PCL-Tongyan
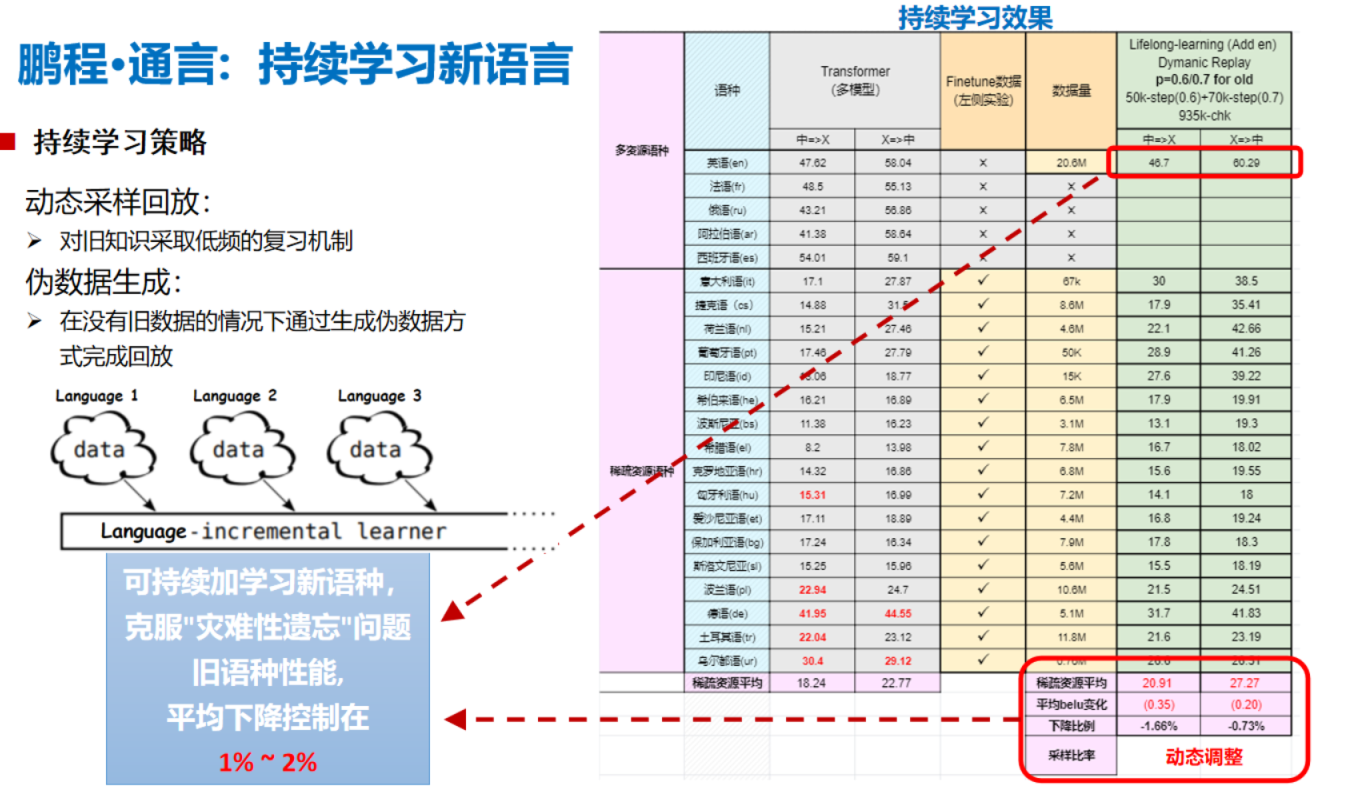
鹏程-通言多语言机器翻译模型,单模型支持一带一路17种小语种和中文互译。通言模型是在M2M-100模型结构上进行改进的多语种机器翻译模型,通过参数复用和增量式训练,将模型参数从1.2B提升至13.2B,在一带一路多个小语种的翻译上大幅提升。使用动态回放的终身学习方法,通言模型可持续学习新的语种翻译,详见PTT。
模型结构

<img src="./images/model_strcture.png"/>
模型特性
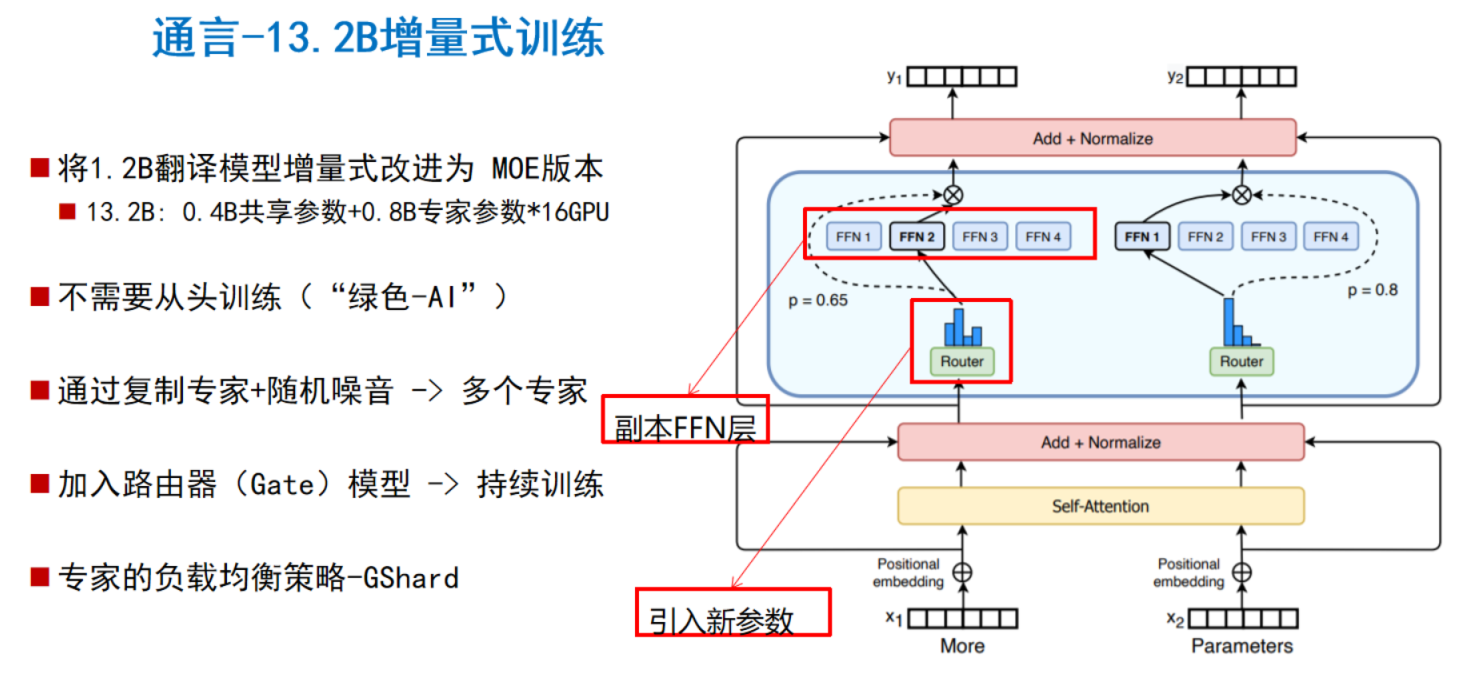
1.将M2M 1.2B模型增量式改进为混合专家版本
2.增量式训练,减少计算消耗,符合当下“绿色-AI”。
3.通过复制专家+随机噪音 -> 多个专家
4.采用基于动态回放的可持续学习方案,支持持续学习新语种
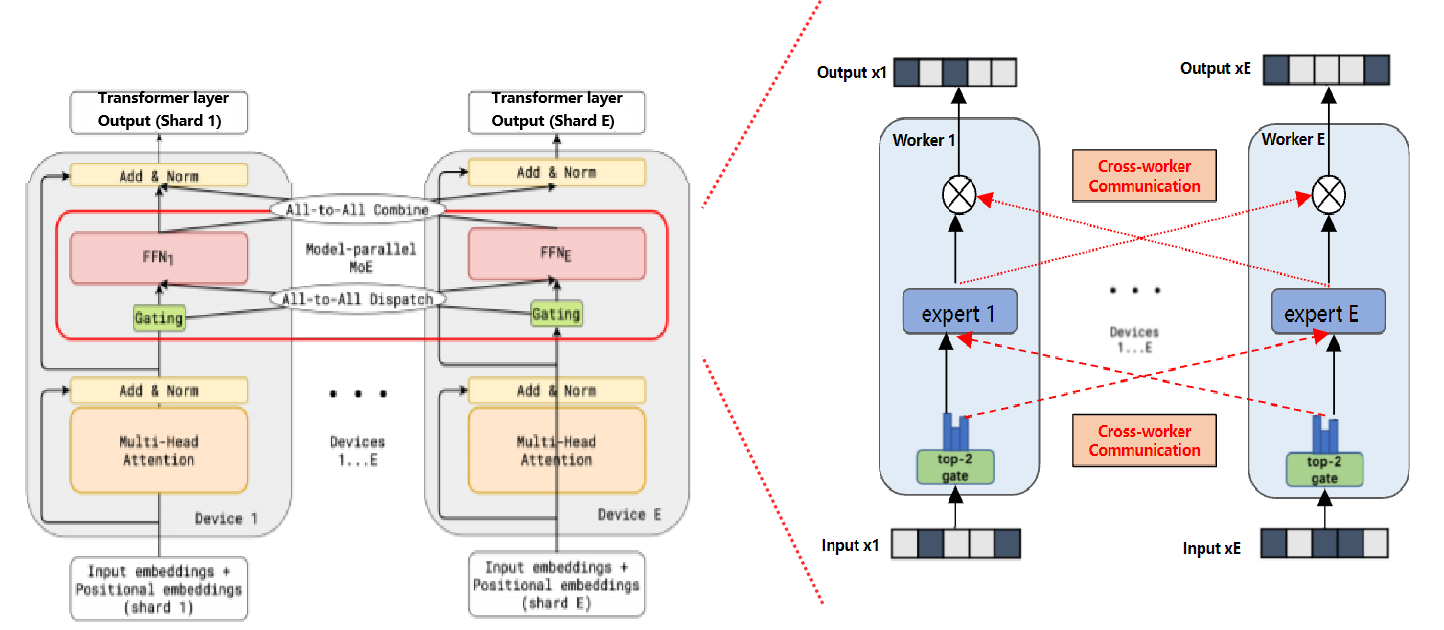
5.多卡多专家,16张V100显卡进行数据与专家混合并行,提升资源利用效率
6.模型基于fairseq和fastmoe实现,训练快速且部署简易
7.单卡多专家,无需卡间通讯,大幅提升推断速度
增量式训练原理
数据来源
https://git.pcl.ac.cn/PCMachineTranslation/PCMT/src/branch/master/datasets
数据统计信息见Excel
训练步骤
1. 按照官方说明安装fairseq和fastmoe (我是在nvcr.io/nvidia/pytorch:21.06-py3 docker环境下安装的,也可以bash sh_dir/Install_fair.sh进行安装)
2. 将PCL-Tongyan目录下所有文件复制到 fairseq 安装目录下(要覆盖)
3. 下载"丝路"数据集 https://git.pcl.ac.cn/PCMachineTranslation/PCMT/src/branch/master/datasets
4. 处理数据(修改目录) bash sh_dir/process.sh
5. 下载m2m-100的dict文件和checkpoint文件 https://github.com/pytorch/fairseq/tree/master/examples/m2m_100
6. 将m2m-100转为MOE模型 python Change_1.2B_To_16Moe_Version.py
7. 开始增量式MOE训练 sh_dir/Train-16moe-SiLu-Inhert.sh
单卡推理步骤(需要32G显存)
1. 将分布式MOE模型转为单卡存储 uer_dir/Comerge_16To1.py
2. xx->zh/h->xx 测试bleu sh_dir/Test-16Moe-multi-silu.sh
功能指令
# 普通模型 转 MOE模型
python Change_1.2B_To_16Moe_Version.py
# 分布式MOE模型转单卡存储
python Comerge_16To1.py
# 多语言微调
bash sh_dir/Train-16moe-SiLu-Inhert.sh 16 GShardGate 2
# 测试 xx-zh/zh-xx翻译结果
bash sh_dir/Test-16Moe-multi-silu.sh 0 xx
# 处理数据脚本
bash sh_dir/process.sh
服务调用API
import requests
def Tongyan_Translate(sentences=None,direction=None,PyTorch_REST_API_URL = 'http://192.168.202.124:5000/predict'):
c_lgs=['中文(zh)','意大利语(it)','德语(de)','捷克语(cs)','荷兰语(nl)','葡萄牙语(pt)','印尼语(id)','保加利亚语(bg)','波斯尼亚(bs)',
'波斯尼亚(bs)','希腊语(el)','波斯语(fa)','克罗地亚语(hr)','匈牙利语(hu)','爱沙尼亚语(et)','希伯来语(he)',
'斯洛文尼亚(sl)','波兰语(pl)','土耳其语(tr)','乌尔都语(ur)']
lgs=['zh','it','de','cs','nl','pt','id','bg','bs','bs','el','fa','hr','hu','et','he','sl','pl','tr','ur']
src,tgt=direction.split("-")
if src not in lgs or tgt not in lgs:
print(f"参数<direction>请在下面集合中的语言按照xx-xx的格式输入: \n{','.join(c_lgs)}")
return None
else:
payload = {'data': [direction,sentences]}
# Submit the request.
r = requests.post(PyTorch_REST_API_URL, data=payload).json()
if r['success']:
translations=[sent for sent in enumerate(r['predictions'])]
return translations
else:
return None
if __name__ == '__main__':
sentences = ["我要吃苹果","今天真是好天气!","哈喽,我是PCL的高级工程师XXX,请多指教!"]
direction = "zh-pt"
res=Tongyan_Translate(sentences=sentences,direction=direction)
print(res)
依赖环境
fairseq 1.0.0a0+2fd9d8a
fastmoe 0.2.0
模型性能
多语言机器翻译

持续学习性能