You can not select more than 25 topics
Topics must start with a chinese character,a letter or number, can include dashes ('-') and can be up to 35 characters long.
3.5 KiB
3.5 KiB
Reproduce MADDPG with PARL
Based on PARL, the MADDPG algorithm of deep reinforcement learning has been reproduced.
Paper: MADDPG in Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments
Multi-agent particle environment introduction
A simple multi-agent particle world based on gym. Please see here to install and know more about the environment.
Benchmark result
Mean episode reward (every 1000 episodes) in training process (totally 25000 episodes).
simple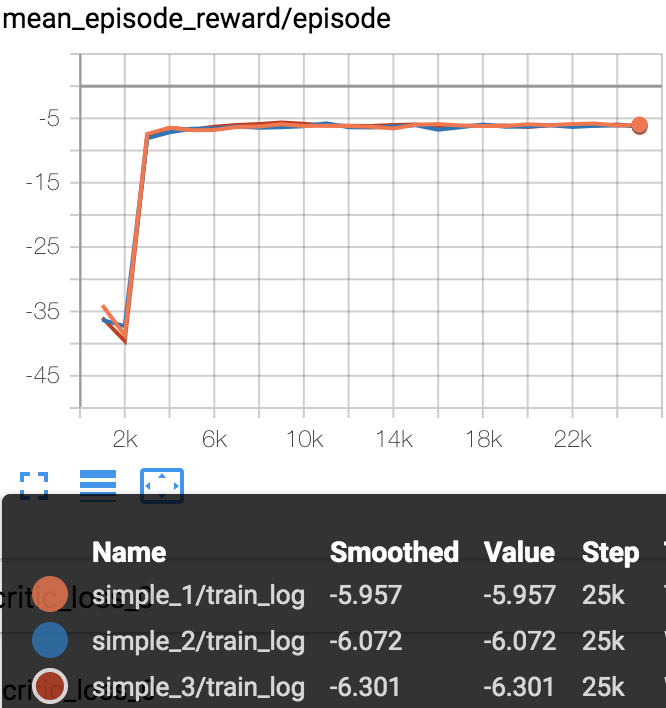
|
simple_adversary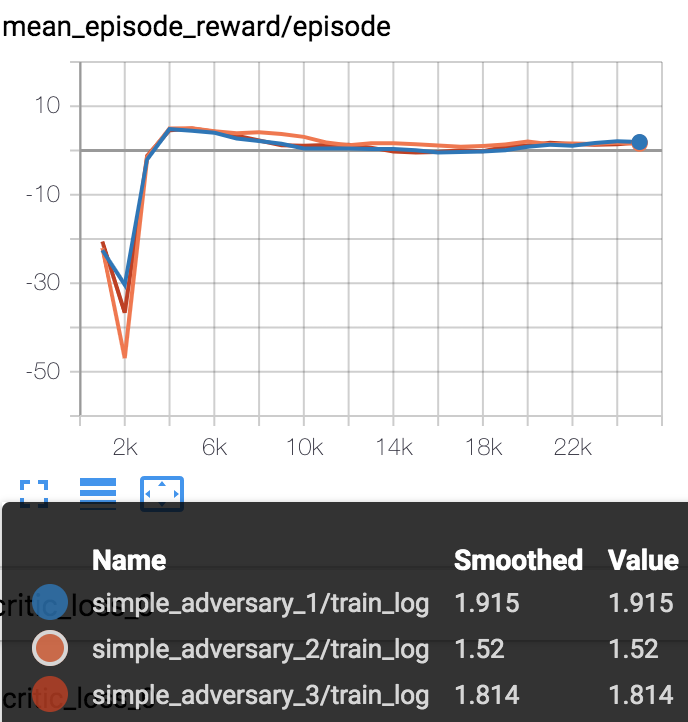
|
simple_push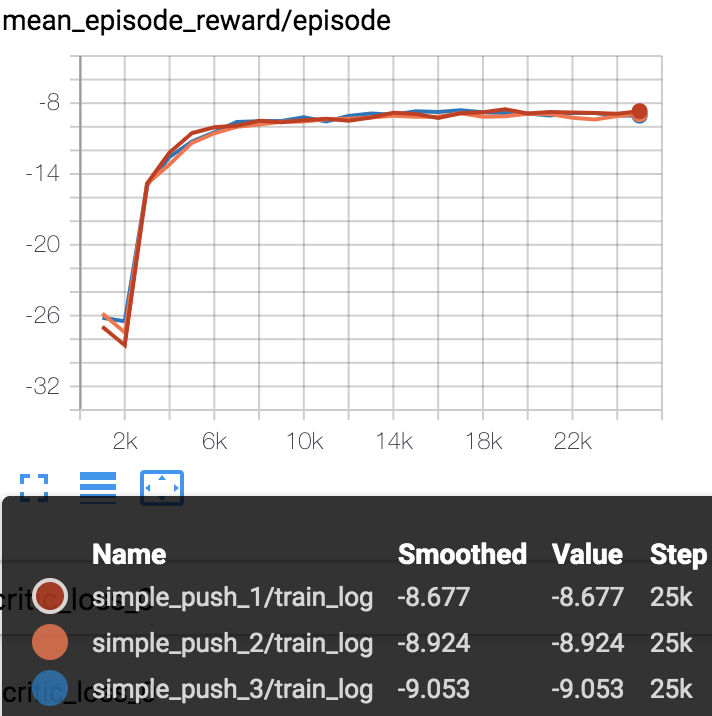
|
simple_reference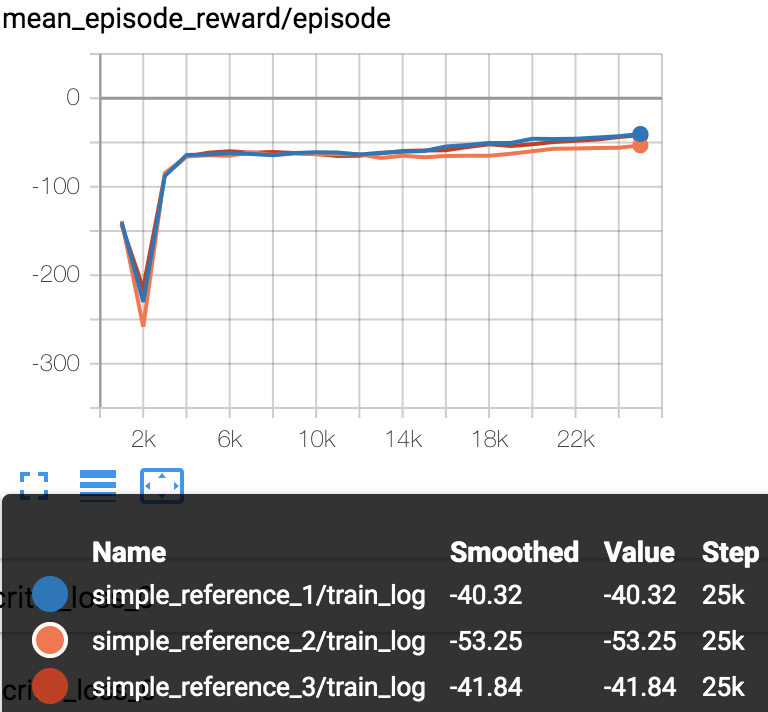
|
simple_speaker_listener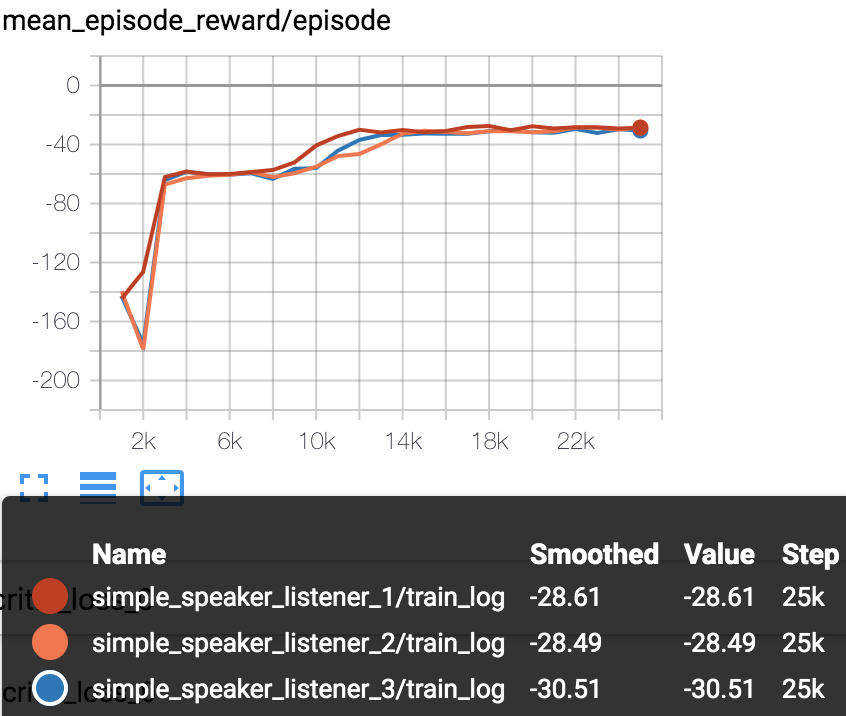
|
simple_spread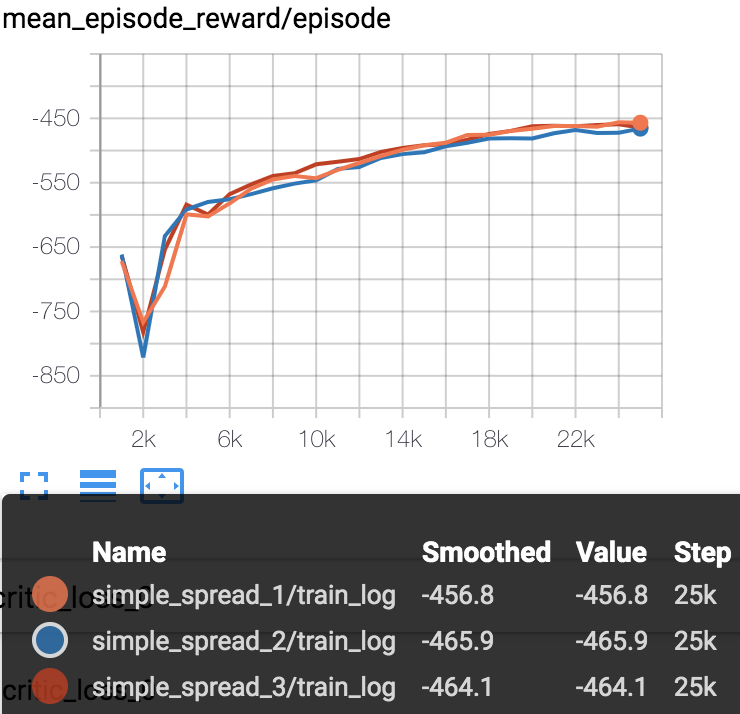
|
simple_tag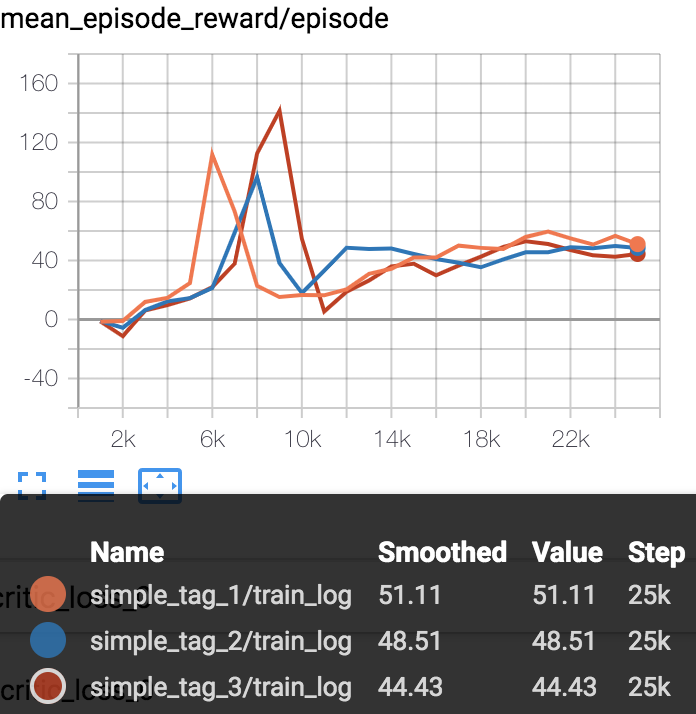
|
simple_world_comm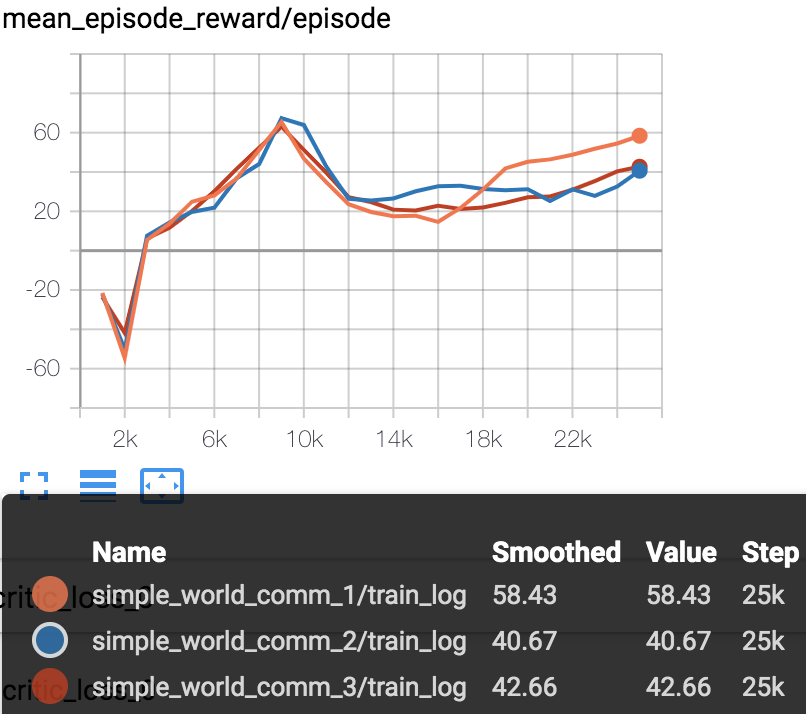
|
Experiments result
Display after 25000 episodes.
simple
|
simple_adversary
|
simple_push
|
simple_reference
|
simple_speaker_listener
|
simple_spread
|
simple_tag
|
simple_world_comm
|
How to use
Dependencies:
- python3.5+
- paddlepaddle>=1.8.5
- parl
- multiagent-particle-envs
- gym==0.10.5
Start Training:
# To train an agent for simple_speaker_listener scenario
python train.py
# To train for other scenario, model is automatically saved every 1000 episodes
# python train.py --env [ENV_NAME]
# To show animation effects after training
# python train.py --env [ENV_NAME] --show --restore