简介
本仓库提供在 AI靶场 进行分布式训练样例,也可以作为其他使用Jupyter或类似交互式工具在Ascend芯片上进行分布式训练的参考
本仓库提供了一个 davincirunsdk 的简要实现(runner.py),以及一个直接使用 davincirunsdk 的版本,供用户在不同情况下选择使用,我们推荐您使用 davincirunsdk 相关包进行分布式训练
仓库结构
.
├── dataset # 数据集文件
├── mindspore # Mindspore分布式训练样例
└── tf # Ascend tf分布式训练改造和训练样例
LICENSE
如无特殊说明,本仓库采用MIT License,建议您在引入本仓库文件时检查文件是否有相关协议限制
其中,MindSpore的代码就是以Apache License, Version 2.0 协议引入的,在这里可以找到源代码
如何使用本仓库
准备工作
本仓库的数据集已使用git lfs存放在此 仓库 中,下载请参考此 仓库 文档
使用git clone或平台提供的打包下载功能可快速获得本仓库源码
$git clone https://git.openi.org.cn/Wh1isper/distrubuted-trainning-on-datai.git
在AI靶场上注册帐号并创建实验
在您首次登录 AI靶场 时,需要先进行注册,在完成注册后,可以查看平台的 帮助手册 创建实验
上传数据集和代码文件
当实验创建成功后,您将进入以下页面
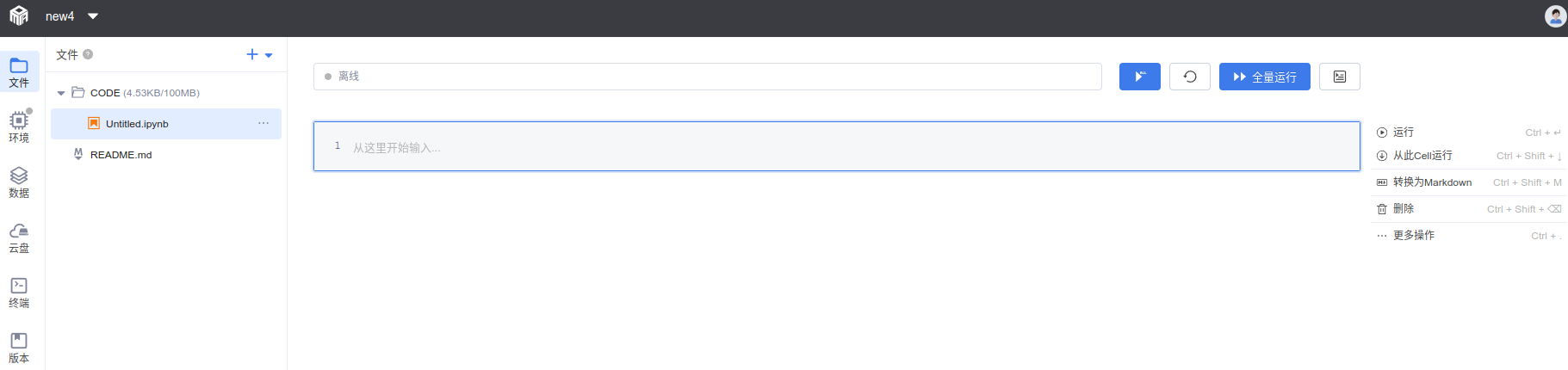
点击+号上传整个文件夹,并拖拽移动到CODE目录下,这里我们新建了一个distribute-train-example的文件夹
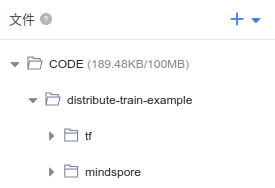
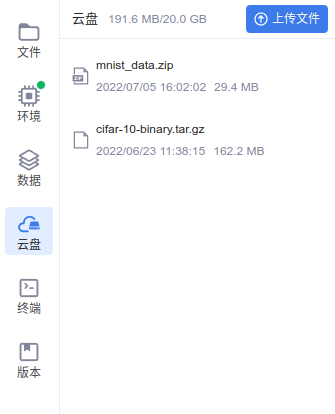
使用云盘上传数据集文件,结果如下:
进行分布式训练
在准备好训练代码和数据集之后,可以启动计算资源环境开始调试、训练代码,镜像的选择请根据所需使用的框架和 分布式计算支持 进行选择
关于框架的分布式训练细节,可以参考框架目录下的 README文件
这里我们启动了 MindSpore 1.5.1镜像,并使用了8张Ascend 910卡进行训练
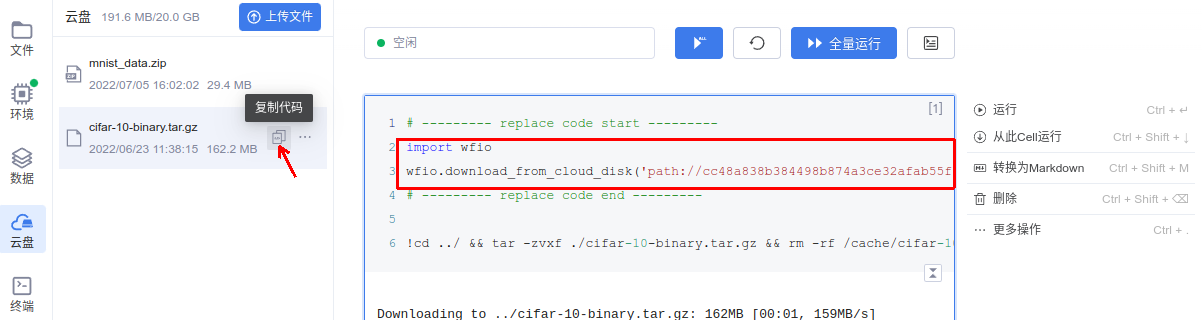
从云盘一栏中获取cifar-10数据集的下载代码,替换原有的下载代码
至此,此实验已达到就绪状态 ,直接运行全部单元格 将看到训练相关输出
将看到训练相关输出
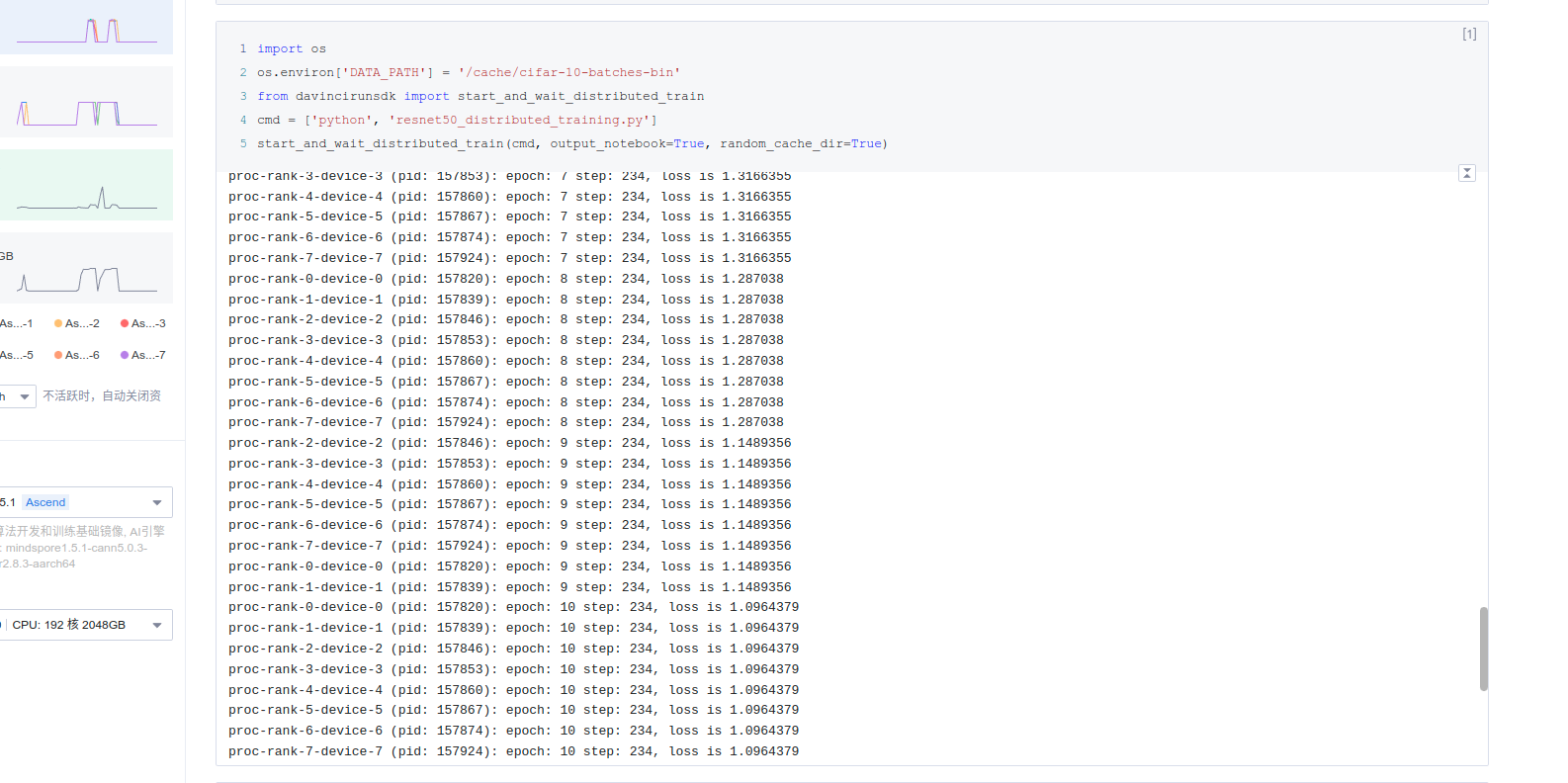
全量运行
数据分析师在实验编辑页面完成代码编辑并在样本数据上运行成功后,点击Datai页面-代码编辑区的 全量运行,该操作将当前代码发送到运行环境对相应的全量数据进行数据分析,得到基于全量数据的数据分析结果。
更多全量运行细节请参考平台文档:全量运行
注意,在您启动全量运行之前,请清理CODE文件夹下的目录,分布式训练常常生成大量算子缓存,将显著影响版本生成速度,并可能对全量运行造成影响,同时也要注意删除生成的日志、模型,以免干扰全量实验
davincirunsdk 在这一问题上可能表现的更好,建议参考sdk版本的样例
更好的实践
sh脚本支持
对于采用sh脚本运行的用户,只需要对原有脚本进行一些修改即可
MindSpore官方文档对分布式计算的样例如下:
#!/bin/bash
# applicable to Ascend
echo "=============================================================================================================="
echo "Please run the script as: "
echo "bash run.sh DATA_PATH RANK_TABLE_FILE RANK_SIZE RANK_START"
echo "For example: bash run.sh /path/dataset /path/rank_table.json 16 0"
bash run.sh /path/dataset /path/rank_table.json 16 8
echo "It is better to use the absolute path."
echo "=============================================================================================================="
execute_path=$(pwd)
echo ${execute_path}
script_self=$(readlink -f "$0")
self_path=$(dirname "${script_self}")
echo ${self_path}
export DATA_PATH=$1
export RANK_TABLE_FILE=$2
export RANK_SIZE=$3
RANK_START=$4
DEVICE_START=0
for((i=0;i<=7;i++));
do
export RANK_ID=$[i+RANK_START]
export DEVICE_ID=$[i+DEVICE_START]
rm -rf ${execute_path}/device_$RANK_ID
mkdir ${execute_path}/device_$RANK_ID
cd ${execute_path}/device_$RANK_ID || exit
pytest -s ${self_path}/resnet50_distributed_training.py >train$RANK_ID.log 2>&1 &
done
修改后的样例如下:
#!/bin/bash
# applicable to Ascend
echo "=============================================================================================================="
echo "Please run the script as: "
echo "bash run.sh DATA_PATH"
echo "For example: bash run.sh /path/dataset"
bash run.sh /path/dataset
echo "It is better to use the absolute path."
echo "=============================================================================================================="
execute_path=$(pwd)
echo ${execute_path}
script_self=$(readlink -f "$0")
self_path=$(dirname "${script_self}")
echo ${self_path}
export DATA_PATH=$1
# export RANK_TABLE_FILE=$2 # modified!
# export RANK_SIZE=$3 # modified!
RANK_START=$RANK_START # modified!
DEVICE_START=0
for((i=0;i<=7;i++));
do
export RANK_ID=$[i+RANK_START]
export DEVICE_ID=$[i+DEVICE_START]
rm -rf ${execute_path}/device_$RANK_ID
mkdir ${execute_path}/device_$RANK_ID
cd ${execute_path}/device_$RANK_ID || exit
pytest -s ${self_path}/resnet50_distributed_training.py >train$RANK_ID.log 2>&1 &
done
下表指出了平台提供的环境变量,用户自行配置的变量需要用户根据RANK_TABLE_FILE指向的hccl文件进行配置,在全量运行时需要遵循平台配置的内容,擅自覆盖可能会导致运行失败
更多环境变量配置可参考 davincirunsdk实现 ,有任何环境变量请求可在 davincirunsdk 提出 issue
|
调试环境 |
运行环境 |
| RANK_TABLE_FILE |
平台配置 |
平台配置 |
| RANK_ID |
用户自行配置 |
用户根据RANK_START进行配置 |
| RANK_START |
用户自行配置 |
平台配置 |
当一切就绪后,可以在ipynb中使用 ! magic命令执行sh脚本,示例如下:
!source ~/.bashrc; cd ./distributed_training; chmod +x ./run.sh; ./run.sh /cache/cifar-10-batches-bin
迁移sh脚本至davincirunsdk
直接使用sh脚本有如下问题:
- 无法在notebook内显示训练日志
- 无法捕获执行错误,全量运行一定会成功
- 环境变量配置繁琐
因此我们推荐使用 davincirunsdk 进行分布式训练,在上文的案例中,实际上执行训练的文件是 resnet50_distributed_training.py,而数据集实际通过 DATA_PATH环境变量传递,则使用以下代码可以快速开始分布式训练,davincirunsdk将通过当前机器的hccl文件和相应环境变量自行识别当前机器,启动与本机卡数相当的训练进程,并为每个进程配置对应的 RANK_ID, DEVICE_ID
import os
os.environ['DATA_PATH'] = '/cache/cifar-10-batches-bin'
from davincirunsdk import start_and_wait_distributed_train
cmd = ['python', 'resnet50_distributed_training.py']
start_and_wait_distributed_train(['python', 'train_cluster.py'], output_notebook=True)
AI靶场SDK实践指导
为方便调试,AI靶场提供了一些接口来监测训练过程中的指标变化:全量运行代码调用
在分布式训练中,由于同一份代码并行执行,同名指标将存在互相覆盖的问题,这里推荐使用 RANK_ID作为附加标识,则可以正确获得所有训练副本的指标数据。
# 导入指标记录模块 wflogger
from wf_analyse.analyse import wflogger
import os
# 记录单个参数
wflogger.log_param(name=f"learning-{os.getenv('RANK_ID', 'no-rank')})", value=0.01)
靶场分布式计算支持
靶场建设于云脑2算力之上,已知限制如下:
|
调试环境(单机多卡) |
运行环境(单机多卡) |
运行环境(多机多卡) |
| MindSpore 1.5.1 |
不再官方支持 |
不再官方支持 |
不再官方支持 |
| MindSpore 1.7.0 |
支持 |
支持 |
支持 |
| Tensorflow 1.15 |
支持 |
支持 |
支持 |
| MindSpore 1.8.1 |
支持 |
支持 |
支持 |