Are you sure you want to delete this task? Once this task is deleted, it cannot be recovered.
You can not select more than 25 topics
Topics must start with a chinese character,a letter or number, can include dashes ('-') and can be up to 35 characters long.
 Sijun He
dc5f5d82f6
Sijun He
dc5f5d82f6
|
1 year ago | |
|---|---|---|
| .. | ||
| doc_vqa | 1 year ago | |
| docprompt | 1 year ago | |
| README.md | 1 year ago | |
README.md
文档智能应用
目录
1. 文档智能应用简介
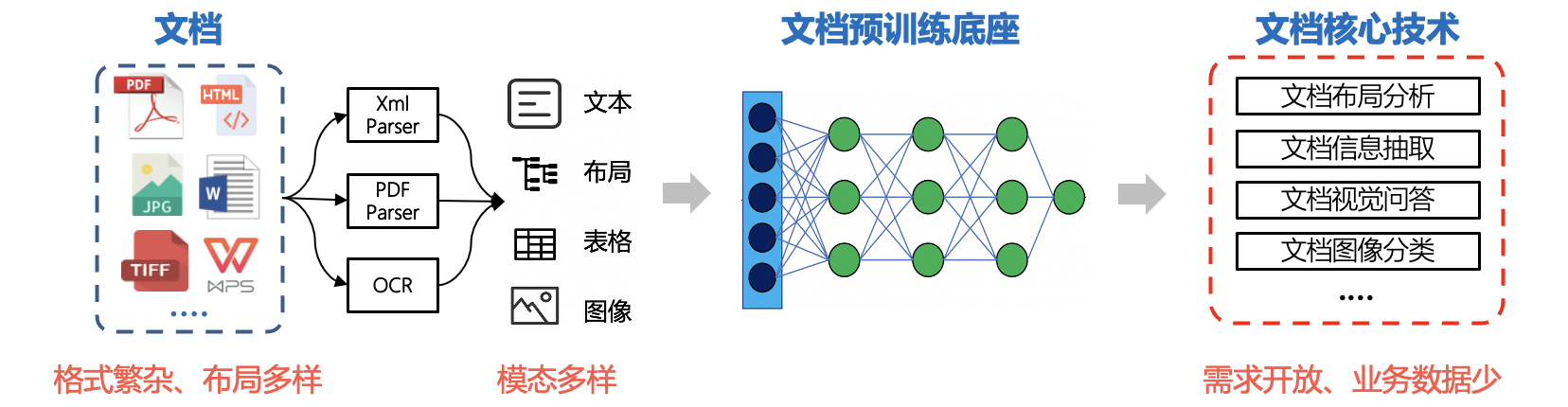
文档智能(DI, Document Intelligence)主要指对于网页、数字文档或扫描文档所包含的文本以及丰富的排版格式等信息,通过人工智能技术进行理解、分类、提取以及信息归纳的过程。文档智能技术广泛应用于金融、保险、能源、物流、医疗等行业,常见的应用场景包括财务报销单、招聘简历、企业财报、合同文书、动产登记证、法律判决书、物流单据等多模态文档的关键信息抽取、文档解析、文档比对等。
在实际应用中,需要解决文档格式繁杂、布局多样、信息模态多样、需求开放、业务数据少等多重难题。针对文档智能领域的痛点和难点,PaddleNLP将持续开源一系列产业实践范例,解决开发者们实际应用难题。
2. 技术特色介绍
2.1 多语言跨模态训练基座
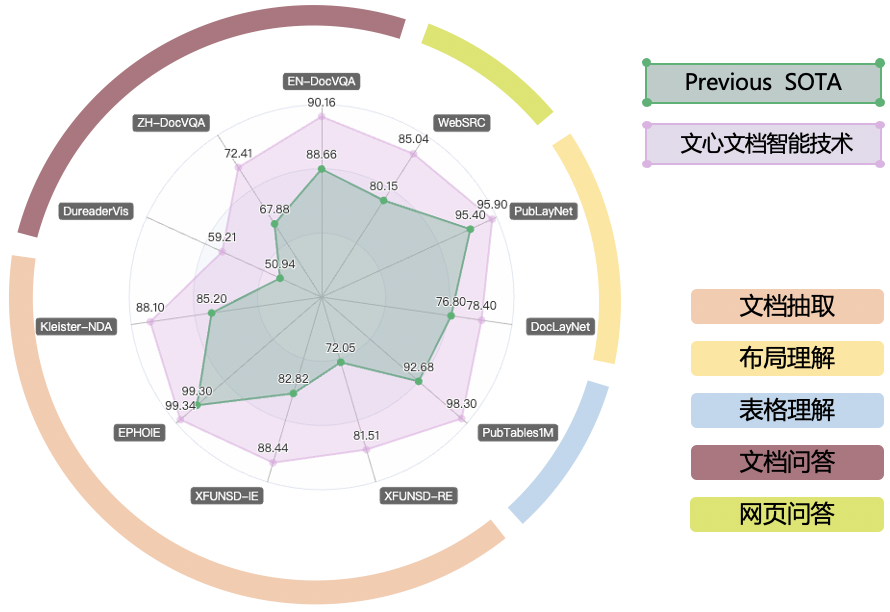
近期,百度文心文档智能,基于多语言跨模态布局增强的文档智能大模型ERNIE-Layout,刷新了五类11项文档智能任务效果。依托文心ERNIE大模型,基于布局知识增强技术,融合文本、图像、布局等信息进行联合建模,能够对多模态文档(如文档图片、PDF 文件、扫描件等)进行深度理解与分析,为各类上层应用提供SOTA模型底座。
2.2 多场景覆盖
以下是文档智能技术的一些应用场景展示:
- 发票抽取问答

- 海报抽取问答

- 网页抽取问答

- 表格抽取问答

- 试卷抽取问答

- 英文票据多语种(中、英、日、泰、西班牙、俄语)抽取问答

- 中文票据多语种(中简、中繁、英、日、法语)抽取问答

- Demo图片可在此下载
3. 快速开始
3.1 开箱即用
开源DocPrompt开放文档抽取问答模型,以ERNIE-Layout为底座,可精准理解图文信息,推理学习附加知识,准备捕捉图片、PDF等多模态文档中的每个细节。
🧾 通过Huggingface网页体验DocPrompt功能:

Taskflow
通过paddlenlp.Taskflow三行代码调用DocPrompt功能,具备多语言文档抽取问答能力,部分应用场景展示如下:
- 输入格式
[
{"doc": "./invoice.jpg", "prompt": ["发票号码是多少?", "校验码是多少?"]},
{"doc": "./resume.png", "prompt": ["五百丁本次想要担任的是什么职位?", "五百丁是在哪里上的大学?", "大学学的是什么专业?"]}
]
默认使用PaddleOCR进行OCR识别,同时支持用户通过word_boxes传入自己的OCR结果,格式为List[str, List[float, float, float, float]]。
[
{"doc": doc_path, "prompt": prompt, "word_boxes": word_boxes}
]
-
支持单条、批量预测
- 支持本地图片路径输入

>>> from pprint import pprint >>> from paddlenlp import Taskflow >>> docprompt = Taskflow("document_intelligence") >>> pprint(docprompt([{"doc": "./resume.png", "prompt": ["五百丁本次想要担任的是什么职位?", "五百丁是在哪里上的大学?", "大学学的是什么专业?"]}])) [{'prompt': '五百丁本次想要担任的是什么职位?', 'result': [{'end': 7, 'prob': 1.0, 'start': 4, 'value': '客户经理'}]}, {'prompt': '五百丁是在哪里上的大学?', 'result': [{'end': 37, 'prob': 1.0, 'start': 31, 'value': '广州五百丁学院'}]}, {'prompt': '大学学的是什么专业?', 'result': [{'end': 44, 'prob': 0.82, 'start': 38, 'value': '金融学(本科)'}]}]- http图片链接输入

>>> from pprint import pprint >>> from paddlenlp import Taskflow >>> docprompt = Taskflow("document_intelligence") >>> pprint(docprompt([{"doc": "https://bj.bcebos.com/paddlenlp/taskflow/document_intelligence/images/invoice.jpg", "prompt": ["发票号码是多少?", "校验码是多少?"]}])) [{'prompt': '发票号码是多少?', 'result': [{'end': 2, 'prob': 0.74, 'start': 2, 'value': 'No44527206'}]}, {'prompt': '校验码是多少?', 'result': [{'end': 233, 'prob': 1.0, 'start': 231, 'value': '01107 555427109891646'}]}] -
可配置参数说明
batch_size:批处理大小,请结合机器情况进行调整,默认为1。lang:选择PaddleOCR的语言,ch可在中英混合的图片中使用,en在英文图片上的效果更好,默认为ch。topn: 如果模型识别出多个结果,将返回前n个概率值最高的结果,默认为1。
3.2 产业级流程方案
针对文档智能领域的痛点和难点,PaddleNLP将持续开源一系列文档智能产业实践范例,解决开发者们实际应用难题。
更多:百度TextMind智能文档分析平台可提供包括文档信息抽取、文本内容审查、企业文档管理、文档格式解析、文档内容比对等全方位一站式的文档智能服务,已形成一套完整的企业文档场景化解决方案,满足银行、券商、法律、能源、传媒、通信、物流等不同行业和场景的文档处理需求,以AI助力企业的办公智能化升级和数字化转型。欢迎深度交流与商业合作,了解详情:https://ai.baidu.com/tech/nlp/Textanalysis
References
No Description
Python C++ Cuda Text Markdown other
Contributors (25+)
fangzeyang0904@hotmail.com
380185688@qq.com
chenzeyu01@baidu.com
zhoushunjie@baidu.com
zhonghui.net@gmail.com
40840292+linjieccc@users.noreply.github.com
yyb0576@163.com
33639025+smallv0221@users.noreply.github.com
1435130236@qq.com
sijun.he@hotmail.com
623543001@qq.com
709153940@qq.com
50394665+JunnYu@users.noreply.github.com
397551318@qq.com
w5688414@gmail.com
liujiaqi06@baidu.com
gongel@qq.com
tianxin04@baidu.com
wanghuijuan03@baidu.com
westfish@126.com
63761690+lugimzzz@users.noreply.github.com
48793257+Steffy-zxf@users.noreply.github.com
kinghuin_chull@163.com
whucsgs@163.com
chenshuo07@baidu.com