鹏城云脑I使用指北
考虑到不少同事使用云脑I都会或多或少的遇到一些问题,而且经常会发现大家会问到相同的问题。作为一名老(lao)用(si)户(ji), 建这个仓库(给自己挖坑),一方面分享个人的使用经验,另一方面希望能够收集大家遇到的问题。欢迎大家一起来做贡献~
咳咳,写着写着突然想起云脑I貌似有官方的使用手册,登录云脑I后,在这里选择【helper】
里面有一些帖子和使用手册,大家也可以去这里寻找云脑I使用相关解答。这里我直接贴上官方的教程链接,方便大家直接查看。
PS: 下面截图看起来有点小,请将网页放大后观察 ^_^!
云脑I使用介绍
内网访问网址:192.168.204.24/#/openi/v2/home
前期准备
-
云脑I主要提供CPU+GPU算力;提供三种类型的GPU加速卡,包括V100,T4和2080Ti;
| 队列名称 |
Driver Version |
CUDA Version |
| debugt4 |
450.80.02 |
11.0 |
| dgx2 |
470.57.02 |
11.4 |
| dgx1 |
450.80.02 |
11.0 |
| debug |
440.100 |
10.2 |
PS: 据同事反馈,以上信息不一定完全正确,有时候资源分配可能也不对,以实际为准。
-
云脑I使用需要有一个账号,同事们可以在OA->个人门户->鹏城云脑资源(左边任务栏)->云脑使用申请。根据自己的需求来填表,完成申请;
-
云脑I目前通过网页的方式来访问,目前只支持内网访问。如果在外网,需要申请实验室的VPN;我暂时没有使用实验室VPN,实验室VPN申请内容欢迎大家补充;
云脑I的世界观
-
云脑I基于Docker对物理硬件进行抽象,并进行资源隔离
- 每次提交任务,都需要选取一个Docker镜像;
- 支持用户自定义镜像;
- 【重要】每次任务关闭后,一般来说用户的数据将不会保留!!!(解决方法见下条)
-
云脑I提供了两个特殊的目录
- /userhome:提供用户希望存储数据的路径;
- /gdata:提供主流数据集,包括ImageNet-1K,COCO等;
这两个目录是挂载到docker的目录,里面的数据不会随着Docker的关闭(任务结束)而消失。
-
云脑I上任务主要分为【训练任务】与【debug任务】
- 【训练任务】提供训练,可以编写启动任务的命令,可以长时间运行;
- 【debug任务】用来做代码开发和调试,提供了jupter-notebook环境,运行有时间限制,到时间后任务会自动关闭;
云脑I实操-debug模式 (新手教程)
-
内网用户直接访问网址:http://192.168.204.24/#/openi/v2/home
-
登录成功后,进入下面界面:
-
下面进入debug channel选项卡:
-
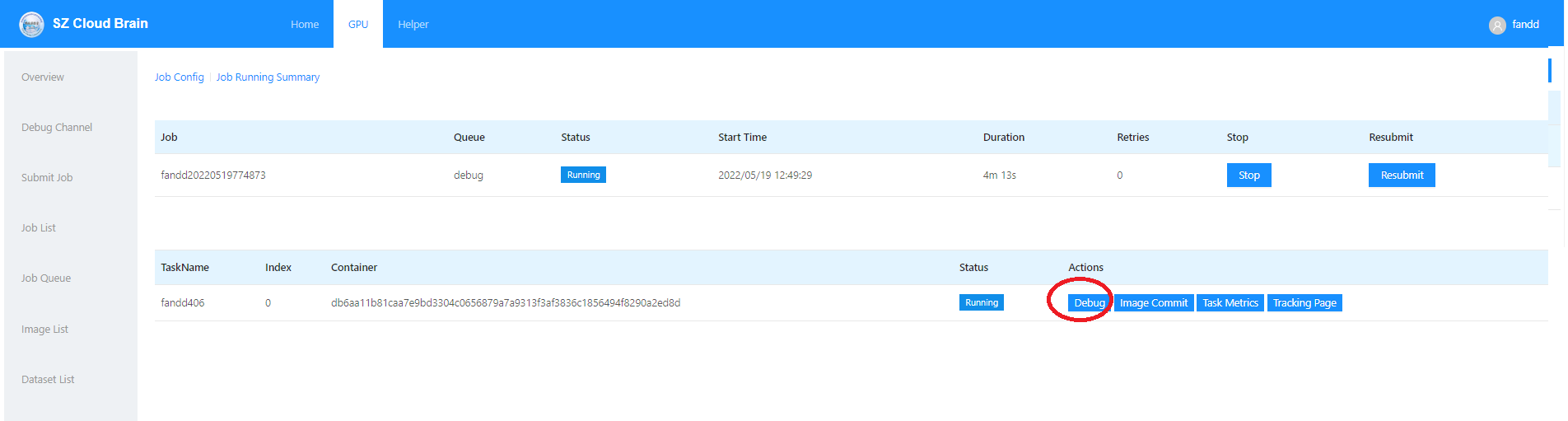
在左边任务栏中,选取Job list,可以查看刚才提交的debug任务。
这里可以停止任务(stop按钮),也可以重新提交任务(Resubmit按钮);
-
点击第一列的Job ID,就可以直接进入任务详情。如下图:
这里可以查看任务的提交时间,运行时间。要进入容器,点击右下方的debug按钮。
-
之后,我们进入熟悉的jupter-lab页面:
- 这里可以新建notebook,新建python终端,和terminal等。这就是大家熟悉的东西了;
- 左边的目录挂载的是/userhome目录下的文件,也就是用户的个人文件。这个目录下的东西不会因为容器关闭而消失;
- 在terminal中查看当前系统挂载点情况,可以看到/userhome和/gdata目录是通过网络硬盘挂载过来的,因此里面数据是持久保存的;
- 点击左上方的小圈圈,可以上传小文件;如果需要上传大文件,建议使用ftp服务;
- 一般来说,用户会在这个里面打开项目代码进行开发或者调试;
云脑I实操-train模式 (新手教程)
-
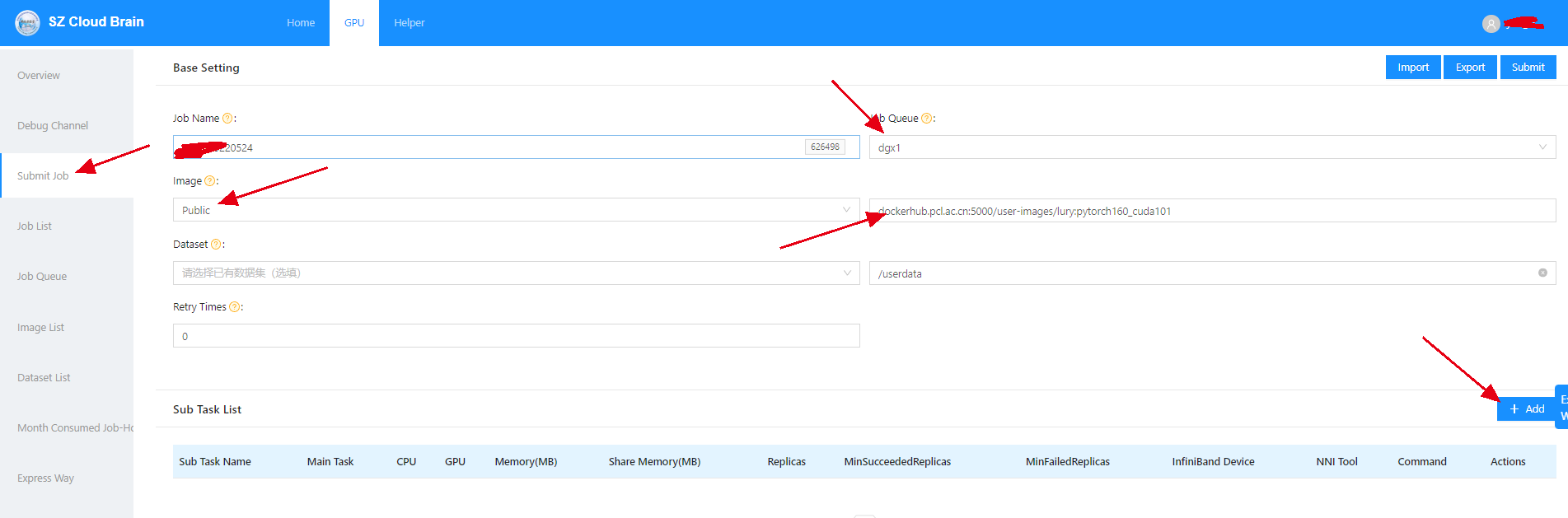
登录云脑I后,选择下面任务栏中的submit job
关注箭头中的几个选项。
- 选择submit job;
- 选择job Queue,即任务队列;如果是要提交训练任务,不要选debug,其它按照自己的需求来选择;
- 选择public镜像 ( 如果没有自己构建镜像的情况下);
- 选择具体的镜像;我这里选择的是一个带有pytorch 1.6环境的,cuda101版本的镜像;
- 点击add按钮;
-
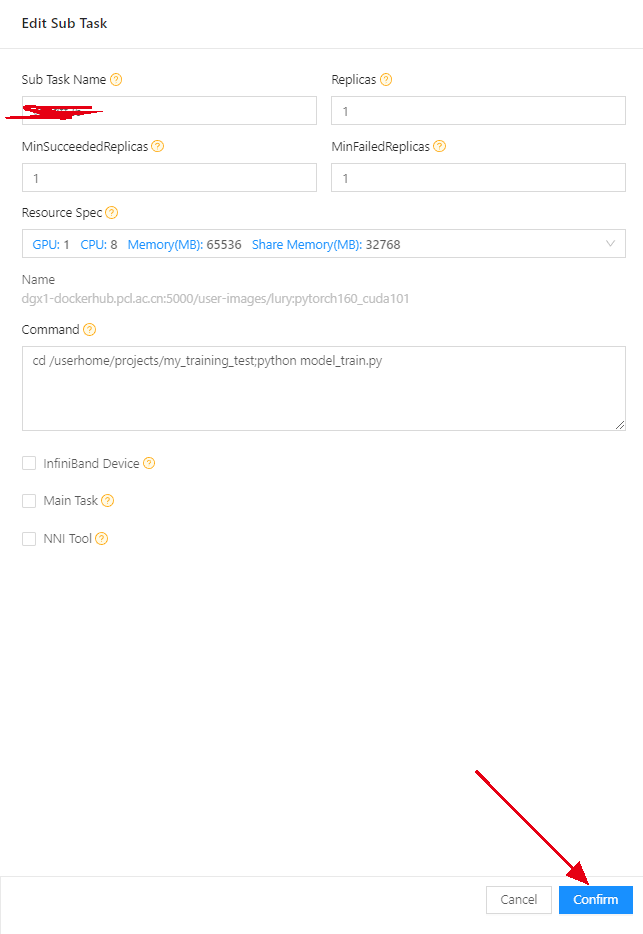
add按钮详情
这里需要注意两点:
-
Replicas参数:这个参数决定你要启动几个相同的docker,一般是做多机并行会修改这个;
-
Resource Spec: 这个根据自己任务的需求来选择,用CPU还是GPU,用多少块GPU等;
-
Command:这个里面填写你想在docker中运行的参数;比如:cd /userhome/projects/my_training_test;python model_train.py
说明:
- Command命令运行结束,整个docker就会被关闭;
- 注意将结果保存到/userhome目录下,这样数据就不会随着docker的关闭而丢失;
-
上面配置完成后,点击confirm按钮,退回到之前的界面,点击右上角的submit按钮,完成任务提交;
-
查看刚才提交的任务:这个跟debug模式的第4点相同。
注意:对于train模式,没有对应的jupyter-lab页面。任务提交后,只能查看自己打印的日志来了解任务的详情;(这点特别想吐槽,为什么不提供train的terminal)
-
关于train模式下,如何通过terminal登录到训练容器内,可以参考教程链接中的多机通信方案,相信聪明的你一定能在这里发现惊喜(体验自主可控的乐趣[Doge])。
ftp服务
-
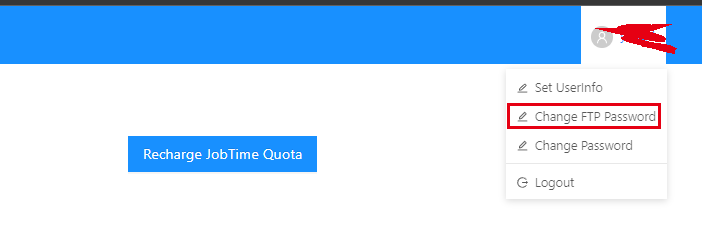
在登录界面选择【修改文件管理服务密码】,修改FTP登录密码:
-
下载FTP客户端-winscp
-
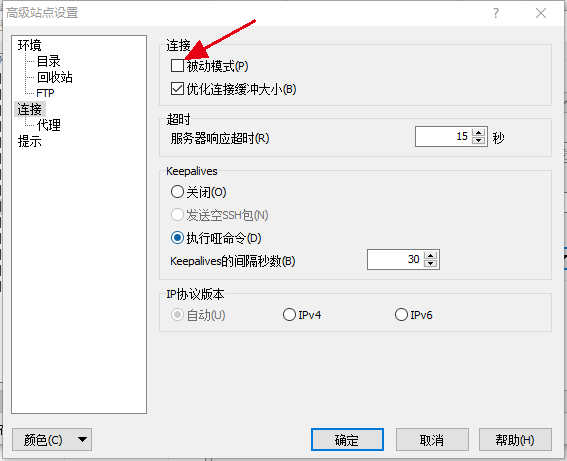
配置如下,替换下图中的用户名和密码;注意ip填写192.168.204.94;
-
点击上图中高级->连接->被动模式(去掉默认的√)。这步必须要完成配置,不然无法读取远程目录
-
ftp服务连接到远程目录/userhome。注意,ftp服务不需要提交任务,就能直接读取远程文件。
自定义镜像
-
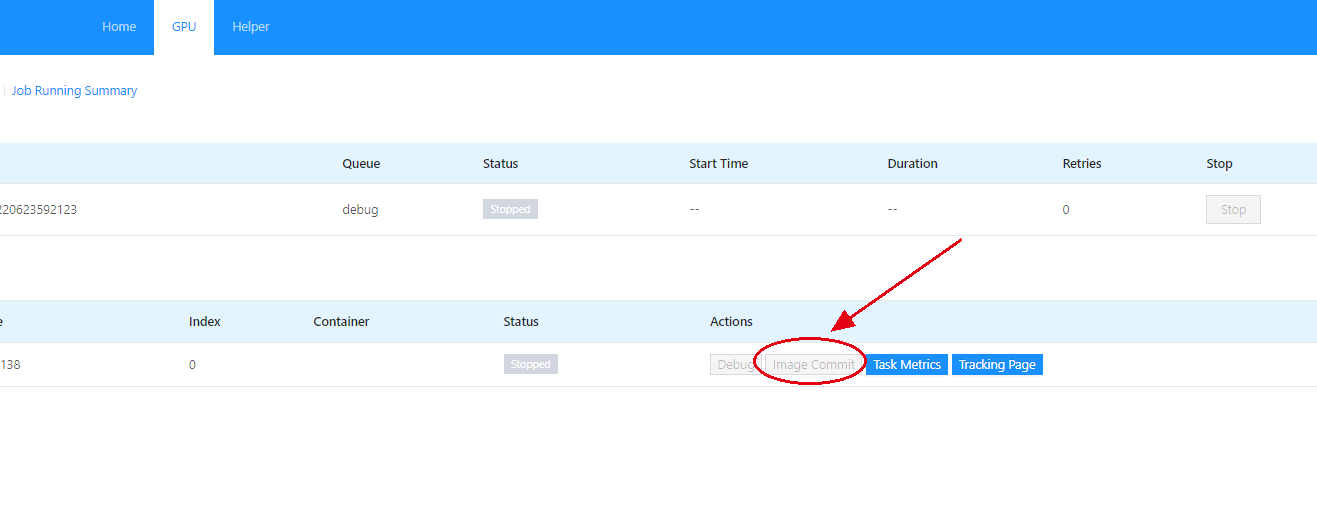
最直接的办法是在debug模式下,配置好容器后,在查看任务的界面直接commit当前镜像就好(推荐);
-
在本地做好镜像,将其上传到实验室自建的docker hub上。
- 在pcyn-dockerhub网页创建账号 link,然后登录pcyn-dockerhub网页,你会进入到Harbor页面(网页左上角有个Harbor图标),点击「新建项目」来创建一个独立的文件夹来存放自己的docker镜像,选用一个合适的项目名词,以下假设项目名称为
user-xxx(项目的访问级别必须是「公开」,否则pcyn无法读取该项目下的仓库);
- 在服务器配置文件
/etc/docker/daemon.json中添加配置:"insecure-registries": ["192.168.202.74:5000"];
如果没有做上面配置,下一步登录时出现报错信息为:Error response from daemon: Get "https://192.168.202.74:5000/v2/": http: server gave HTTP response to HTTPS client
- 在个人电脑上执行
docker login 192.168.202.74:5000,然后依次输入刚才在pcyn-dockerhub上创建的账户与用户名;
- 在个人电脑查看本地镜像文件:
docker images;假定选取镜像ubuntu:latest;
- 给镜像打标签:
docker tag ubuntu:latest 192.168.202.74:5000/fandd/ubuntu:latest
- 在个人电脑上执行
docker push 192.168.202.74:5000/user-xxx/ubuntu:latest;
- 回到网页上,在项目
test-xxx下面,就能看到ubuntu的目录,里面存在一个tag为latest的镜像;
- 在配置云脑I开发或者训练调用镜像的时候,镜像地址写:
dockerhub.pcl.ac.cn:5000/user-xxx/ubuntu:latest;
-
如何从公开的docker hub下载镜像源 (以cuda-11.0-pytorch)
- 找到你需要的镜像地址: https://hub.docker.com/r/pytorch/pytorch/tags
- 找到你需要的镜像版本:这里注意一下,要选devel版本的cuda,要不然nvcc 是无法调用出来的。
- 复制命令: docker pull pytorch/pytorch:1.7.0-cuda11.0-cudnn8-runtime 平台公开镜像只需要添 'dokcer pull' 指令之后的部分。
- 这下来就是等待了。
- 进入之后不是常见的shell类型的命令方式不是bash,因此需要转换到bash。具体可见:https://help.aliyun.com/document_detail/109503.html
- 之后就可以调用conda安装自己的python包了。
FAQ
这是大家常问的一些问题:
-
关于用户有提到云脑训练速度慢的问题;
要注意云脑I上面的硬盘情况;在/userhome和/gdata目录下的文件,我理解是存放在机械硬盘上的。而其它目录是存放在本机上的,也就是SSD。由于训练过程中,数据处理部分往往耗时也比较多;如果直接使用/gdata下面的数据集,会造成数据集处理部分耗时严重,影响整个训练效率。
建议:将数据集从/gdata里面拷贝到/mnt等根目录上挂载的目录中,重新训练。
比如,我们使用ImageNet2012-1K数据集;可以在启动脚本里面这样写:
mkdir /mnt/ImageNet2012; cd /gdata/ImageNet2012; cp -r train val /mnt/ImageNet2012; python /userhome/projects/ELSA/train.py
注:拷贝ImageNet2012数据集到本地目录耗时差不多半小时以上,做好心理预期;
-
有用户反馈镜像包太大了,无法上传;
在做镜像时,只需要把cuda放进去即可;不用在镜像中安装pytorch,tensorflow等其它的包;这些包在进入docker后,利用conda来部署环境,将这些包安装到conda里面,conda放到/userhome下面;这样每次进入docker,直接利用conda激活环境即可。
-
关于网页日志看不到;
-
BUG1: cuda error: no kernel image is available for execution on the device
这个bug 问题出现在 Apex(https://github.com/NVIDIA/apex)使用过程中,换机器就会出现,因此需要在每台机器运行命令前,重新编译。
命令为: python setup.py install --cuda_ext --cpp_ext
-
BUG2: 在使用pytorch时候,可能会出现,程序被断了,但是显存依然在被占用的情况。但是云脑nvidia-smi命令并不会给出程序的PID, 因此需要调用这个命令:(当然保证你的训练命令里是有python的)
ps aux|grep root|grep python
这样就可以看到PID,进而kill掉,释放无用显存。