

Are you sure you want to delete this task? Once this task is deleted, it cannot be recovered.
You can not select more than 25 topics
Topics must start with a chinese character,a letter or number, can include dashes ('-') and can be up to 35 characters long.
 KeyK
9c2fbfe069
KeyK
9c2fbfe069
|
1 year ago | |
|---|---|---|
| DATA/paddle-weight | 1 year ago | |
| base_model | 1 year ago | |
| datasets | 1 year ago | |
| engine | 1 year ago | |
| log | 1 year ago | |
| models | 1 year ago | |
| seg_opr | 1 year ago | |
| utils | 1 year ago | |
| .gitignore | 1 year ago | |
| LICENSE | 1 year ago | |
| README.md | 1 year ago | |
| city_dataloader.py | 1 year ago | |
| city_eval.py | 1 year ago | |
| config.py | 1 year ago | |
| custom_collate.py | 1 year ago | |
| eval.py | 1 year ago | |
| mask_gen.py | 1 year ago | |
| network.py | 1 year ago | |
| train.py | 1 year ago | |
README.md
Paddle复现CPS: 基于交叉伪监督的半监督语义分割
1. CPS半监督语义分割简介
- 参考代码:TorchSemiSeg
- 参考论文:Semi-Supervised Semantic Segmentation with Cross Pseudo Supervision
- CPS解读参考:[CVPR 2021] CPS: 基于交叉伪监督的半监督语义分割
1.1 背景
-
不同于图像分类任务,数据的标注对于语义分割任务来说是比较困难而且成本高昂的,需要为图像的每一个像素标注一个标签,包括一些特别细节的物体,如电线杆等。但是对于获取RGB数据是比较简单,如何利用大量的无标注数据去提高模型的性能,便是半监督语义分割领域研究的问题
-
作者为半监督语义分割任务设计了一种非常简洁而又性能很好的算法(cross pseudo supervision, CPS),训练时,使用两个相同结构、但是不同初始化的网络,添加约束使得两个网络对同一样本的输出是相似的。具体来说,当前网络产生的one-hot pseudo label,会作为另一路网络预测的目标,这个过程可以用cross entropy loss监督,就像传统的全监督语义分割任务的监督一样。该算法在在两个benchmark (PASCAL VOC, Cityscapes) 都取得了SOTA的结果。本项目复现的为在0.5倍Cityscapes数据集数据量上的结果
1.2 CPS算法
-
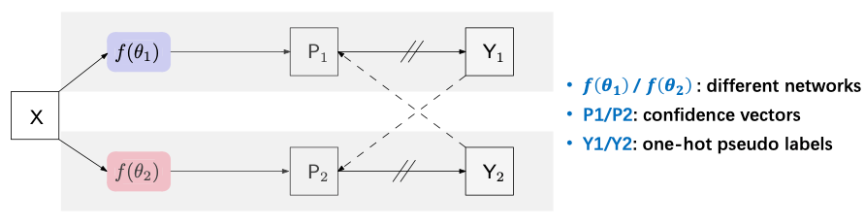
如上图所示,CPS的设计非常的简洁。训练时,使用两个网络$f(\theta_1)$ 和 $f(\theta_2)$。这样对于同一个输入图像X,可以有两个不同的输出P1和P2。通过argmax操作得到对应的one-hot标签Y1和Y2。类似于self-training中的操作,将这两个伪标签作为监督信号。例如用Y2作为P1的监督,Y1作为P2的监督,并用cross entropy loss约束
-
对于这两个网络,使用相同的结构,例如DeepLabV3+,但是不同的初始化。使用kaiming_normal进行两次随机初始化,而没有对初始化的分布做特定的约束。当然了,如果设计特定的初始化,没准CPS的效果会更好
-
在测试的时候,只使用其中一个网络进行inference,所以不增加任何测试/部署时候的开销
2. 复现结果
- 对于Cityscapes数据集,论文使用8张V100进行CPS模型的训练,每张卡的batch size为1,total batch size为8。由于AI studio脚本任务只能开4卡,复现的每张卡batch size为2,total batch size也为8。复现结果如下表所示
| CPS.resnet50.deeplabv3+(1/2 Cityscapes) | mIOU |
|---|---|
| pytorch | 78.77% |
| paddle | 78.28% |
注:复现是没有完全按照论文所用的8卡训练,同时CPS的训练不太稳定,相同复现代码,我进行3次训练,不同次数之间的best mIOU的差距能到1% ,源代码的issue中也有人反馈使用源码训练达不到论文精度,本项目使用Paddle复现,mIOU差距在0.49%,算是波动范围内。复现的log文件在log文件夹下
- 部分可视化结果如下,左边为RGB图像,中间为预测图,右边为真值
3. 数据准备
- 使用CPS源代码所提供的Cityscapes数据集,已上传至AI Studio,使用以下命令将数据解压至
PDSeg-SemiSeg/DATA文件夹下 - 同时,backbone的预训练权重也已经上传至AI Studio,将数据集中的
resnet50_v1c.pdparams权重下载,放置在PDSeg-SemiSeg/DATA/paddle-weight文件夹下,准备好的数据组织如下所示
DATA/
|-- city
|-- paddle-weight
| |-- resnet50_v1c.pdparams
- 解压数据集到指定文件夹
unzip -qo data/data177911/city.zip -d ./PDSeg-SemiSeg/DATA
cd PDSeg-SemiSeg/
4. 模型训练
- 配置文件为
config.py,模型网络与优化器等参数已设置好,数据读取的.txt文件也已事先准备好,复现不需要进行修改 - 本项目复现的结果为1/2数据量的Cityscapes数据集,若训练其他数据量,只需修改两个变量即可
C.labeled_ratio = 2
C.nepochs = 240
- 数据量和训练epochs的关系如下表所示
| Dataset | 1/16 | 1/8 | 1/4 | 1/2 |
|---|---|---|---|---|
| Cityscapes | 128 | 137 | 160 | 240 |
- 复现的训练是使用单机四卡的脚本任务进行,notebook的单卡环境无法满足训练需求,此处只说明启动多卡训练的命令,脚本任务链接CPS半监督语义分割-City数据集
python -m paddle.distributed.launch train.py
注:config.py文件中文件夹的设置为脚本任务的设置,若在本地使用单机多卡训练,修改以下参数
C.volna = '/root/paddlejob/workspace/PDSeg-SemiSeg/'
C.log_dir = '/root/paddlejob/workspace/output/log'
C.snapshot_dir = osp.join('/root/paddlejob/workspace/output', 'snapshot')
5. 模型测试
- 模型训练好之后,通过
eval.py脚本对指定的权重在Cityscapes test数据集上进行测试,最优权重已上传至AI Studio,执行以下命令进行测试并保存预测图像
python eval.py -e ../data/data185470/epoch-last.pdparams --save_path ../work/test_results
- 测试的日志文件保存在
PDSeg-SemiSeg/log文件夹下,mIOU为78.281%,可以直接使用AI Studio项目Paddle复现CPS: 基于交叉伪监督的半监督语义分割体验
基于PaddlePaddle框架,对CPS半监督语义分割方法进行复现。所用模型为ResNet50为backbone的deeeplabv3+,在0.5倍cityspace数据量下半监督学习,mIOU达到78.281%
Python Unity3D Asset
MIT-advertising
Contributors (1)
