简体中文 | English
Label Studio User Guide - Text Classification
Table of contents
1. Installation
** Dependencies used in the following annotation examples:**
- Python 3.8+
- label-studio == 1.6.0
Use pip to install label-studio in the terminal:
pip install label-studio==1.6.0
Once the installation is complete, run the following command line:
label-studio start
Open http://localhost:8080/ in the browser, enter the user name and password to log in, and start using label-studio for labeling.
2. Text Classification Task Annotation
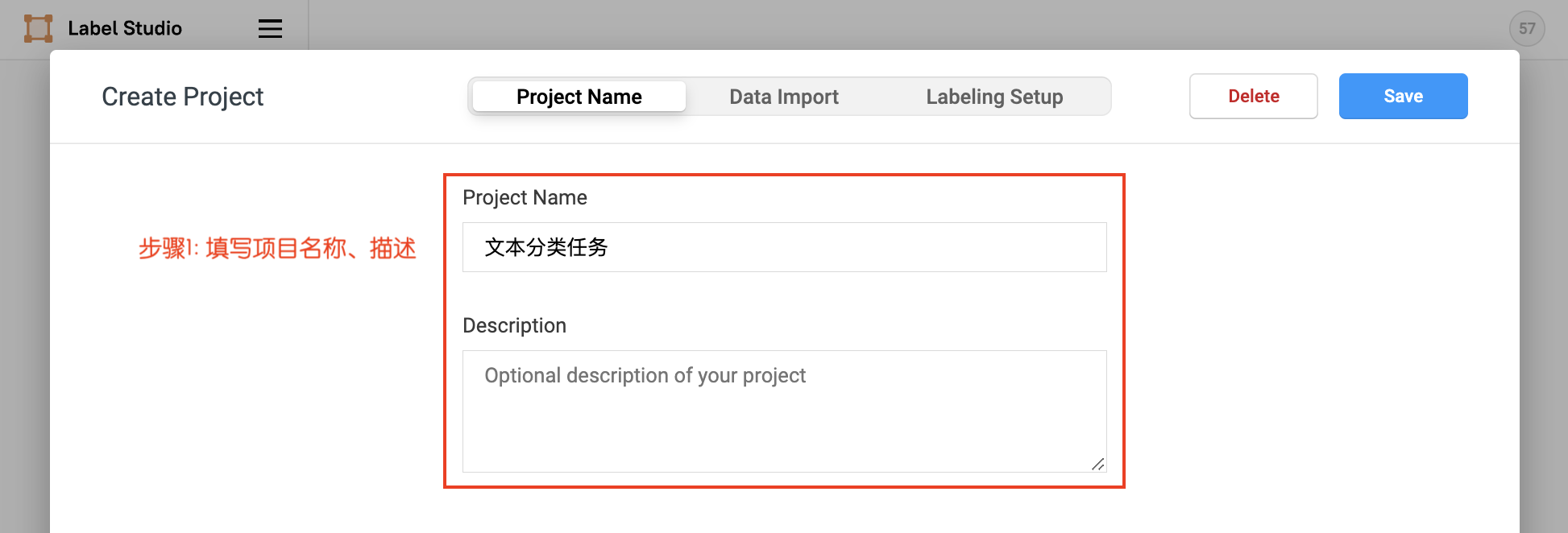
2.1 Project Creation
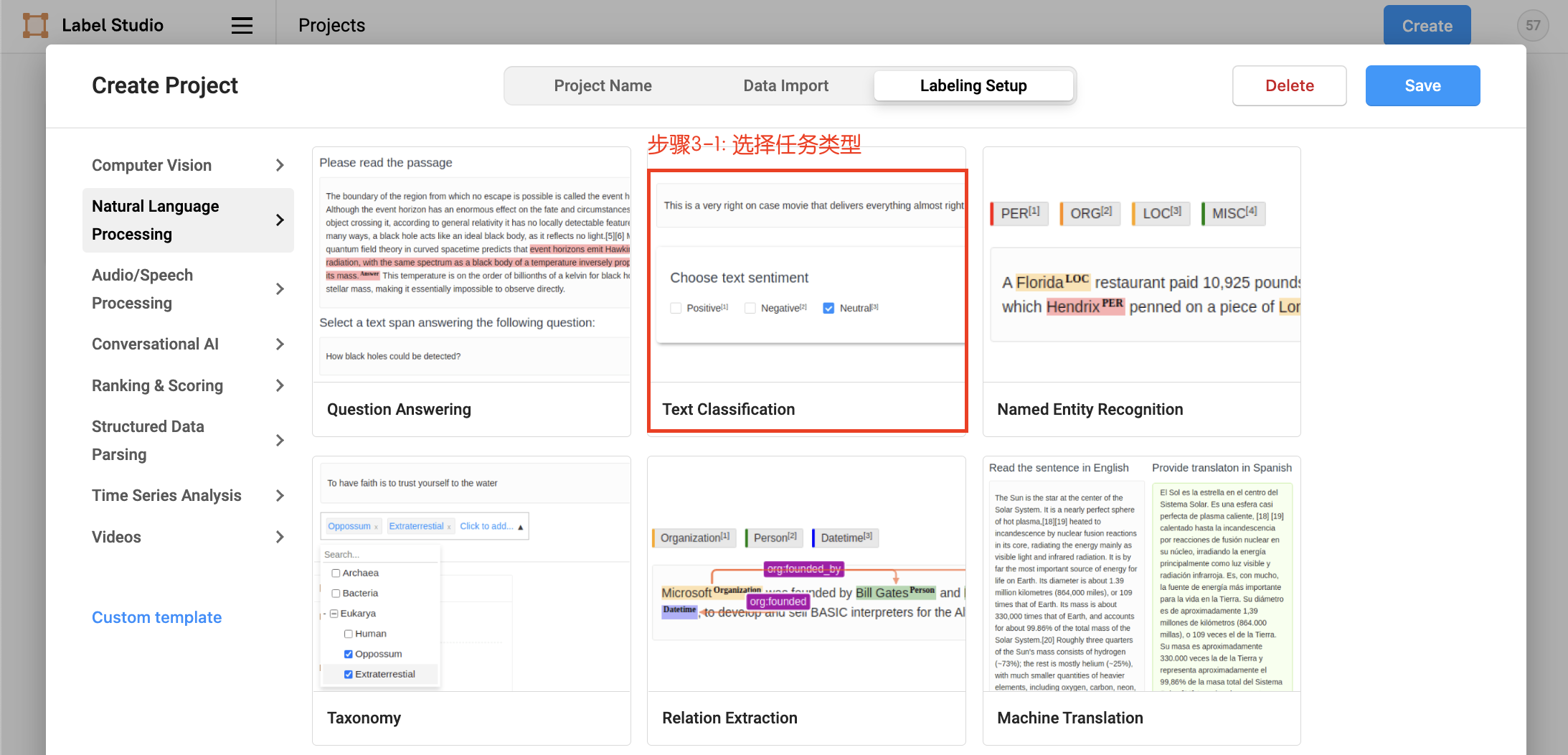
Click Create to start creating a new project, fill in the project name, description, and select Text Classification in Labeling Setup.
- Fill in the project name, description
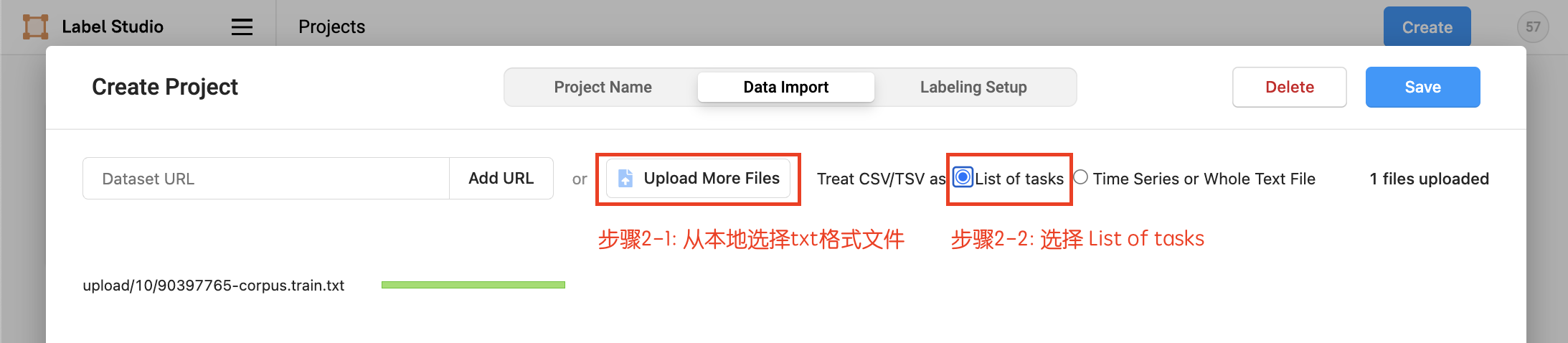
- Upload the txt format file locally, select
List of tasks, and then choose to import this project.
2.2 Data Upload
You can continue to import local txt format data after project creation. See more details in Project Creation.
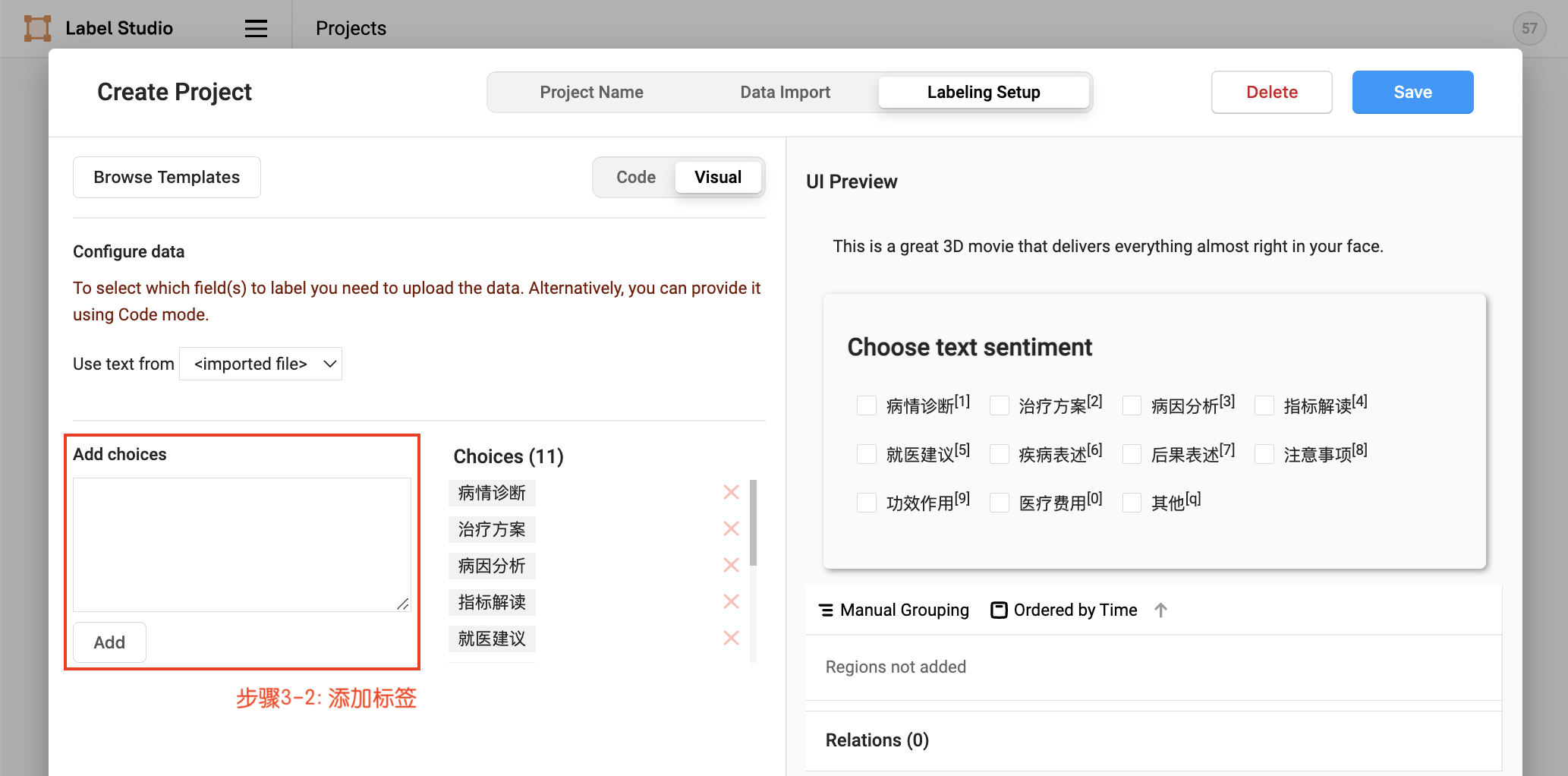
2.3 Label Construction
After project creation, you can add/delete labels in Setting/Labeling Interface just as in Project Creation
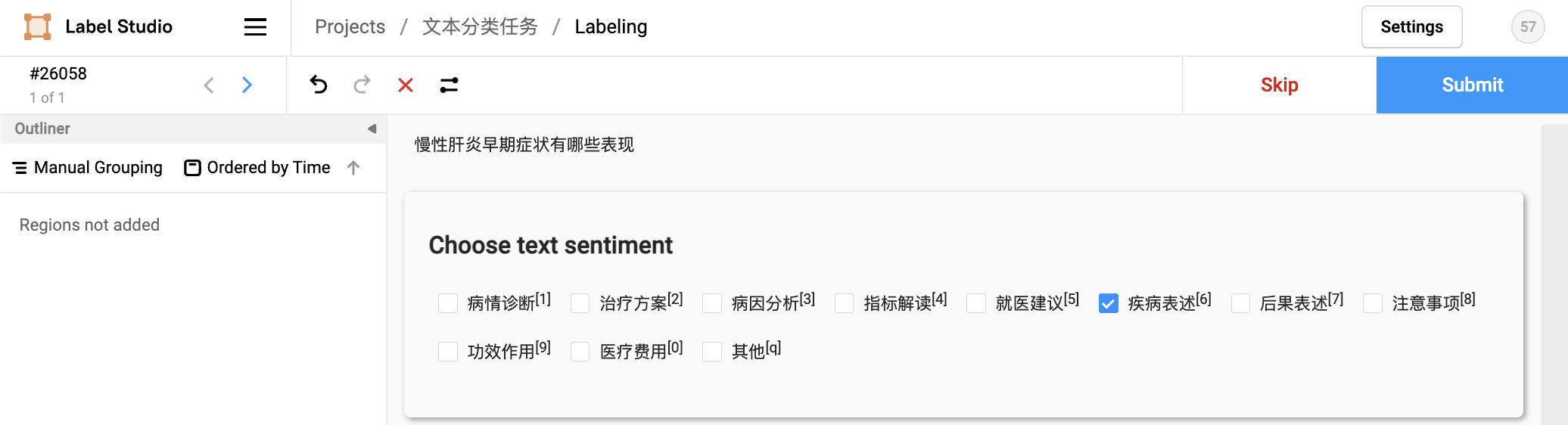
2.4 Task annotation
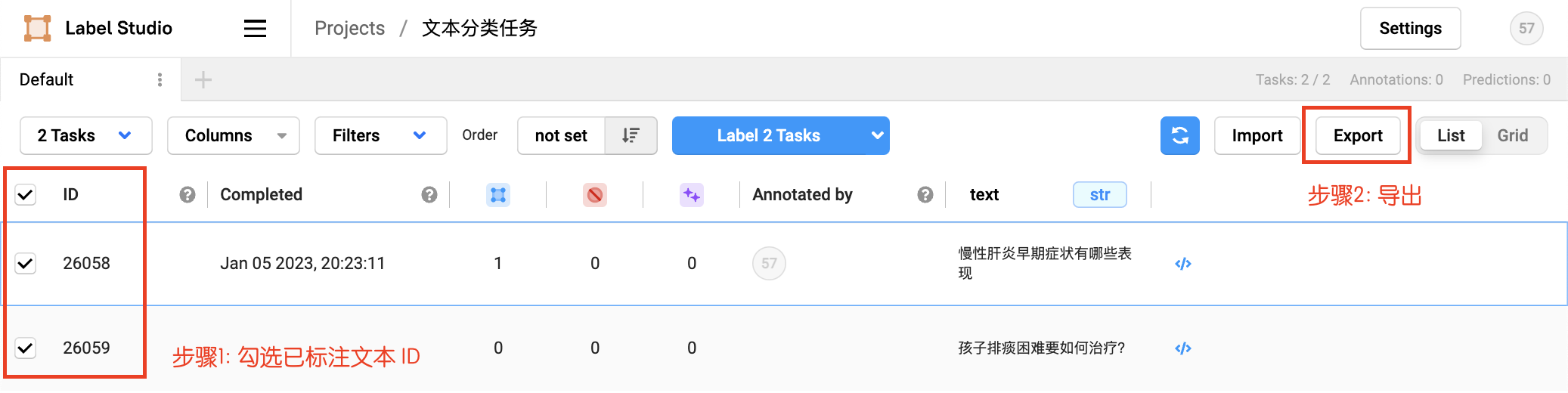
2.5 Data Export
Check the marked text ID, select the exported file type as JSON, and export the data:
2.6 Data conversion
First, create a label file in the ./data directory, with one label candidate per line. You can also directly set label condidates list by options. Rename the exported file to label_studio.json and put it in the ./data directory. Through the label_studio.py script, it can be converted to the data format of UTC.
python label_studio.py \
--label_studio_file ./data/label_studio.json \
--save_dir ./data \
--splits 0.8 0.1 0.1 \
--options ./data/label.txt
2.7 More Configuration
label_studio_file: Data labeling file exported from label studio.save_dir: The storage directory of the training data, which is stored in the data directory by default.splits: The proportion of training set and validation set when dividing the data set. The default is [0.8, 0.1, 0.1], which means that the data is divided into training set, verification set and test set according to the ratio of 8:1:1.options: Specify the label candidates set. For filename, there should be one label per line in the file. For list, the length should be longer than 1.is_shuffle: Whether to randomly shuffle the data set, the default is True.seed: random seed, default is 1000.
Note:
- By default the label_studio.py script will divide the data proportionally into train/dev/test datasets
- Each time the label_studio.py script is executed, the existing data file with the same name will be overwritten
- For files exported from label_studio, each piece of data in the default file is correctly labeled manually.
References