Are you sure you want to delete this task? Once this task is deleted, it cannot be recovered.
You can not select more than 25 topics
Topics must start with a chinese character,a letter or number, can include dashes ('-') and can be up to 35 characters long.
 zhangjunyi08
2713321b0f
zhangjunyi08
2713321b0f
|
1 year ago | |
|---|---|---|
| config | 1 year ago | |
| image | 1 year ago | |
| scripts | 1 year ago | |
| src | 1 year ago | |
| .gitignore | 1 year ago | |
| LICENSE | 1 year ago | |
| NOTICE | 1 year ago | |
| OWNERS | 1 year ago | |
| README.md | 1 year ago | |
| RELEASE.md | 1 year ago | |
| requirements.txt | 1 year ago | |
README.md
OPT
项目介绍
OPT(Omni-Perception Pre-Trainer)是全场景感知预训练模型的简称,是中科院自动化和华为在探索通用人工智能道路上的重要成果,并在2021年9月发布了全球首个图文音三模态千亿大模型,中文名字叫紫东.太初,本仓是紫东.太初十亿参数级别代码,软硬件采用全国产华为昇腾全栈,包含预训练模型及多个下游任务模型。多模态模型可从不同模态(语音、图片、文字等)的数据中训练学习,从而完成许多应用广泛的AI任务,紫东.太初的发布将改变当前单一模型对应单一任务的人工智能研发范式,实现三模态图文音的统一语义表达,在多模态内容的理解、搜索、推荐和问答,语音识别和合成,人机交互和无人驾驶等商业应用中具有潜力巨大的市场价值。
模型架构
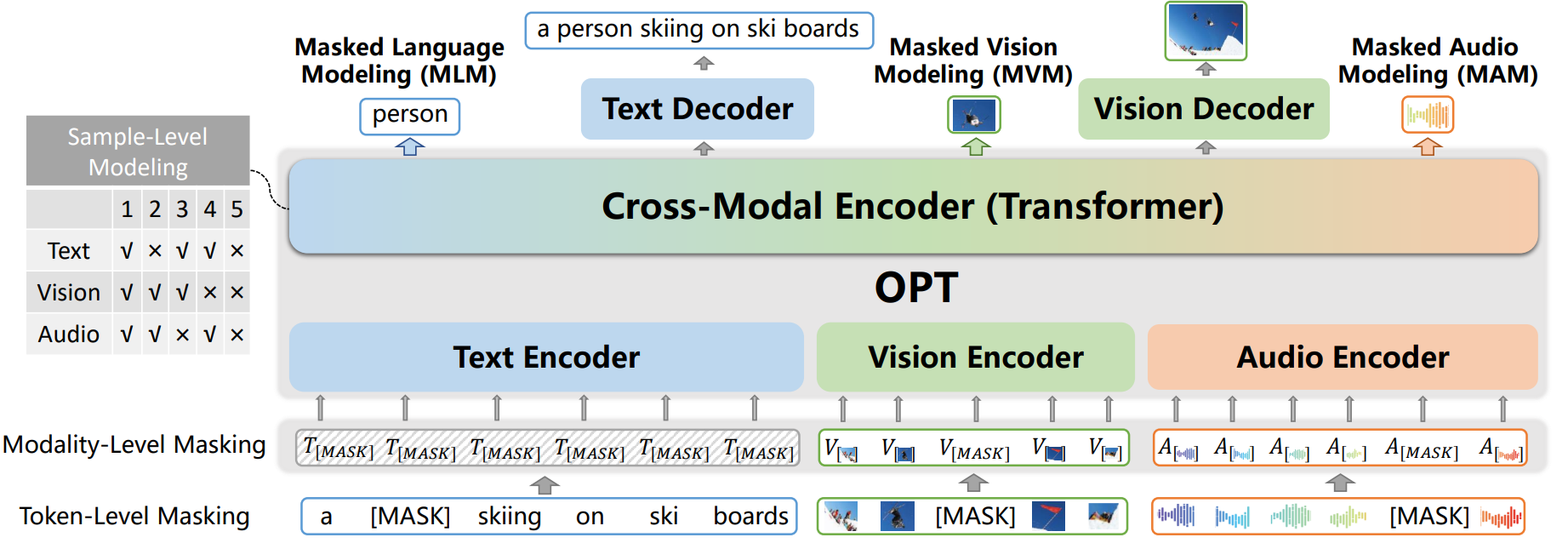
紫东太初的模型架构由特征提取模型、三个单模态编码器、一个跨模态编码器和两个跨模态解码器组成,并提出了三个级别的预训练任务:(1)Token级建模;(2) 模态级建模;(3) 样本级建模,详细内容可阅读论文了解,模型主体架构图如下:
环境安装
-
安装CANN 5.0.4
前往昇腾社区下载安装包:
https://www.hiascend.com/software/cann/commercial
以arm + 欧拉的系统配置为例( x86的系统请选择x86的包 )
安装驱动:
./A800-9000-npu-driver_21.0.4_linux-aarch64.run --full
安装固件:
./A800-9000-npu-firmware_1.80.22.2.220.run --full
安装cann-toolkit包:
./Ascend-cann-toolkit_5.0.4_linux-aarch64.run --full -
安装MindSpore 1.6.1版本
前往MindSpore官网,按照教程安装对应版本即可,当前为1.6.1,链接如下:
https://www.mindspore.cn/install -
安装requirements依赖
pip install -r requirements.txt
代码结构
├── config #配置文件
│ ├── caption #caption任务的配置文件
│ │ ├── cross_modal_encoder_base.json
│ │ └── ft_cap_base.json
│ └── ... #同上
├── image #代码仓图片
│ ├── frameworkimage.png
│ └── image_caption.png
├── scripts #预训练模型及下游任务训练/测试启动脚本
│ ├── pretrain.sh
│ ├── test_caption.sh
│ ├── test_retrieval.sh
│ ├── train_caption.sh
│ └── train_retrieval.sh
├── src #核心代码
│ ├── config #配置文件
│ ├── data #数据加载
│ ├── fastspeech2_mindspore #语音生成
│ ├── mae_mindspore #MAE代码
│ ├── model_mindspore #模型核心代码
│ ├── vqvae_mindspore #vqvae代码
│ ├── scripts #下游任务启动入口脚本
│ └── tools #工具
├── requirements.txt
├── LICENSE
├── OWNERS
└── README.md
下游任务
-
1. 文本生成(Image Caption)
任务简介:
Image Caption 顾名思义,即让算法根据输入的一幅图自动生成对应的描述性的文字,是图像理解中非常重要的基础任务。

数据集介绍:该数据集是COCO Caption的数据集,自动化所将标签从英文翻译为中文,该数据集的训练集包括11.3万张图像,每张图像有5条描述的中文标签,测试集有5千张图像,每张图像1条描述的中文标签。
数据集下载:
百度云盘链接:https://pan.baidu.com/s/1ECN5JXlRPQsBS8O763Y8pA
提取码:84me
解压至dataset/caption/路径下coco图片下载
http://images.cocodataset.org/zips/train2014.zip
http://images.cocodataset.org/zips/val2014.zip
解压至dataset/caption/img/mscoco/路径下预训练模型下载:
https://opt-release.obs.cn-central-221.ovaijisuan.com:443/model/OPT_1-38_136.ckpt
下载至model/caption/路径下启动训练:
单卡:
bash scripts/train_caption.sh
多卡:
bash scripts/train_caption_parallel.sh [DEVICE_NUM] [VISIABLE_DEVICES(0,1,2,3,4,5,6,7)] [RANK_TABLE_FILE]
(各项参数说明参考Mindspore官方文档)启动测试(需安装java1.8.0):
bash scripts/test_caption.sh启动推理:
bash scripts/inference_caption.sh
支持对单目录或列表的推理,需要修改脚本中的inference_dir和inference_list参数。
若存在inference_list则会读取list中的每项文件进行推理(文件目录为inference_dir拼接list中的文件名);
若inference_list为空则遍历inference_dir中的每个文件执行推理。模型导出:
python src/scripts/export_caption.py --ckpt_file="***.ckpt"
默认导出格式为MindIR,可通过file_format进行修改(目前由于框架限制,紫东太初模型仅支持导出MindIR)。效果展示:


-
2. 视觉问答(Visual Question Answer, VQA)
任务简介:
视觉问答是给定一幅图片和一个相关的问题,算法输出相应的答案,是多模态理解中的基础任务之一。数据集介绍:
该数据集是百度发布的中文VQA数据集Are You Talking to a Machine? Dataset and Methods for Multilingual Image Question Answering,图片来自于COCO,每张图片对应一到两个问题。数据集下载:
VQA数据集
http://research.baidu.com/Public/uploads/5ac9e10bdd572.gz
下载后将文件解压并重命名为FM-IQA.json,移动至dataset/vqa/txt/路径下coco图片
http://images.cocodataset.org/zips/train2014.zip
http://images.cocodataset.org/zips/val2014.zip
解压至dataset/vqa/img/mscoco/路径下词表
链接:https://pan.baidu.com/s/14FrOW7LMAwwDK5gfDS1BeA 提取码:j50u
下载后运行python src/tools/vqa/prepare_vqa_tokens.py 提取vqa问题和答案的token,将得到的文件放到dataset/vqa/路径下预训练模型下载:
https://opt-release.obs.cn-central-221.ovaijisuan.com:443/model/OPT_1-38_136.ckpt
下载至model/vqa/路径下启动训练:
单卡:
bash scripts/train_vqa.sh
多卡:
bash scripts/train_vqa_parallel.sh [DEVICE_NUM] [VISIABLE_DEVICES(0,1,2,3,4,5,6,7)] [RANK_TABLE_FILE]
(各项参数说明参考Mindspore官方文档)启动测试(需安装java1.8.0):
bash scripts/test_vqa.sh效果展示:


-
3. 跨模态检索(Cross-modal Retrieval)
任务简介:
跨模态检索是在不同模态之间进行数据的检索。
例如输入图片,在文本库中挑选出与图片内容最匹配的描述;输入描述,在图片库中挑出与这句描述内容最符合的图片。

数据集介绍:该数据集是COCO Caption的数据集,自动化所将标签从英文翻译为中文,该数据集的训练集包括12万张图像,每张图像有5条描述的中文标签,
选取了150图文对进行检索性能的测试。数据集下载:
链接:https://pan.baidu.com/s/1lArnJlPfkahcn5IZlgwJvQ 提取码:fdc8
解压至dataset/retrieval/路径下预训练模型下载:
https://opt-release.obs.cn-central-221.ovaijisuan.com:443/model/OPT_1-38_136.ckpt
下载至model/retrieval/路径下启动训练:
bash scripts/train_retrieval_parallel.sh [DEVICE_NUM] [VISIABLE_DEVICES(0,1,2,3,4,5,6,7)] [RANK_TABLE_FILE]
(各项参数说明参考Mindspore官方文档)启动测试(将test_retrieval.sh中的ckpt模型路径更换成自己训练的):
bash scripts/test_retrieval.sh评估结果:
| 输入尺寸 | IR @1 | IR @5 | IR @10 | TR @1 | TR @5 | TR @10 | |----------|--------|--------|--------|--------|--------|--------| | 448 | 70 | 96 | 98.7 | 64.67 | 93.33 | 98 | -
4. 语音合成(Text To Speech)
任务简介:
语音合成是输入文本输出语音。数据集介绍:该数据集是AISHELL3的数据集。AISHELL-3的语音时长为85小时88035句,可做为多说话人合成系统。录制过程在安静室内环境中,使用高保真麦克风(44.1kHz,16bit)。218名来自中国不同口音区域的发言人参与录制。专业语音校对人员进行拼音和韵律标注,并通过严格质量检验,此数据库音字确率在98%以上。
数据集下载:
链接:https://pan.baidu.com/s/1dt04CmP5v_EL_dUq8S8SVA 提取码:o8ja
解压至dataset/speech/路径下启动训练:
bash scripts/train_speech.sh启动测试(test_speech.sh中的ckpt模型路径更换成自己训练的):
bash scripts/test_speech.sh
模型创新
-
全球首个多模态图文音预训练大模型
-
多层次多任务自监督学习
-
弱关联多模态数据语义统一表达
-
兼顾任务感知和推理增强的中文预训练模型
-
多粒度学习与注意力指导的视觉预训练模型
-
基于自监督预训练的多任务语音建模技术
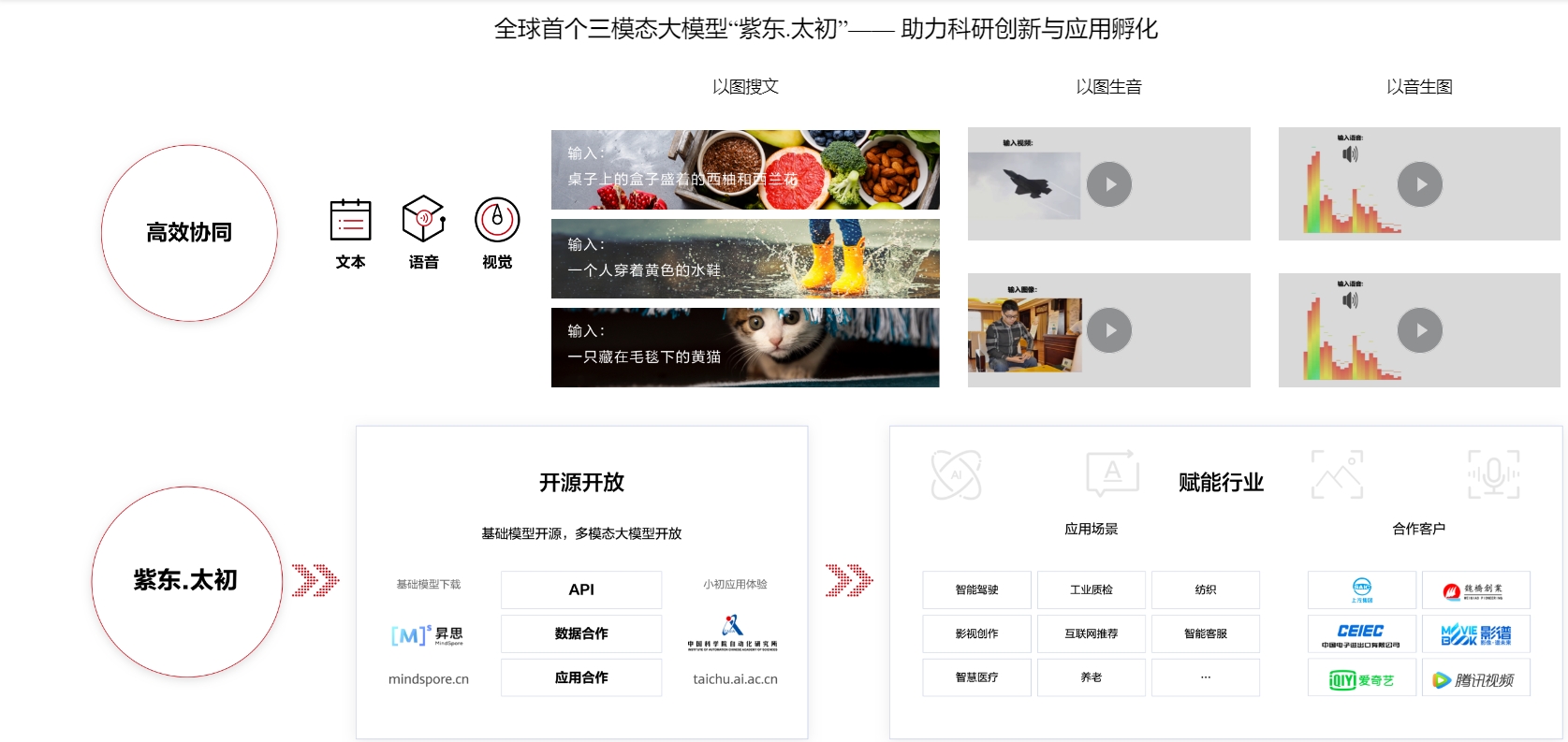
应用价值
引用说明
如果你使用了该项目,请引用该论文,论文链接:https://arxiv.org/abs/2107.00249
免责声明
MindSpore(“我们”)不拥有数据集的任何所有权或知识产权,并且经过训练的模型是在“原样”和“可用”的基础上提供的。我们不对任何类型的数据集和经过训练的模型(统称为“材料”)作出任何陈述或保证,并且不对材料引起的任何损失、损害、费用或成本负责。请确保您有权根据数据集的相应许可和相关许可协议的条款使用数据集。提供的训练模型仅用于研究和教育目的。
致数据集所有者:如果您不希望 MindSpore 中包含数据集,或希望以任何方式对其进行更新,我们将根据您的要求删除或更新内容。请通过 GitHub 或 Gitee 联系我们。非常感谢您对社区的理解和贡献。
MindSpore 在 Apache 2.0 许可下可用,请参阅 LICENSE 文件
No Description
Python Jupyter Notebook Shell
