As we describe in more detail below, CLIP models in a medium accuracy regime already allow us to draw conclusions about the robustness of larger CLIP models since the models follow reliable scaling laws.
Cherti et al., 2022 and Gadre et al., 2023 show additional discussions about the scaling behavior of CLIP models.
Scaling trends
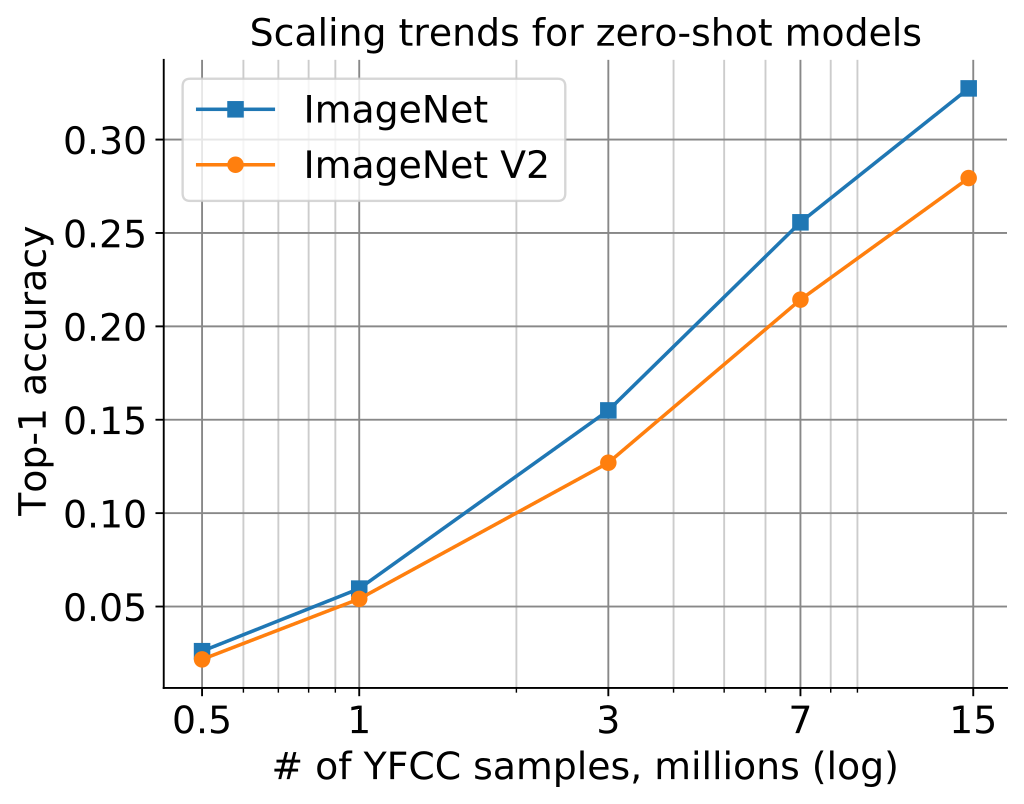
The plot below shows how zero-shot performance of CLIP models varies as we scale the number of samples used for training. Zero-shot performance increases steadily for both ImageNet and ImageNetV2, and is far from saturated at ~15M samples.
Why are low-accuracy CLIP models interesting?
TL;DR: CLIP models have high effective robustness, even at small scales.
CLIP models are particularly intriguing because they are more robust to natural distribution shifts (see Section 3.3 in the CLIP paper).
This phenomena is illustrated by the figure below, with ImageNet accuracy on the x-axis
and ImageNetV2 (a reproduction of the ImageNet validation set with distribution shift) accuracy on the y-axis.
Standard training denotes training on the ImageNet train set and the CLIP zero-shot models
are shown as stars.
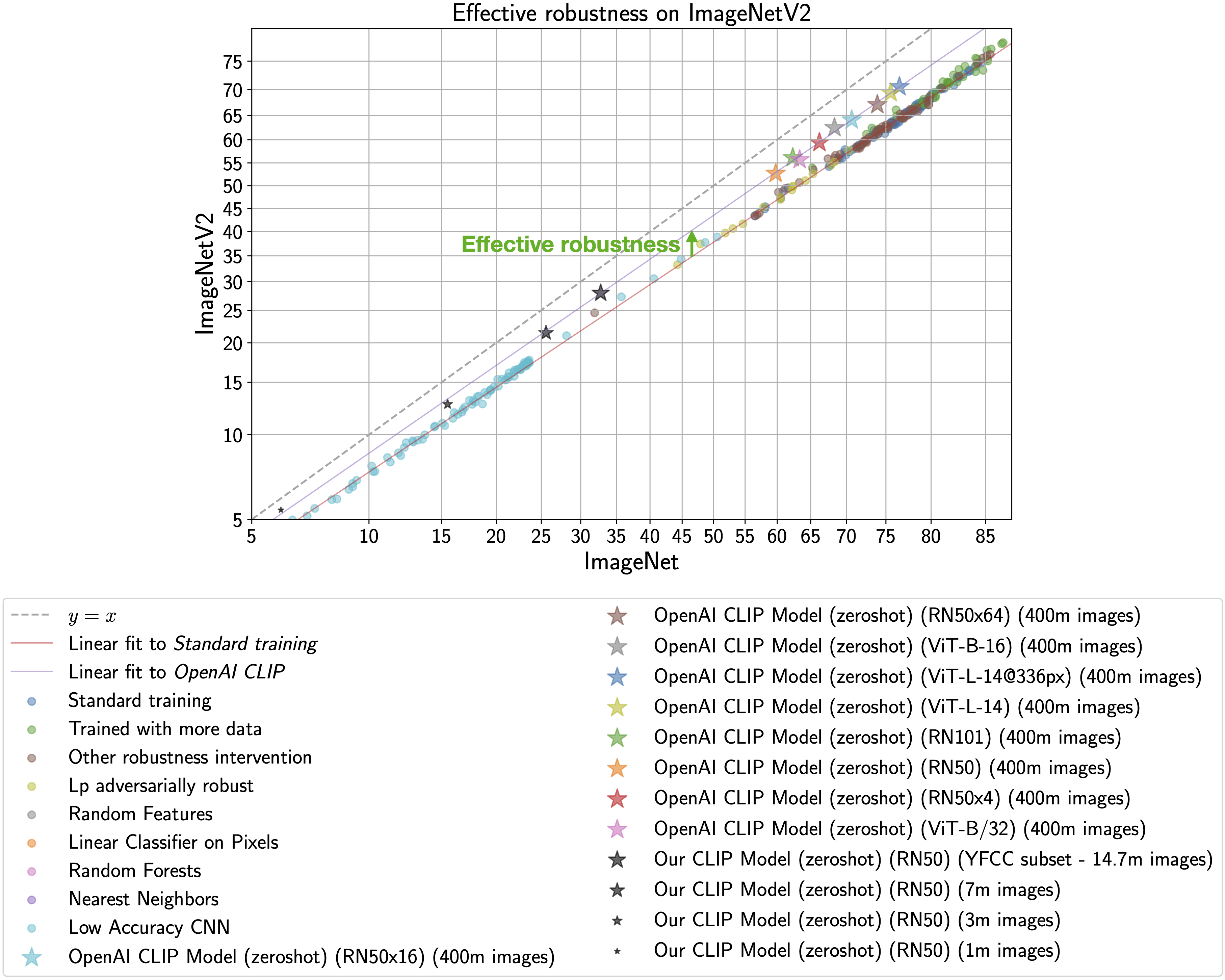
As observed by Taori et al., 2020 and Miller et al., 2021, the in-distribution
and out-of-distribution accuracies of models trained on ImageNet follow a predictable linear trend (the red line in the above plot). Effective robustness
quantifies robustness as accuracy beyond this baseline, i.e., how far a model lies above the red line. Ideally a model would not suffer from distribution shift and fall on the y = x line (trained human labelers are within a percentage point of the y = x line).
Even though the CLIP models trained with
this codebase achieve much lower accuracy than those trained by OpenAI, our models still lie on the same
trend of improved effective robustness (the purple line). Therefore, we can study what makes
CLIP robust without requiring industrial-scale compute.
For more information on effective robustness, please see:
To know more about the factors that contribute to CLIP's robustness refer to Fang et al., 2022.