You can not select more than 25 topics
Topics must start with a chinese character,a letter or number, can include dashes ('-') and can be up to 35 characters long.
1.1 KiB
1.1 KiB
Reproduce PPO with PARL
Based on PARL, the PPO algorithm of deep reinforcement learning has been reproduced, reaching the same level of indicators as the paper in Atari benchmarks.
Include following approach:
- Clipped Surrogate Objective
- Adaptive KL Penalty Coefficient
Paper: PPO in Proximal Policy Optimization Algorithms
Mujoco games introduction
Please see here to know more about Mujoco games.
Benchmark result
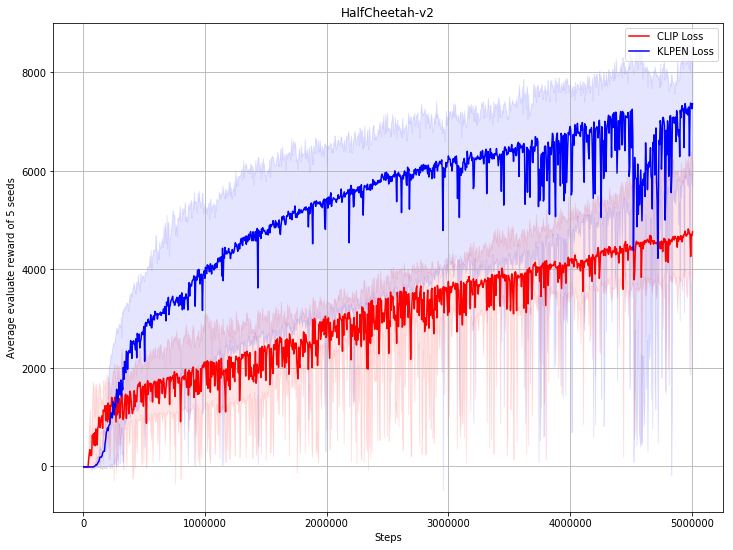
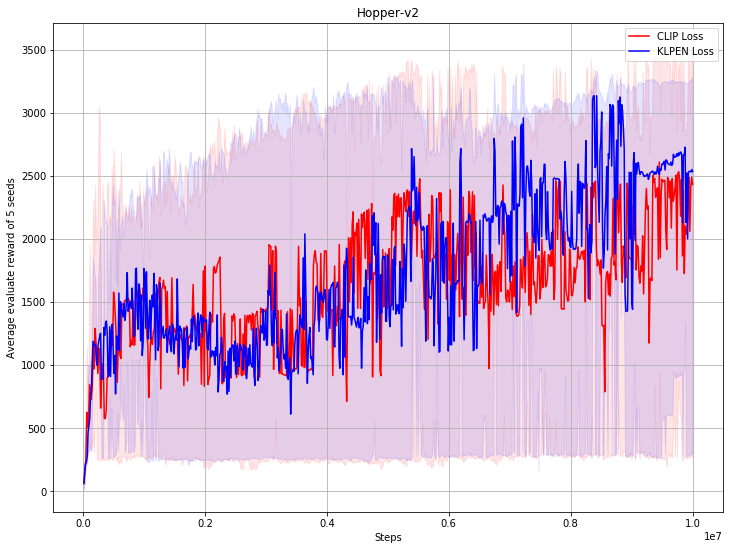
How to use
Dependencies:
- python3.5+
- paddlepaddle>=1.8.5
- parl
- gym
- tqdm
- mujoco-py>=1.50.1.0
Start Training:
# To train an agent for HalfCheetah-v2 game (default: CLIP loss)
python train.py
# To train for different game and different loss type
# python train.py --env [ENV_NAME] --loss_type [CLIP|KLPEN]