第13课-如何进行模型训练(PaddlePaddle版本)
1 概述
- 本项目以LeNet-MNIST为例,简要介绍如何在启智AI协同平台上使用PaddlePaddle完成训练任务,旨在为AI初学者提供云脑训练示例。
- 大家可以直接使用本项目提供的数据集和代码文件创建自己的训练任务。
- 同时也为初学者提供了全流程图文教程,只需要简单5步即可完成训练任务。
2 准备工作
- 启智平台使用准备,本项目需要用户创建启智平台账户,克隆代码到自己的账户,上传数据集,具体操作方法可以通过访问OpenI_Learning项目学习小白训练营系列课程进行学习。
2.1 数据和代码
- 数据集可从本项目的数据集目录中下载,数据集下载
- 数据文件说明
- MNISTData数据集是由10类28∗28的灰度图片组成,训练数据集包含60000张图片,测试数据集包含10000张图片。
- 数据集文件的目录结构如下:
MNIST_Data
├── test
│ ├── t10k-images-idx3-ubyte
│ └── t10k-labels-idx1-ubyte
└── train
├── train-images-idx3-ubyte
└── train-labels-idx1-ubyte
2.2 示例代码
快速开始: PaddlePaddle手写识别GPU训练任务实例
如果你是初学者或者不熟悉平台云脑任务的使用,通过以下5个简单步骤,你将快速学会如何创建项目,并开启一个GPU训练任务,实现手写体识别。
本节课主要演示如何在云脑1完成训练任务以及模型管理,大致内容如下:
创建项目
代码提交
关联数据集
创建训练任务
训练完成
1 创建项目
-
首先你需要注册一个启智社区的账号。
-
注册成功之后,请 点击这里 创建新项目。
-
进入创建项目详情界面
- 填写
项目名称
- 勾选
初始化存储库
- 勾选
承诺遵守平台使用协议
- 点击
创建项目
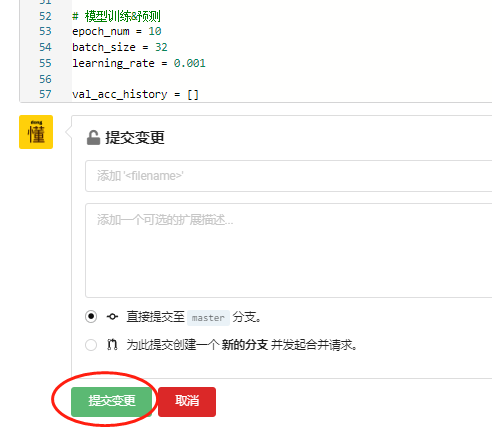
2 代码提交
- 创建成功之后,来到项目主页。可以看到代码仓里已经默认生成了
README.md 描述文件,包含项目名称以及项目描述。
- 点击蓝色的
新建文件 按钮,将下面的示例代码复制到代码框,并命名为 train.py 。
# 加载数据集
import paddle
from paddle.vision.transforms import Compose, Normalize
transform = Compose([Normalize(mean=[127.5],
std=[127.5],
data_format='CHW')])
# 使用transform对数据集做归一化
print('download training data and load training data')
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=transform)
test_dataset = paddle.vision.datasets.MNIST(mode='test', transform=transform)
print('load finished')
# 定义网络结构
import paddle.nn.functional as F
class LeNet(paddle.nn.Layer):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = paddle.nn.Conv2D(in_channels=1, out_channels=6, kernel_size=5, stride=1, padding=2)
self.max_pool1 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.conv2 = paddle.nn.Conv2D(in_channels=6, out_channels=16, kernel_size=5, stride=1)
self.max_pool2 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.linear1 = paddle.nn.Linear(in_features=16*5*5, out_features=120)
self.linear2 = paddle.nn.Linear(in_features=120, out_features=84)
self.linear3 = paddle.nn.Linear(in_features=84, out_features=10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.max_pool1(x)
x = self.conv2(x)
x = F.relu(x)
x = self.max_pool2(x)
x = paddle.flatten(x, start_axis=1,stop_axis=-1)
x = self.linear1(x)
x = F.relu(x)
x = self.linear2(x)
x = F.relu(x)
x = self.linear3(x)
return x
# 使用 Model.fit来训练模型
from paddle.metric import Accuracy
model = paddle.Model(LeNet()) # 用Model封装模型
optim = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
# 配置模型
model.prepare(
optim,
paddle.nn.CrossEntropyLoss(),
Accuracy()
)
# 训练模型
model.fit(train_dataset,
epochs=2,
batch_size=64,
verbose=1
)
# 使用 Model.evaluate 来预测模型
model.evaluate(test_dataset, batch_size=64, verbose=1)
3 关联数据集
在项目页面中,依次点击 数据集→关联数据集→关联数据集, 搜索MNIST_PaddlePaddle_GPU,选择并关联。
4 创建训练任务
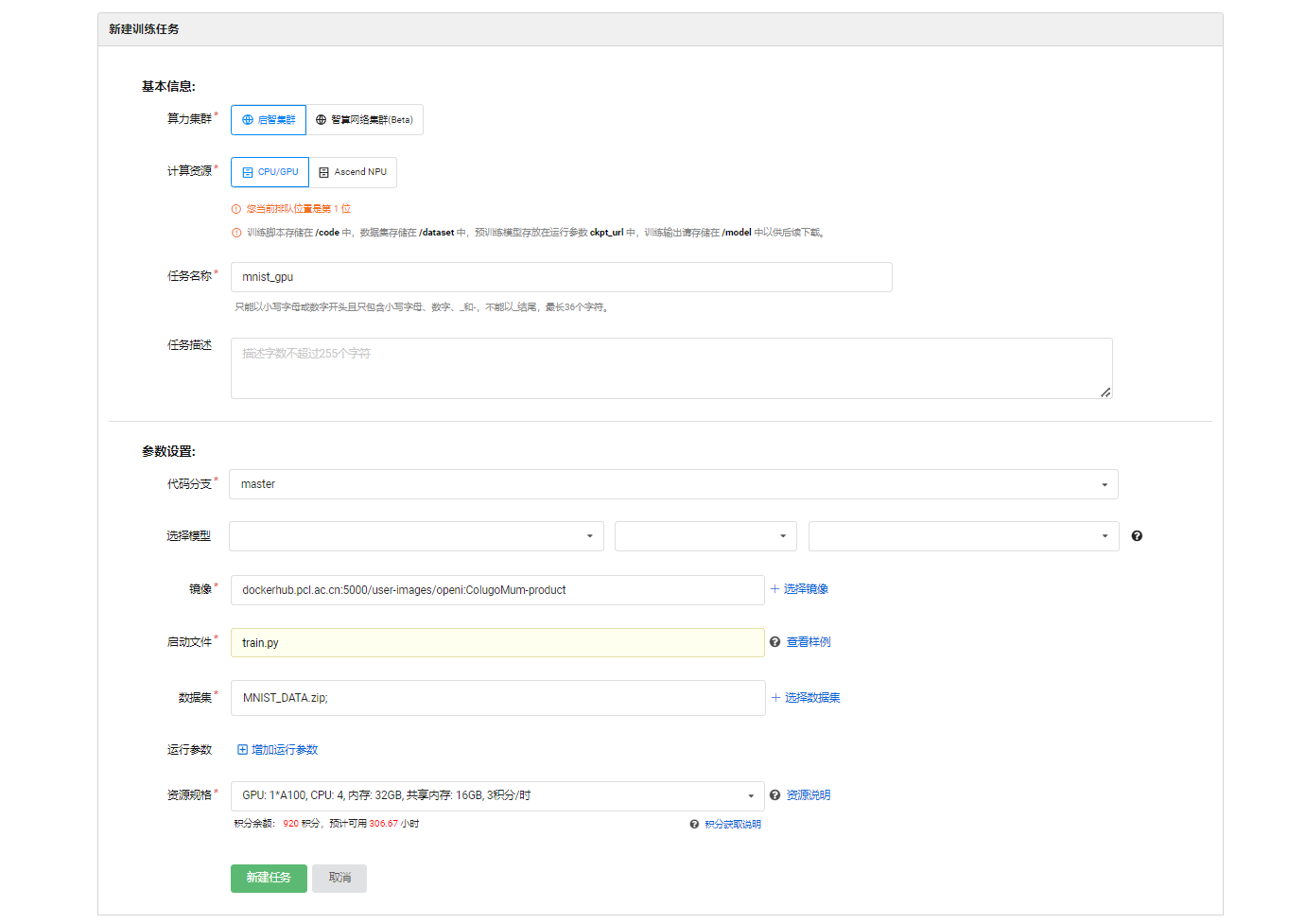
- 接下来创建云脑训练任务,在项目里找到 云脑 → 训练任务 → 新建训练任务。
-
填写以下参数
- 算力集群 启智集群
- 计算资源
CPU/GPU
- 任务名称
mnist_gpu
- 镜像 复制并粘贴地址
dockerhub.pcl.ac.cn:5000/user-images/openi:ColugoMum-product
- 启动文件
train.py
- 数据集 本项目关联
MNIST_PaddlePaddle_GPU/MNIST_DATA.zip
- 资源规格 GPU: 1*A100, CPU: 4, 内存: 32GB, 共享内存: 16GB
- 其他配置保持默认值即可
5 训练完成
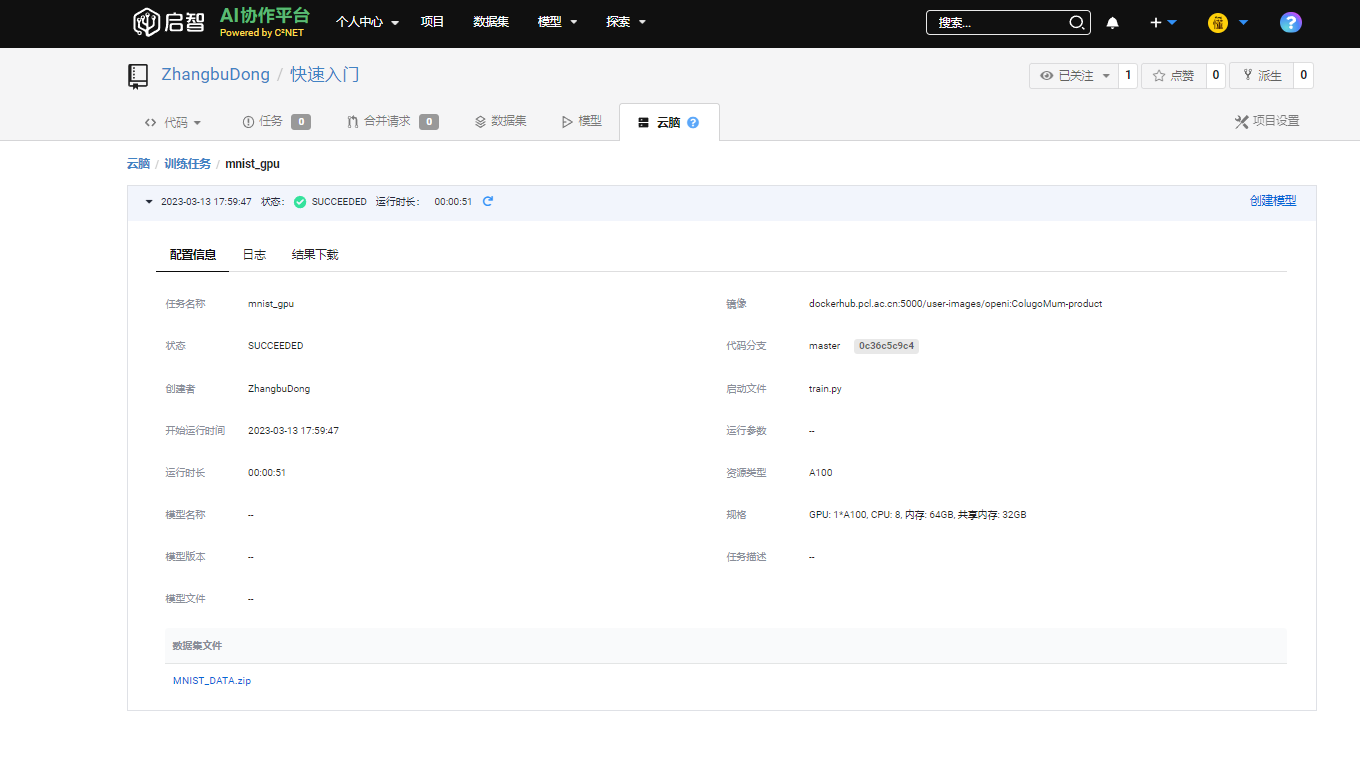
- 当训练任务的状态由 WAITING 变为 SUCCEEDED,任务训练成功。点击 任务名称 查看详情。
5.1 在配置信息界面可以查看任务配置
- 包括任务具体配置,包括镜像,数据集,资源规格,运行时间以及脚本文件。
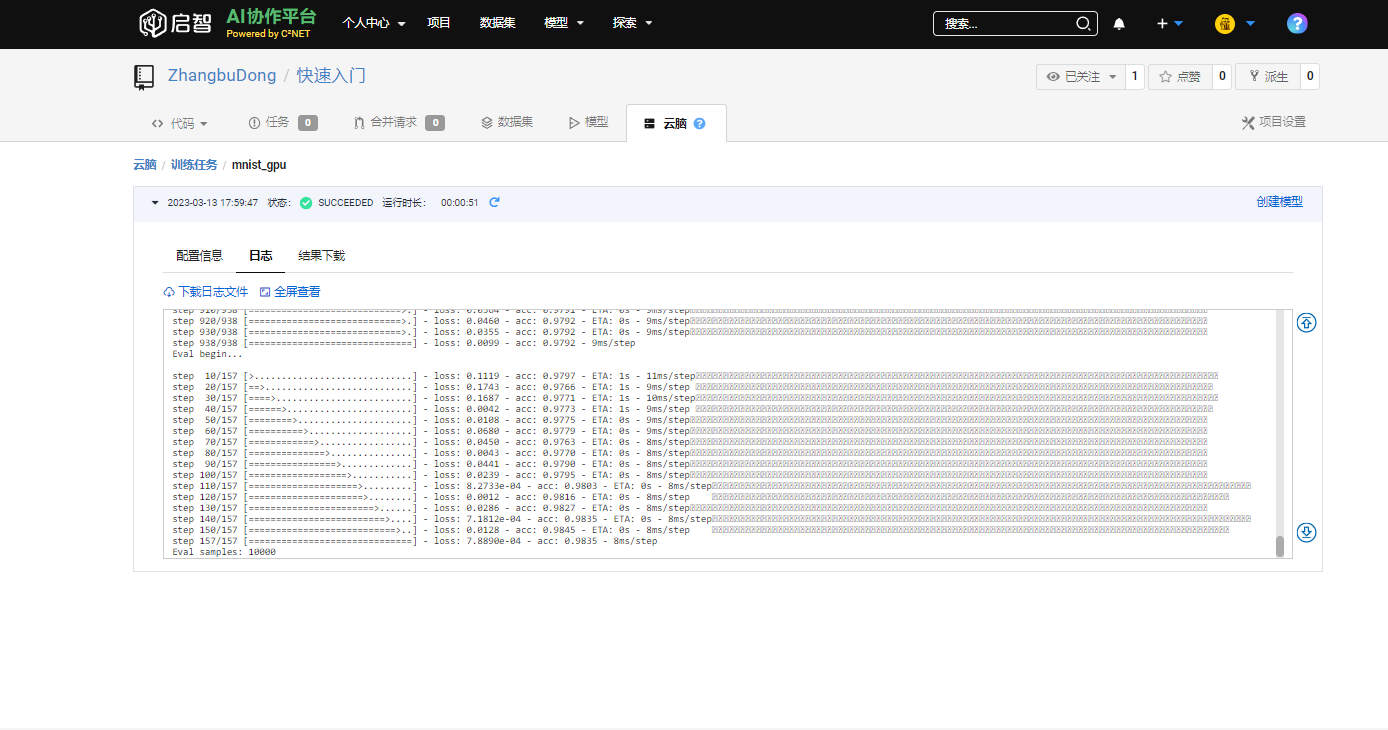
5.2 在日志界面可以查看运行日志
- 这里是脚本文件中的所有输出打印,也叫做你的
任务日志。你可以自行在脚本文件中编辑你输出的信息。示例脚本 中打印了训练中每一个 batch 的损失,以及模型最终的准确率。
5.3 训练结束后可以下载模型文件
- 在这里你可以下载在脚本中输出的所有文件以及日志文本。
示例脚本 里输出了最终的PyTorch模型文件。