










Are you sure you want to delete this task? Once this task is deleted, it cannot be recovered.
You can not select more than 25 topics
Topics must start with a chinese character,a letter or number, can include dashes ('-') and can be up to 35 characters long.
 黄世宇
0d0a8a8358
黄世宇
0d0a8a8358
|
7 months ago | |
|---|---|---|
| .github | 11 months ago | |
| docker | 11 months ago | |
| docs | 7 months ago | |
| examples | 7 months ago | |
| openrl | 7 months ago | |
| scripts | 7 months ago | |
| tests | 7 months ago | |
| .dockerignore | 11 months ago | |
| .gitignore | 7 months ago | |
| CONTRIBUTING.md | 11 months ago | |
| Gallery.md | 7 months ago | |
| LICENSE | 11 months ago | |
| Makefile | 7 months ago | |
| Project.md | 11 months ago | |
| README.md | 7 months ago | |
| README_en.md | 11 months ago | |
| README_zh.md | 7 months ago | |
| pytest.ini | 11 months ago | |
| setup.py | 7 months ago | |
README.md




![]()
![]()
![]()
OpenRL-v0.1.7 is updated on Sep 21, 2023
The main branch is the latest version of OpenRL, which is under active development. If you just want to have a try with
OpenRL, you can switch to the stable branch.
Welcome to OpenRL
Documentation | 中文介绍 | 中文文档
Crafting Reinforcement Learning Frameworks with Passion, Your Valuable Insights Welcome.
OpenRL is an open-source general reinforcement learning research framework that supports training for various tasks
such as single-agent, multi-agent, offline RL, self-play, and natural language.
Developed based on PyTorch, the goal of OpenRL is to provide a simple-to-use, flexible, efficient and sustainable
platform for the reinforcement learning research community.
Currently, the features supported by OpenRL include:
-
A simple-to-use universal interface that supports training for all tasks/environments
-
Support for both single-agent and multi-agent tasks
-
Support for offline RL training with expert dataset
-
Support self-play training
-
Reinforcement learning training support for natural language tasks (such as dialogue)
-
Support Arena , which allows convenient evaluation of
various agents (even submissions for JiDi) in a competitive environment. -
Importing models and datasets from Hugging Face. Supports loading Stable-baselines3 models from Hugging Face for testing and training.
-
Tutorial on how to integrate user-defined environments into OpenRL.
-
Support for models such as LSTM, GRU, Transformer etc.
-
Multiple training acceleration methods including automatic mixed precision training and data collecting wth half
precision policy network -
User-defined training models, reward models, training data and environment support
-
Support for gymnasium environments
-
Support for Callbacks, which can be used to
implement various functions such as logging, saving, and early stopping -
Dictionary observation space support
-
Popular visualization tools such
as wandb, tensorboardX are supported -
Serial or parallel environment training while ensuring consistent results in both modes
-
Chinese and English documentation
-
Provides unit testing and code coverage testing
-
Compliant with Black Code Style guidelines and type checking
Algorithms currently supported by OpenRL (for more details, please refer to Gallery):
- Proximal Policy Optimization (PPO)
- Dual-clip PPO
- Multi-agent PPO (MAPPO)
- Joint-ratio Policy Optimization (JRPO)
- Generative Adversarial Imitation Learning (GAIL)
- Behavior Cloning (BC)
- Advantage Actor-Critic (A2C)
- Self-Play
- Deep Q-Network (DQN)
- Multi-Agent Transformer (MAT)
- Value-Decomposition Network (VDN)
- Soft Actor Critic (SAC)
- Deep Deterministic Policy Gradient (DDPG)
Environments currently supported by OpenRL (for more details, please refer to Gallery):
- Gymnasium
- MuJoCo
- PettingZoo
- MPE
- Chat Bot
- Atari
- StarCraft II
- Omniverse Isaac Gym
- DeepMind Control
- Snake
- gym-pybullet-drones
- GridWorld
- Super Mario Bros
- Gym Retro
This framework has undergone multiple iterations by the OpenRL-Lab team which has
applied it in academic research.
It has now become a mature reinforcement learning framework.
OpenRL-Lab will continue to maintain and update OpenRL, and we welcome everyone to join
our open-source community
to contribute towards the development of reinforcement learning.
For more information about OpenRL, please refer to the documentation.
Outline
- Welcome to OpenRL
- Outline
- Why OpenRL?
- Installation
- Use Docker
- Quick Start
- Gallery
- Projects Using OpenRL
- Feedback and Contribution
- Maintainers
- Supporters
- Citing OpenRL
- License
- Acknowledgments
Why OpenRL
Here we provide a table for the comparison of OpenRL and existing popular RL libraries.
OpenRL employs a modular design and high-level abstraction, allowing users to accomplish training for various tasks
through a unified and user-friendly interface.
| Library | NLP/RLHF | Multi-agent | Self-Play Training | Offline RL | Bilingual Document |
|---|---|---|---|---|---|
| OpenRL | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| Stable Baselines3 | ❌ | ❌ | ❌ | ❌ | ❌ |
| Ray/RLlib | ❌ | ✔️ | ✔️ | ✔️ | ❌ |
| DI-engine | ❌ | ✔️ | not fullly supported | ✔️ | ✔️ |
| Tianshou | ❌ | not fullly supported | not fullly supported | ✔️ | ✔️ |
| MARLlib | ❌ | ✔️ | not fullly supported | ❌ | ❌ |
| MAPPO Benchmark | ❌ | ✔️ | ❌ | ❌ | ❌ |
| RL4LMs | ✔️ | ❌ | ❌ | ❌ | ❌ |
| trlx | ✔️ | ❌ | ❌ | ❌ | ❌ |
| trl | ✔️ | ❌ | ❌ | ❌ | ❌ |
| TimeChamber | ❌ | ❌ | ✔️ | ❌ | ❌ |
Installation
Users can directly install OpenRL via pip:
pip install openrl
If users are using Anaconda or Miniconda, they can also install OpenRL via conda:
conda install -c openrl openrl
Users who want to modify the source code can also install OpenRL from the source code:
git clone https://github.com/OpenRL-Lab/openrl.git && cd openrl
pip install -e .
After installation, users can check the version of OpenRL through command line:
openrl --version
Tips: No installation required, try OpenRL online through
Colab: ![]()
Use Docker
OpenRL currently provides Docker images with and without GPU support.
If the user's computer does not have an NVIDIA GPU, they can obtain an image without the GPU plugin using the following
command:
sudo docker pull openrllab/openrl-cpu
If the user wants to accelerate training with a GPU, they can obtain it using the following command:
sudo docker pull openrllab/openrl
After successfully pulling the image, users can run OpenRL's Docker image using the following commands:
# Without GPU acceleration
sudo docker run -it openrllab/openrl-cpu
# With GPU acceleration
sudo docker run -it --gpus all --net host openrllab/openrl
Once inside the Docker container, users can check OpenRL's version and then run test cases using these commands:
# Check OpenRL version in Docker container
openrl --version
# Run test case
openrl --mode train --env CartPole-v1
Quick Start
OpenRL provides a simple and easy-to-use interface for beginners in reinforcement learning.
Below is an example of using the PPO algorithm to train the CartPole environment:
# train_ppo.py
from openrl.envs.common import make
from openrl.modules.common import PPONet as Net
from openrl.runners.common import PPOAgent as Agent
env = make("CartPole-v1", env_num=9) # Create an environment and set the environment parallelism to 9.
net = Net(env) # Create neural network.
agent = Agent(net) # Initialize the agent.
agent.train(
total_time_steps=20000) # Start training and set the total number of steps to 20,000 for the running environment.
Training an agent using OpenRL only requires four simple steps:
Create Environment => Initialize Model => Initialize Agent => Start Training!
For a well-trained agent, users can also easily test the agent:
# train_ppo.py
from openrl.envs.common import make
from openrl.modules.common import PPONet as Net
from openrl.runners.common import PPOAgent as Agent
agent = Agent(Net(make("CartPole-v1", env_num=9))) # Initialize trainer.
agent.train(total_time_steps=20000)
# Create an environment for test, set the parallelism of the environment to 9, and set the rendering mode to group_human.
env = make("CartPole-v1", env_num=9, render_mode="group_human")
agent.set_env(env) # The agent requires an interactive environment.
obs, info = env.reset() # Initialize the environment to obtain initial observations and environmental information.
while True:
action, _ = agent.act(obs) # The agent predicts the next action based on environmental observations.
# The environment takes one step according to the action, obtains the next observation, reward, whether it ends and environmental information.
obs, r, done, info = env.step(action)
if any(done): break
env.close() # Close test environment
Executing the above code on a regular laptop only takes a few seconds
to complete the training. Below shows the visualization of the agent:
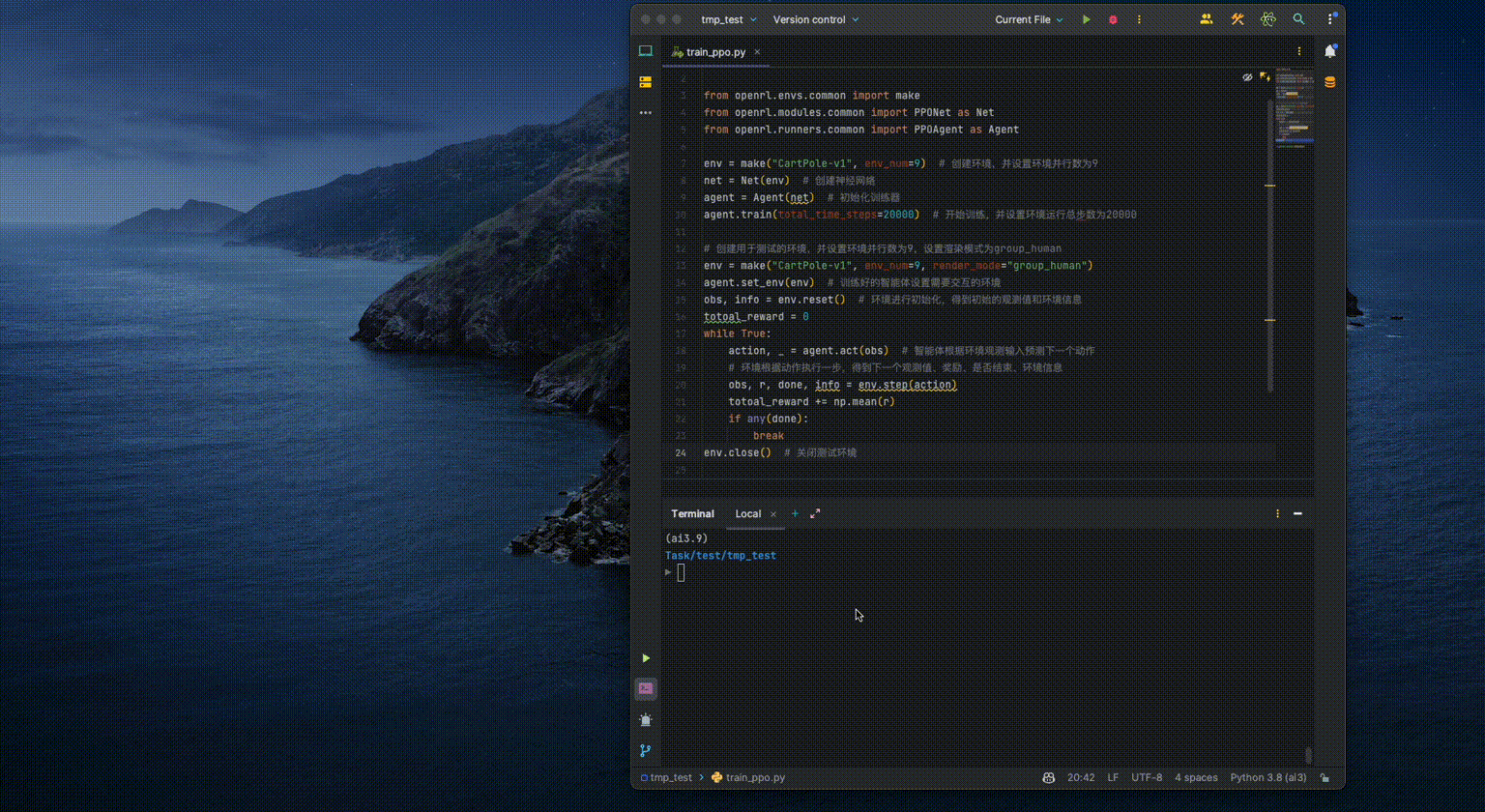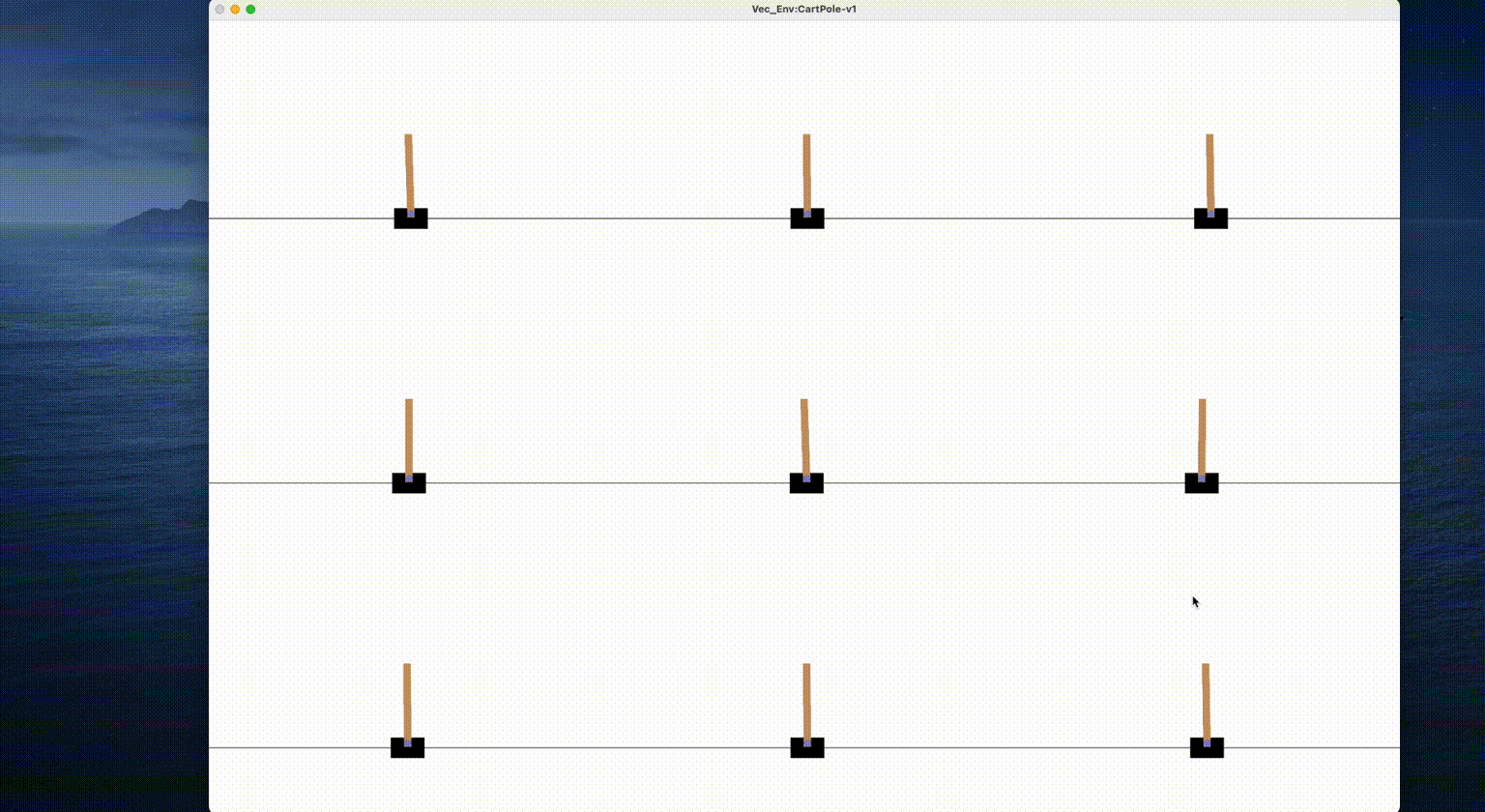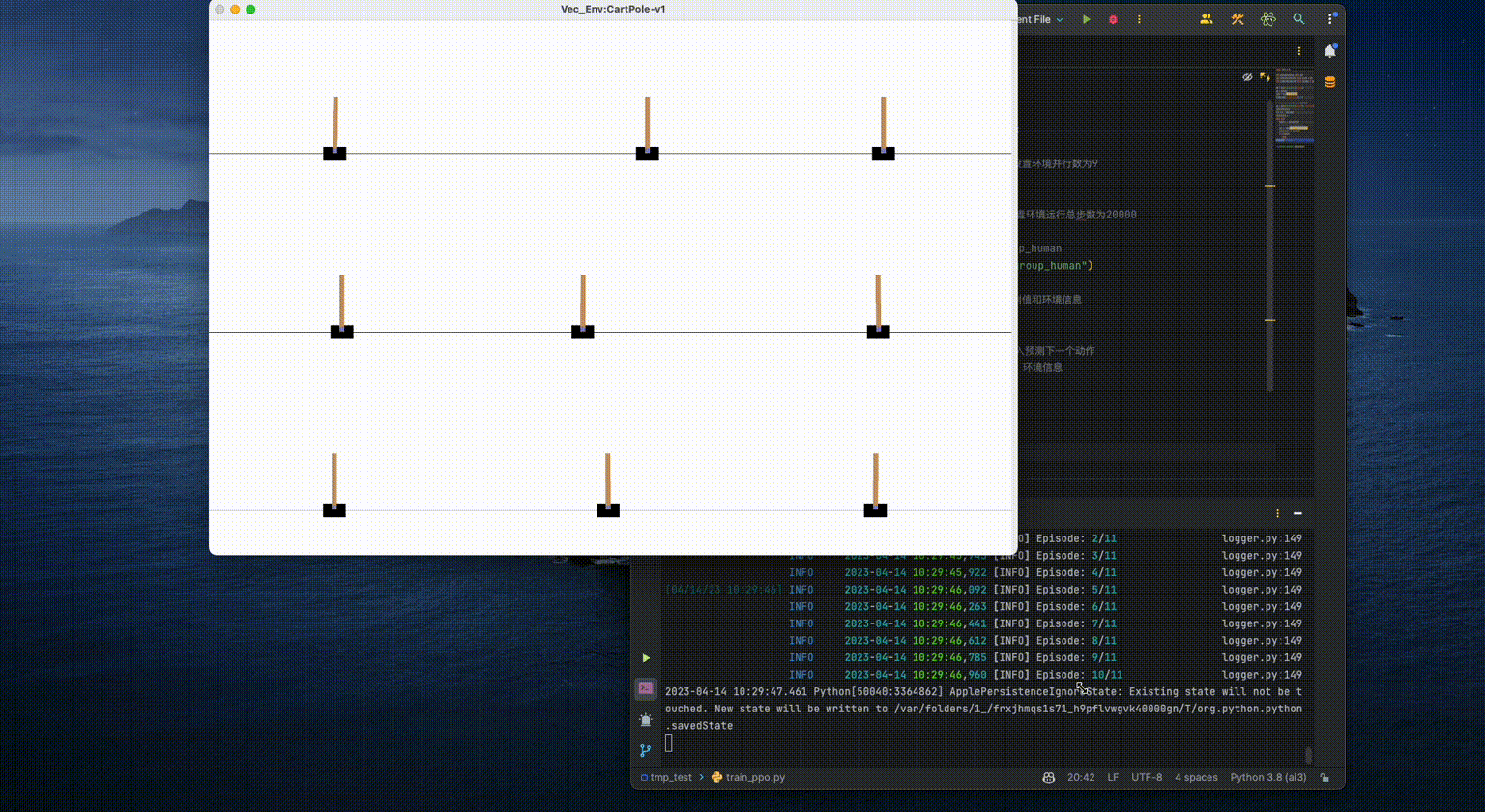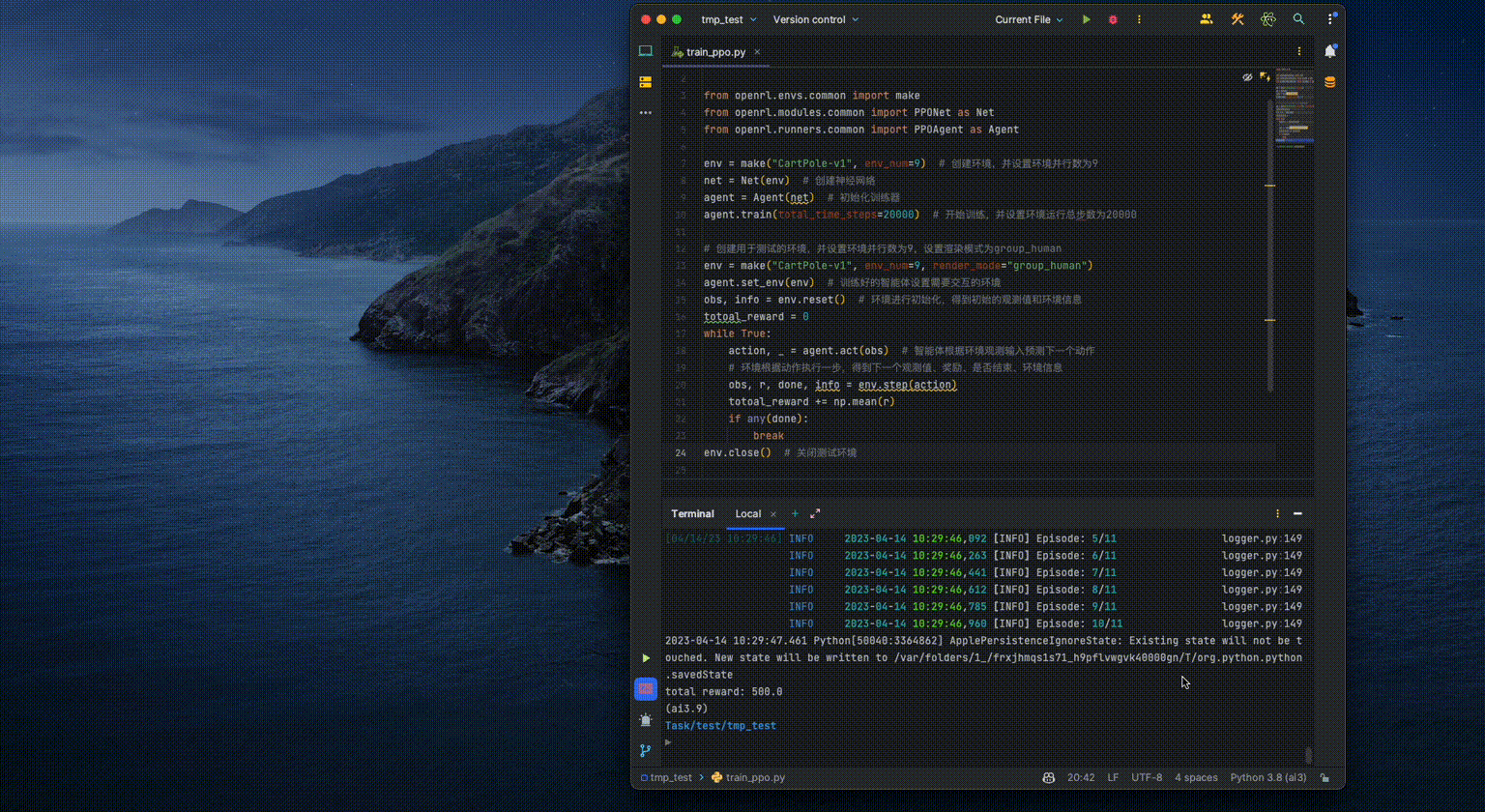
Tips: Users can also quickly train the CartPole environment by executing a command line in the terminal.
openrl --mode train --env CartPole-v1
For training tasks such as multi-agent and natural language processing, OpenRL also provides a similarly simple and
easy-to-use interface.
For information on how to perform multi-agent training, set hyperparameters for training, load training configurations,
use wandb, save GIF animations, etc., please refer to:
For information on natural language task training, loading models/datasets on Hugging Face, customizing training
models/reward models, etc., please refer to:
For more information about OpenRL, please refer to the documentation.
Gallery
In order to facilitate users' familiarity with the framework, we provide more examples and demos of using OpenRL
in Gallery.
Users are also welcome to contribute their own training examples and demos to the Gallery.
Projects Using OpenRL
We have listed research projects that use OpenRL in the OpenRL Project.
If you are using OpenRL in your research project, you are also welcome to join this list.
Feedback and Contribution
- If you have any questions or find bugs, you can check or ask in
the Issues. - Join the QQ group: OpenRL Official Communication Group

- Join the slack group to discuss
OpenRL usage and development with us. - Join the Discord group to discuss OpenRL usage and development with us.
- Send an E-mail to: huangshiyu@4paradigm.com
- Join the GitHub Discussion.
The OpenRL framework is still under continuous development and documentation.
We welcome you to join us in making this project better:
- How to contribute code: Read the Contributors' Guide
- OpenRL Roadmap
Maintainers
At present, OpenRL is maintained by the following maintainers:
- Shiyu Huang(@huangshiyu13)
- Wenze Chen(@Chen001117)
- Yiwen Sun(@YiwenAI)
Welcome more contributors to join our maintenance team (send an E-mail
to huangshiyu@4paradigm.com
to apply for joining the OpenRL team).
Supporters
↳ Contributors
↳ Stargazers
↳ Forkers
Citing OpenRL
If our work has been helpful to you, please feel free to cite us:
@misc{openrl2023,
title={OpenRL},
author={OpenRL Contributors},
publisher = {GitHub},
howpublished = {\url{https://github.com/OpenRL-Lab/openrl}},
year={2023},
}
Star History
License
OpenRL under the Apache 2.0 license.
Acknowledgments
The development of the OpenRL framework has drawn on the strengths of other reinforcement learning frameworks:
- Stable-baselines3: https://github.com/DLR-RM/stable-baselines3
- pytorch-a2c-ppo-acktr-gail: https://github.com/ikostrikov/pytorch-a2c-ppo-acktr-gail
- MAPPO: https://github.com/marlbenchmark/on-policy
- Gymnasium: https://github.com/Farama-Foundation/Gymnasium
- DI-engine: https://github.com/opendilab/DI-engine/
- Tianshou: https://github.com/thu-ml/tianshou
- RL4LMs: https://github.com/allenai/RL4LMs

{kind=link}