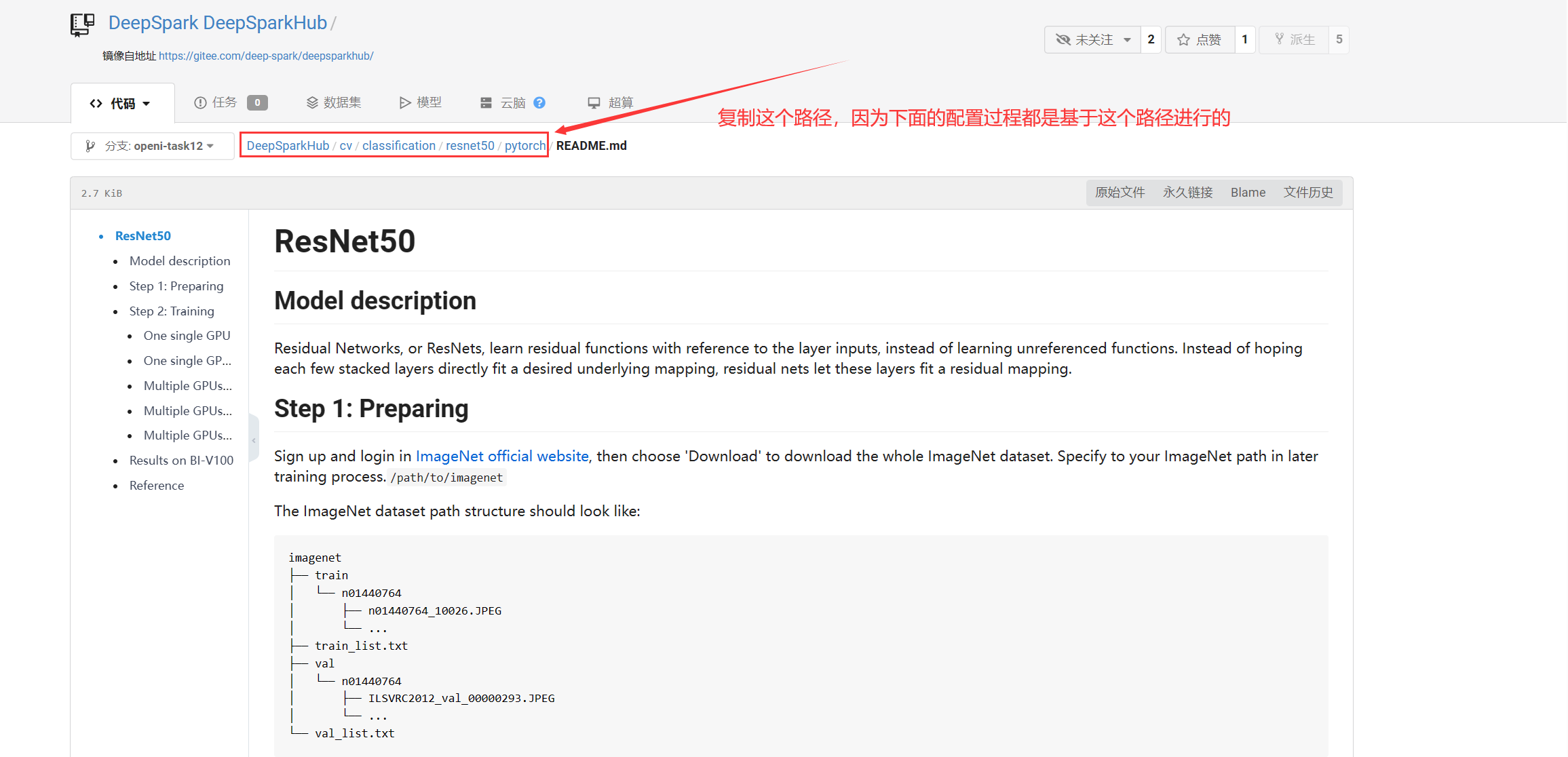
回到我们的jupyter lab界面进行下面的操作
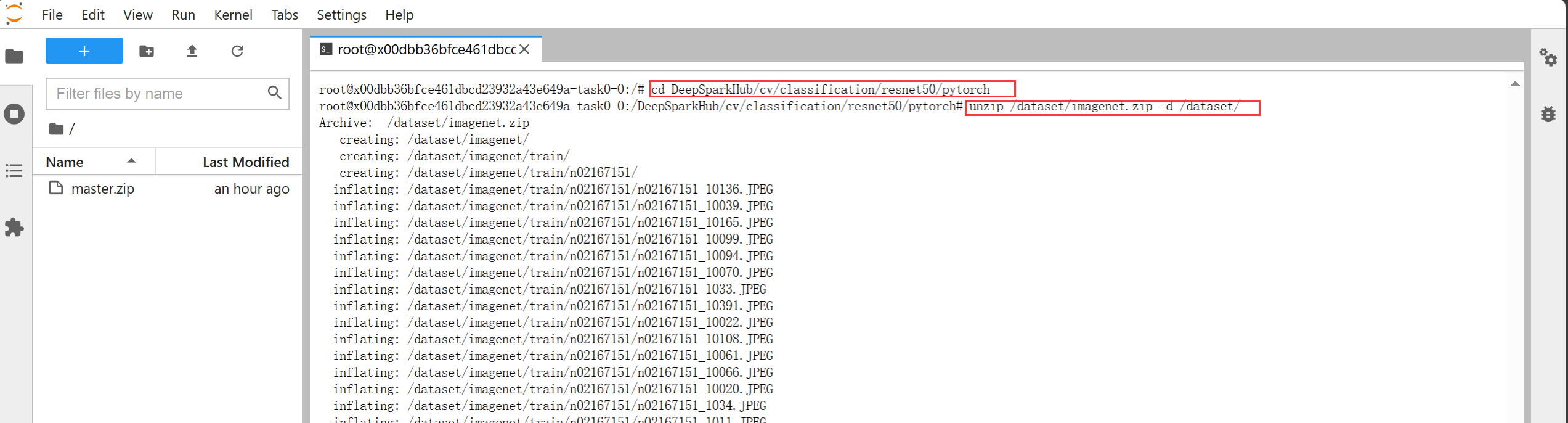
# 进入模型的训练目录
cd DeepSparkHub
cd cv/classification/resnet50/pytorch
# 解压imagenet数据集到/dataset目录下
unzip /dataset/imagenet.zip -d /dataset/
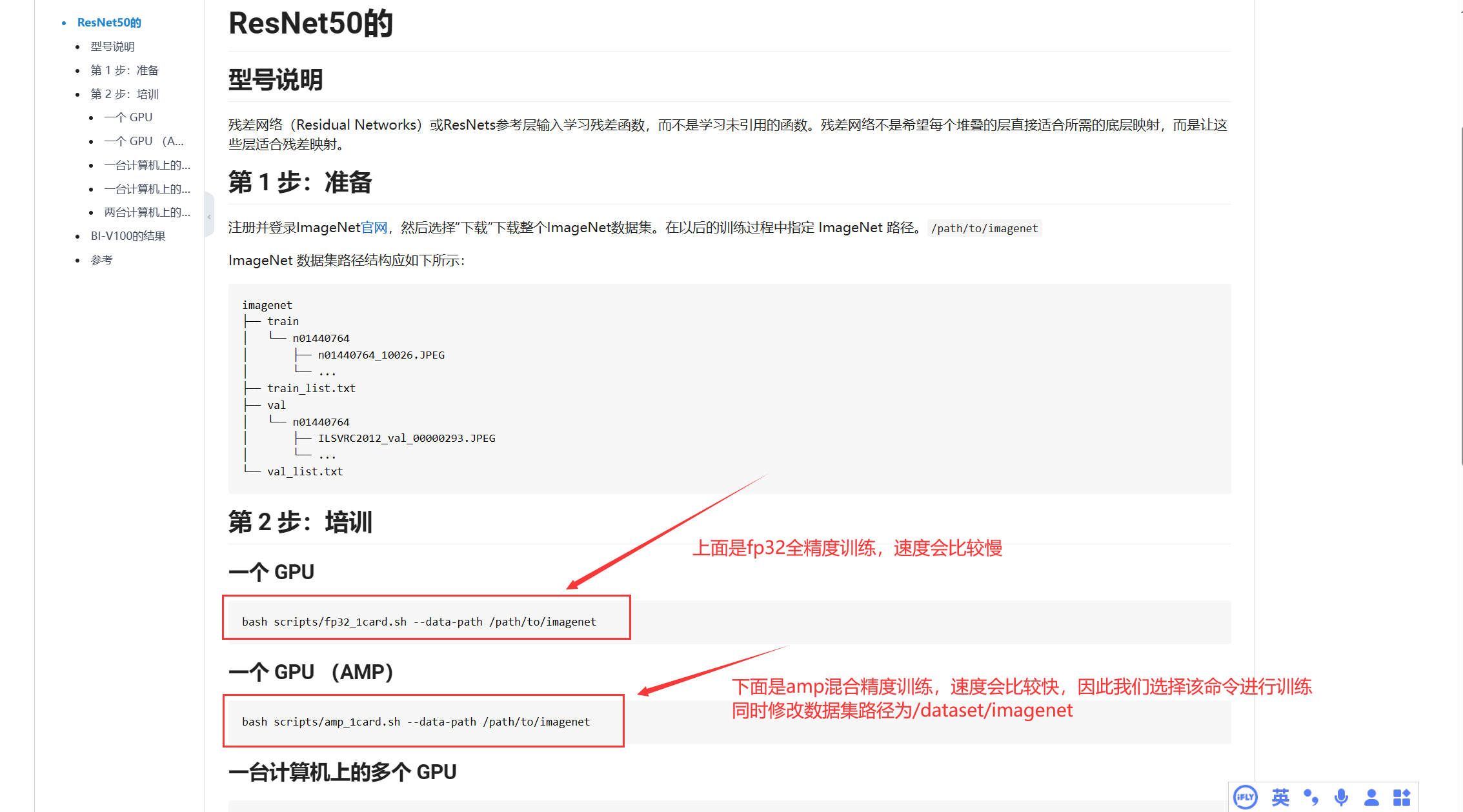
继续查看教程,选择amp混合精度训练模式,加快训练速度,同时将数据集路径更换为/dataset/imagenet
回到我们的jupyter lab界面,一键开启模型训练过程
# 安装libopenblas-dev库依赖
apt install libopenblas-dev -y
ldconfig
export LD_LIBRARY_PATH=/path/to/openblas/lib:$LD_LIBRARY_PATH
# amp混合精度训练
bash scripts/amp_1card.sh --data-path /dataset/imagenet

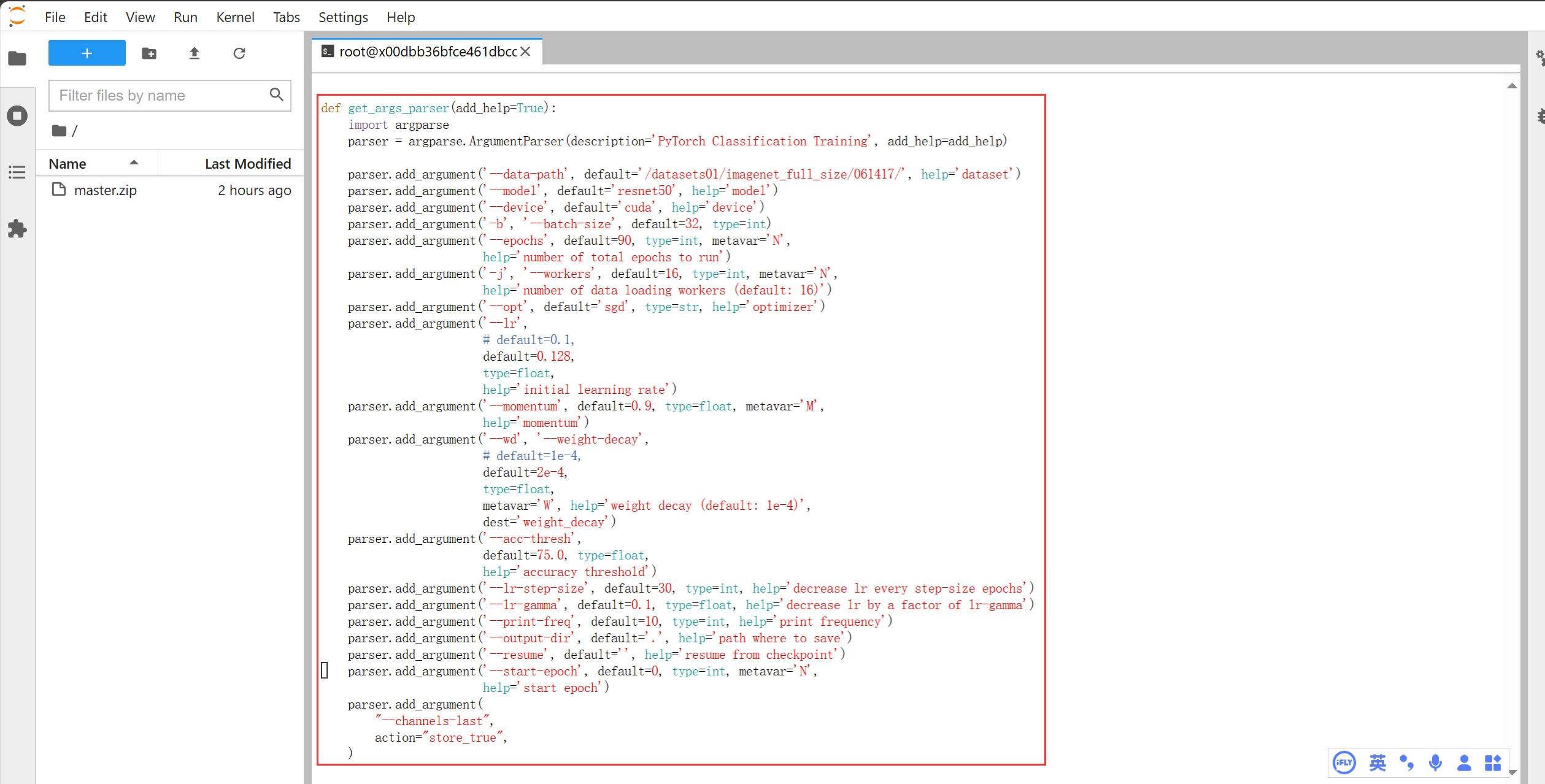
至此我们就完成了模型的训练过程,为了更好的调整超参数,我们通过vim去修改相关的超参数
# 可以在这里修改-b(批大小),--epochs(训练轮数),-j(多线程),--opt(优化器),--lr(学习率)等等超参数
# vim有两种模式:普通模式(点击esc进入,不可修改文本内容,只能浏览查看文本内容);插入模式(点击i进入,此时可以修改文本内容)。
# 当修改完文本后,点击esc进入普通模式,输入`shift`+`:`,然后再输入wq保存退出。
# 若想了解更多vim的使用教程可以去b站搜索相关视频教程进行学习
vim train.py
# 也可以通过在bash命令后添加相关的参数来进行修改,如:
bash scripts/amp_1card.sh --data-path /dataset/imagenet -b xx --epochs xx -j xx --opt xx --lr xx ....
模型的默认保存路径为/DeepSparkHub/cv/classification/resnet50/pytorch/results,可在超参数中进行修改,或者直接通过以下命令复制到/code目录下,便于调试结束前将训练好的模型下载到本地
# 将训练好的模型复制到/code目录下
cp results/resnet50_300_0.128_True_True_sgd/ /code/ -r

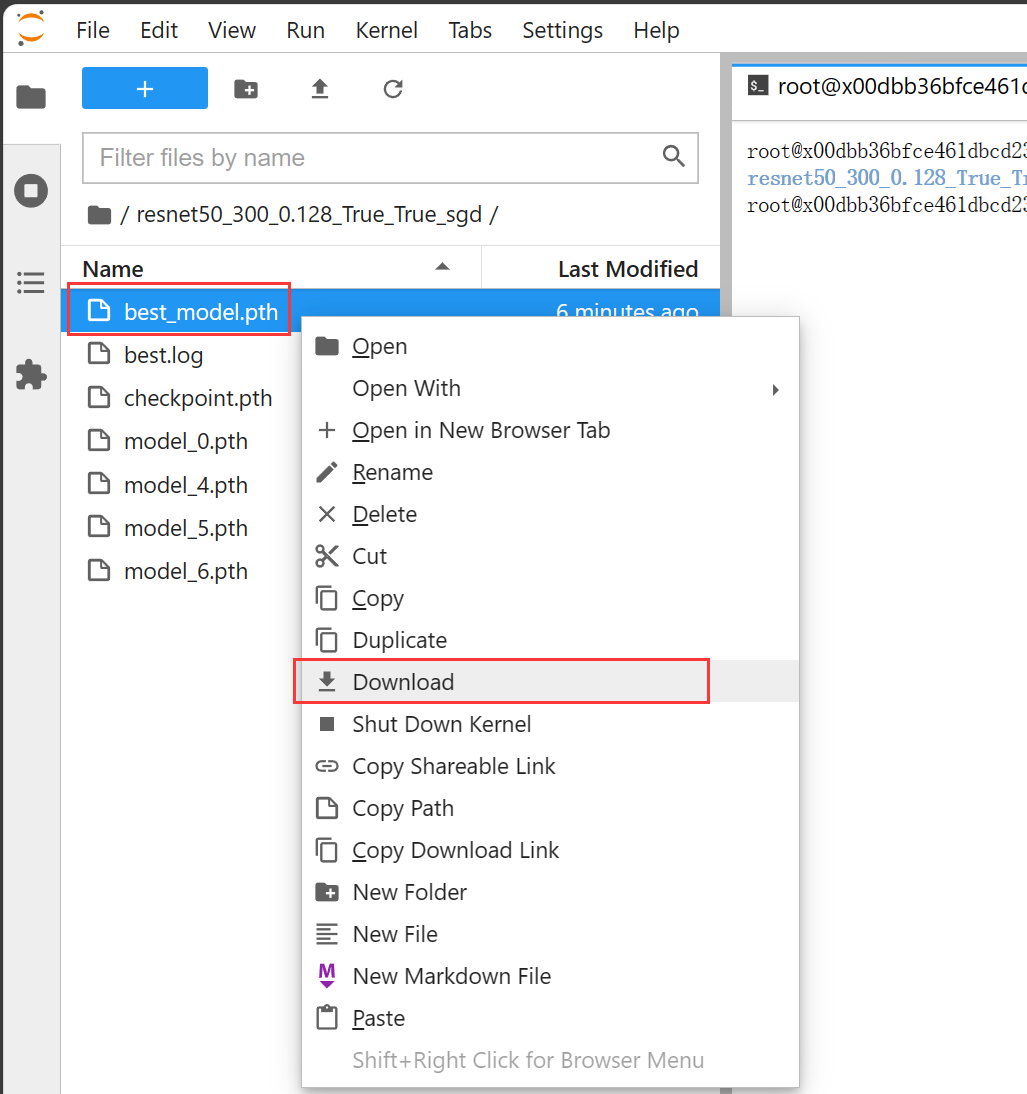
点击进入resnet50的模型保存目录,右键best_model.pth选择Download,将训练好的模型下载到本地
七、使用总结
以上就是启智社区天垓调试任务的全部使用教程了,大家如果还有什么问题,也可以在项目任务栏中附上自己遇到问题的图文,
或者扫描下方微信二维码进入天数智芯交流群。

或者直接反馈至天数智芯官方邮箱:Support.TSC@iluvatar.com
此外,大家如果还想了解更多启智平台的玩法,可以访问OpenI新手指南:https://openi.pcl.ac.cn/zeizei/OpenI_Learning
