{kind=link}
{kind=link}
Are you sure you want to delete this task? Once this task is deleted, it cannot be recovered.
You can not select more than 25 topics
Topics must start with a chinese character,a letter or number, can include dashes ('-') and can be up to 35 characters long.
 jasondhuang
7c4513de0f
jasondhuang
7c4513de0f
|
1 year ago | |
|---|---|---|
| .. | ||
| README.md | 1 year ago | |
| README_CN.md | 1 year ago | |
| metaformer.png | 1 year ago | |
| poolformer.png | 1 year ago | |
| poolformer.py | 1 year ago | |
| poolformer_s12.yaml | 1 year ago | |
README.md
PoolFormer
Introduction
Instead of designing complicated token mixer to achieve SOTA performance, the target of this work is to demonstrate the competence of Transformer models largely stem from the general architecture MetaFormer. Pooling/PoolFormer are just the tools to support our claim.
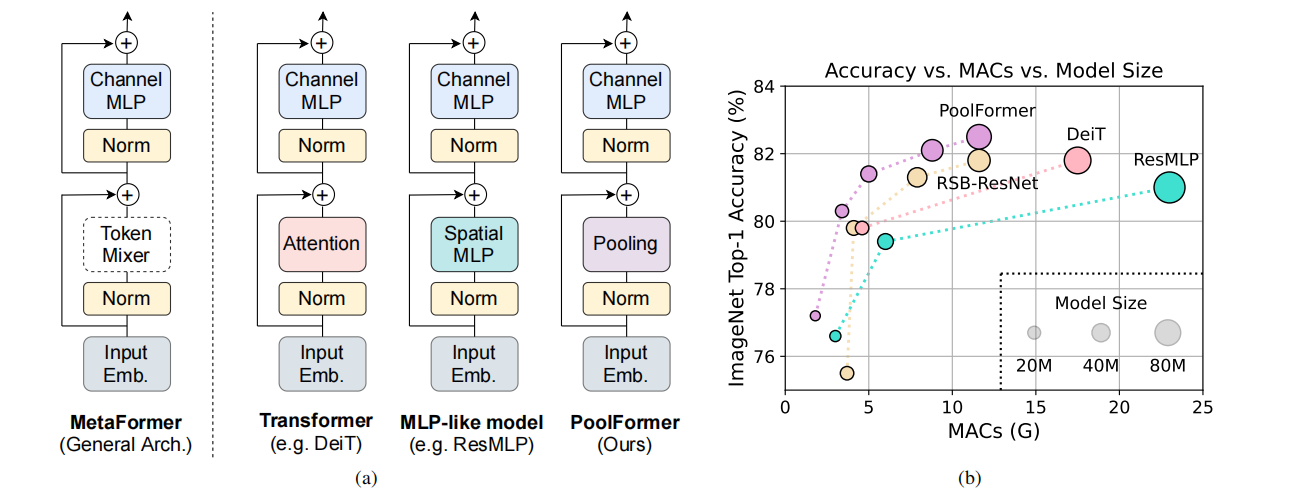
Figure 1: MetaFormer and performance of MetaFormer-based models on ImageNet-1K validation set. We argue that the competence of Transformer/MLP-like models primarily stem from the general architecture MetaFormer instead of the equipped specific token mixers. To demonstrate this, we exploit an embarrassingly simple non-parametric operator, pooling, to conduct extremely basic token mixing. Surprisingly, the resulted model PoolFormer consistently outperforms the DeiT and ResMLP as shown in (b), which well supports that MetaFormer is actually what we need to achieve competitive performance. RSB-ResNet in (b) means the results are from “ResNet Strikes Back” where ResNet is trained with improved training procedure for 300 epochs.

Figure 2: (a) The overall framework of PoolFormer. (b) The architecture of PoolFormer block. Compared with Transformer block, it replaces attention with an extremely simple non-parametric operator, pooling, to conduct only basic token mixing.
Results
| Model | Context | Top-1 (%) | Top-5 (%) | Params (M) | Train T. | Infer T. | Download | Config | Log |
|---|---|---|---|---|---|---|---|---|---|
| poolformer_s12 | D910x8 | 77.094 | 93.394 | 12 | 396.24s/epoch | 19.9ms/step | model | cfg | log |
Notes
- All models are trained on ImageNet-1K training set and the top-1 accuracy is reported on the validatoin set.
- Context: GPU_TYPE x pieces - G/F, G - graph mode, F - pynative mode with ms function.
Quick Start
Preparation
Installation
Please refer to the installation instruction in MindCV.
Dataset Preparation
Please download the ImageNet-1K dataset for model training and validation.
Training
-
Hyper-parameters. The hyper-parameter configurations for producing the reported results are stored in the yaml files in
mindcv/configs/poolformerfolder. For example, to train with one of these configurations, you can run:# train poolformer_s12 on 8 Ascends mpirun -n 8 python train.py -c ./configs/poolformer/poolformer_s12.yaml --data_dir=/path/to/dataNote that the number of GPUs/Ascends and batch size will influence the training results. To reproduce the training result at most, it is recommended to use the same number of GPUs/Ascneds with the same batch size.
Detailed adjustable parameters and their default value can be seen in config.py.
Validation
-
To validate the trained model, you can use
validate.py. Here is an example for densenet121 to verify the accuracy of
pretrained weights.python validate.py --model=poolformer_s12 --data_dir=imagenet_dir --val_split=val --ckpt_path
Deployment (optional)
Please refer to the deployment tutorial in MindCV.
No Description
Jupyter Notebook Python Markdown Text
Contributors (25+)
285365963@qq.com
100194830+JunyuLiu1@users.noreply.github.com
 74176172+GeniusPatrick@users.noreply.github.com
74176172+GeniusPatrick@users.noreply.github.com

 zp5070@gmail.com
83412649+spencerr221@users.noreply.github.com
zp5070@gmail.com
83412649+spencerr221@users.noreply.github.com
 jasondhuang@tencent.com
jasondhuang@tencent.com
 97332102+XuanmaiXue@users.noreply.github.com
119582555+sy-liang123@users.noreply.github.com
48508716+Baogerock@users.noreply.github.com
2441413514@qq.com
97332102+XuanmaiXue@users.noreply.github.com
119582555+sy-liang123@users.noreply.github.com
48508716+Baogerock@users.noreply.github.com
2441413514@qq.com
 74176172+geniuspatrick@users.noreply.github.com
huxiuyu1943@sina.com
74176172+geniuspatrick@users.noreply.github.com
huxiuyu1943@sina.com
 xingxjtu@gmail.com
xingxjtu@gmail.com
 110210055+xiuyu0000@users.noreply.github.com
110210055+xiuyu0000@users.noreply.github.com
 canna1102.yy@gmail.com
canna1102.yy@gmail.com

74176172+GeniusPatrick@users.noreply.github.com
zp5070@gmail.com
83412649+spencerr221@users.noreply.github.com
jasondhuang@tencent.com
97332102+XuanmaiXue@users.noreply.github.com
119582555+sy-liang123@users.noreply.github.com
48508716+Baogerock@users.noreply.github.com
2441413514@qq.com
74176172+geniuspatrick@users.noreply.github.com
huxiuyu1943@sina.com
xingxjtu@gmail.com
110210055+xiuyu0000@users.noreply.github.com
canna1102.yy@gmail.com