{kind=link}
Are you sure you want to delete this task? Once this task is deleted, it cannot be recovered.
You can not select more than 25 topics
Topics must start with a chinese character,a letter or number, can include dashes ('-') and can be up to 35 characters long.
 王凯
d678b8405a
王凯
d678b8405a
|
1 year ago | |
|---|---|---|
| README.md | 1 year ago | |
| main.ipynb | 1 year ago | |
| output_19_0.png | 1 year ago | |
README.md
1.序列召回基础
我们在学习了Paddle的基本使用之后,我们就得进入到我们的主题了:序列召回。我们这一次的学习内容主要围绕着序列召回展开,下面我们首先给大家介绍一下推荐系统以及和序列召回相关的前置知识。
1.1 推荐系统简介
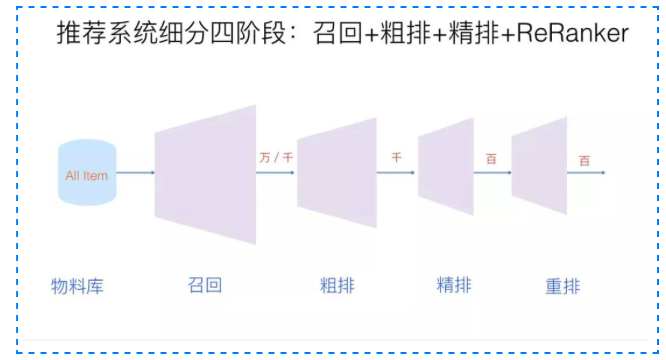
推荐系统时时刻刻都在我们身边,例如:商品推荐,内容推荐,视频推荐等等。推荐系统的出现极大的降低了人们在互联网上信息获取的速度,可以帮助人们快速的从互联网的巨量数据中获取到喜欢的内容。那我们首先需要明确一个推荐系统在客户角度的输入以及输出,我们可以简单的认为推荐系统的输入就是用户的请求,然后推荐系统会从他所有的Item 库中,筛选出Top-K个Item推荐给用户,展现在用户的手机/电脑/网页上,这就是推荐系统给用户完成一次推荐的流程。但是实际上这种做法是不可取的,这是由于一个成熟的推荐系统,其Item库的体量是非常大的,如果直接对用户从全量的Item库中进行筛选,那将会耗费极大的计算资源,同样的也会极大的增加给用户推荐的耗时,这也会极大的降低用户的使用体验。所有在实际的使用过程中,我们采用一种“漏斗”的形式,将算法分为多个阶段来进行推荐,如下图所示:
可以看到,我们通过不同阶段的算法将这一过程切分成了不同的阶段,这张图上我们将推荐算法分为了三个阶段
-
召回:待计算的候选集合大、计算速度快、模型简单、特征较少,尽量让用户感兴趣的物品在这个阶段能够被快速召回,即保证相关物品的召回率。常用的有多路召回(即多种策略进行召回),embedding向量召回
-
精排:首要目标是得到精准的排序结果。需要处理的物品数量少,可以利用较多的特征,使用比较复杂的模型
-
重排:为了避免排序阶段的结果趋于同质化,让用户有更好的体验,这里对排序的结果进行多样化考虑,提高用户的使用体验
我们这一期的重点就是在召回算法中的序列召回,我们下面先介绍召回算法,然后进一步介绍序列召回
1.2 推荐系统中的召回
由于召回算法是面对全部的Item进行计算筛选的,所以我们的召回算法的核心特点如下:
- 算法结构简单
- 计算效率高
- 准确率不需要太高
- 每一种召回算法都会针对性解决某一类问题
可以认为,正是由于召回算法需要从全部的Item中进行计算筛选,所以导致了召回算法的效率一定是最高的,即在召回阶段我们往往对计算效率要求极高,在保证计算效率的基础上再尽可能提高召回的精度。那召回算法一般可以分为哪些类别呢?一般的,我们可以将召回算法分为以下类别:
- 基于规则
- 基于协同过滤
- 向量召回
更近一步的,我们具体针对这三大类流派进行更深入的介绍:
1.2.1 基于规则的召回算法
基于规则的召回算法比较好理解,就是我们通常的一些运营规则,例如:
- 召回点击次数最多的Item
- 召回购买次数最多的Item
- 召回购买金额最多的Item
- 召回地域最热的Item
- ......
可以看出这种召回算法属于最原始的笨办法,但是这种方法虽然在算法层面的技术难度不高,但是要做出一个非常优秀的策略也是需要极强的业务理解以及极大的人力投入的。
1.2.2 基于协调过滤的召回算法
基于协调过滤的方法有以下的两个大流派:
- 基于统计的协同过滤
- 基于MF(Matrix Factorization)的协同过滤
首先我们讨论一下基于统计的协同过滤模型,这种模型是完全基于用户行为记录的统计信息的,不涉及机器学习/深度学习模型的建模以及训练,在基于统计的协同过滤中,一般按照视角分为两种协同过滤模型
- 基于User的协同过滤
- 基于Item的协同过滤
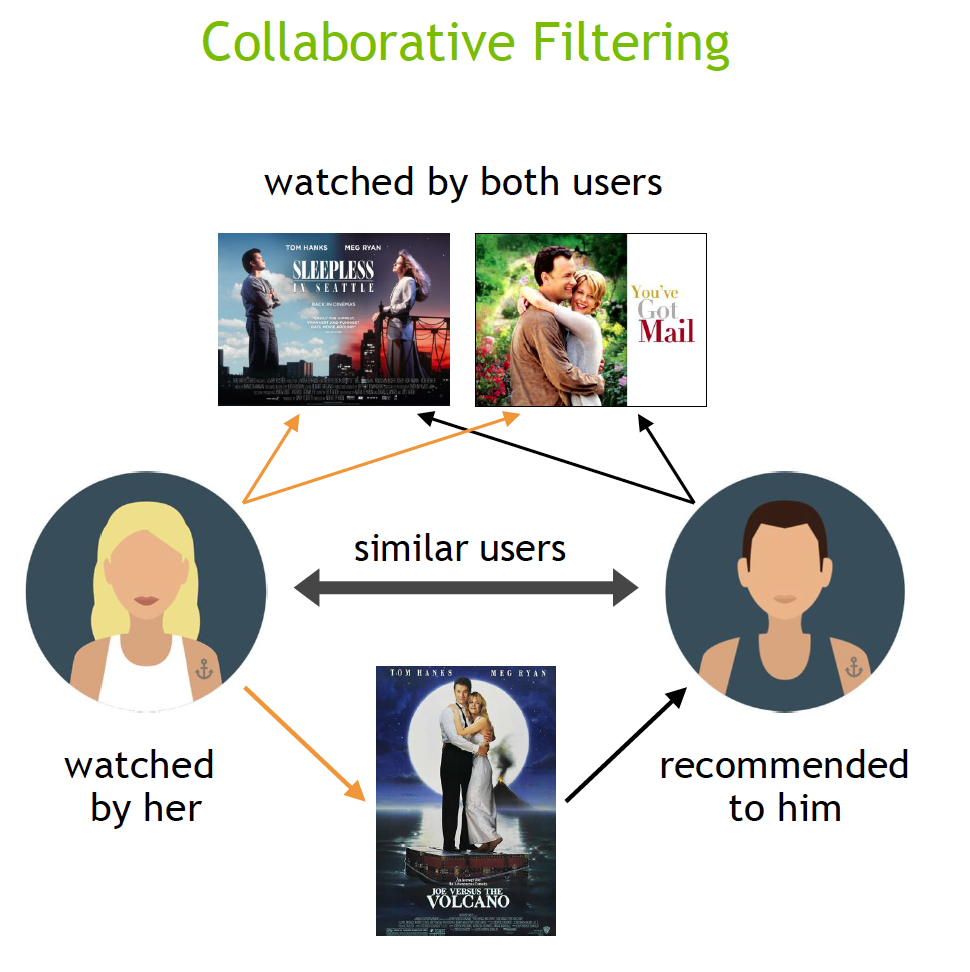
这两个协同过滤模型的核心思想是统一的,对于基于User的协同过滤模型而言,其核心的假设是:相似的用户可能喜欢相同物品。这一点当然十分符合我们的直观感受了,实际上就是将用户喜欢的商品推荐给和这个用户相似的用户,那这里的重点就落在了如何“度量”两个用户的相似度,这里的方法就有很多了,最直观的做法就是统计两个用户共同喜欢的Item的个数,如果两个用户共同喜欢的Item个数越多,那是不是就代表着两个用户就“越相似”,当然了,核心思路是这样的,但是在实际的计算过程中会加一些系数修正。
那么对于基于Item的协同过滤也一样,其核心的假设是:相似的物品可能被同个用户喜欢。我们会对推荐用户喜欢的Item的相似Item,那我们这里的核心其实就是“度量”两个Item的相似度,这里的最直观的做法就是:统计两个Item被用户同时喜欢的次数,可以简单的认为如果两个Item同时在用户喜欢列表中出现的次数越多,就可以认为这两个Item相似,当然了实际实现的时候也会加一些修正系数。
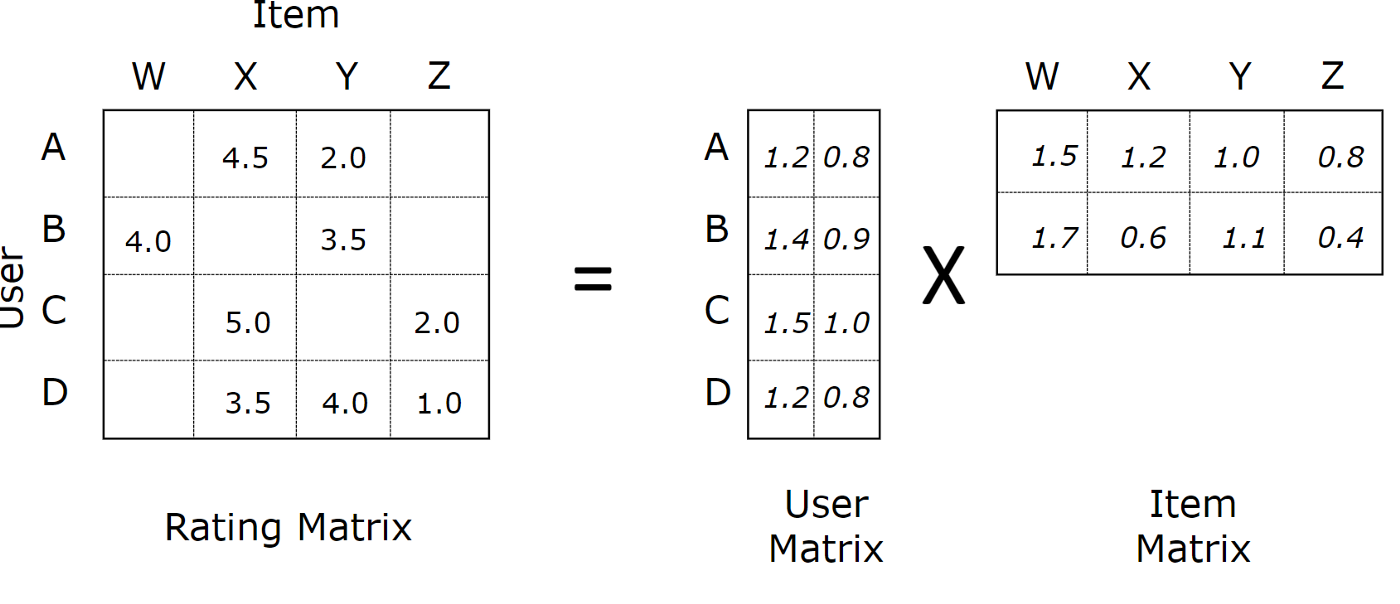
基于MF的协同过滤模型相当于是在基于User-Item的交互矩阵的基础上进行分解的,其示意图如下:
其实也可以简单的认为我们通过Embedding方法对User/Item分别学习到一个向量表征,然后使用内积的方法来计算User-Item的交互概率
1.2.3 基于向量的召回算法
基于向量的召回算法算是大量需要深度学习的一个召回算法的流派了,其主要可以分为一下流派:
- I2I:计算item-item相似度,用于相似推荐、相关推荐、关联推荐
- U2I:基于矩阵分解,直接给用户推荐item
- U2U2I:基于用户的协同过滤,先找相似用户,再推荐相似用户喜欢的item
- U2I2I:基于物品的协同过滤,先统计用户喜爱的item,再推荐他喜欢的item
- U2TAG2I:基于标签偏好推荐,先统计用户偏好的tag,然后匹配所有的item;其中tag一般是item的标签、分类、关键词等。
- X2X2X2X:......
其中这里用的最多的就是I2I和U2I这两类算法,其中基于I2I的召回算法大致有如下两个流派:
- Item-Item相似度可以通过内容理解来生产Item向量,通过向量相似度来度量
- Item-Item相似度可以通过图表示学习/GNN来生产Item向量,通过向量相似度来度量
这里的I2I向量召回的核心就是通过某种算法生产出Item的向量表征,然后通过向量的相似度来进行召回,那这个时候就有人要问了,在进行向量相似度召回的时候不也是挨个遍历计算相似度嘛~这个计算量不会很大吗?这个乍一看确实计算量很大,但是万能的开源社区有了很多对于向量检索的开源方案,这些开源方案针对向量检索进行了极大的效率优化,可以支持我们进行快速的向量检索,这里我们在后续的代码实践部分就使用了非常出名的一个开源:Faiss,Faiss可以帮助我们快速的在大规模向量中找出和Query向量最相似的Top-K个向量,这就解决了我们向量召回计算效率的问题。在有了Faiss这类向量加速检索的开源工具之后,我们就可以通过生产向量来进行大规模的召回检索啦!(我们后续有机会会介绍基于图表示学习/GNN的召回方法,这里就不多做介绍了)
基于U2I的召回算法大致有如下两个流派:
- 输入User特征和Item特征,直接对齐User与Item的向量表征
- 通过User的历史序列提取User的向量表征,然后和Item的表征对齐
这里第一种方法通过对齐User和Item特征的向量空间的方法一般是一些双塔模型,例如:DSSM
第二种方法通过提取用户的序列特征来生产User的向量表征,然后将User的向量在全部的Item向量中进行召回,这就是我们这次学习的主角了:序列召回!,这里的核心大家应该也看出来了,其实核心就在两个点:
- 序列信息的利用以及系列特征的提取
- 如何通过序列构建User的向量表征
这次学习过程中,我们会给大家介绍几篇经典论文来帮助大家快速的对序列召回这个领域的相关工作有一个快速的认识
1.3 基于GRU4Rec的基础序列召回
我们这里以GRU4Rec为例给大家介绍序列召回的全流程逻辑,当然在第二部分会有代码实践部分
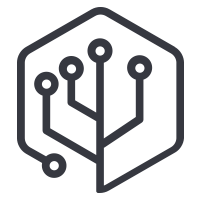
1.3.1 GRU
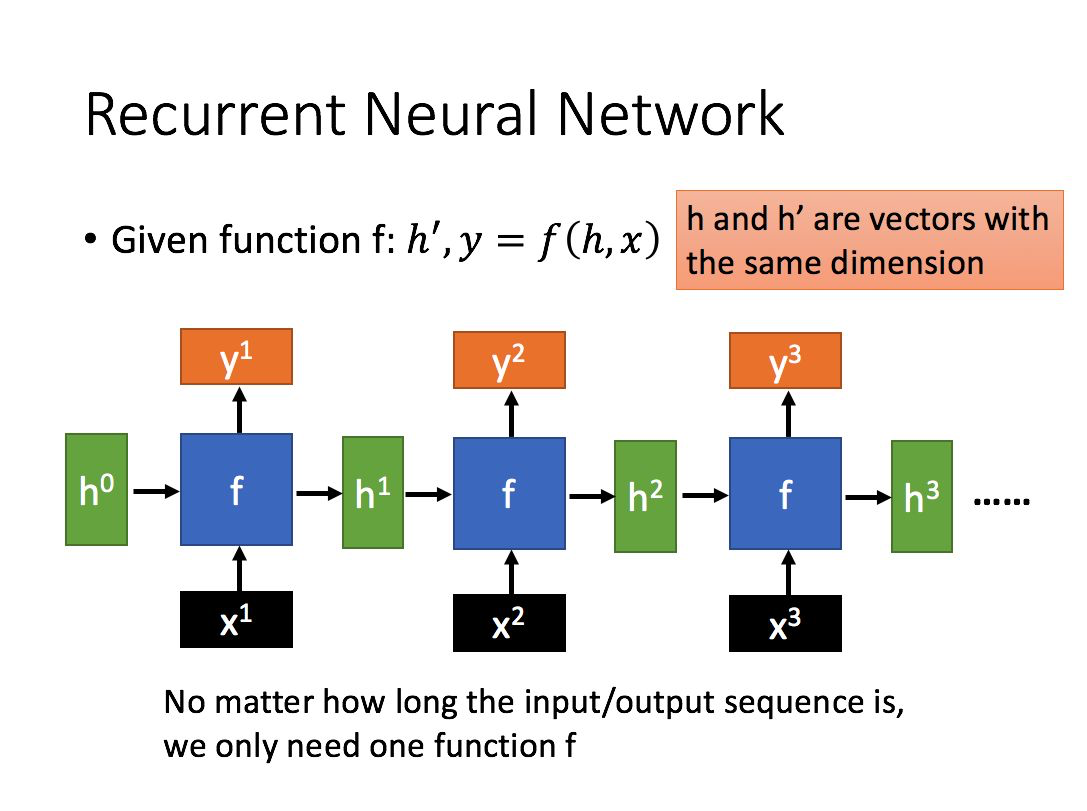
这里首先我们明确一下对于一个一般的RNN模型我们的输入和输出是什么,由上图可以看出,我们对RNN输入一个序列 $ X = [x^1,x^2,...,x^n] $ ,这里需要注意,我们序列中的每一个节点都是一个向量,那么我们的RNN会给我们的输出也是一个序列 $ Y = [y^1,y^2,...,y^n] $, 那我们如何通过RNN提取出输入序列的特征呢,这里常用的做法有两种:
- 取出$ y^n $的向量表征作为序列的特征,这里可以认为 $y^n$ 包含了 $x^1,x^2,...,x^n$ ,的所有信息,所有可以简单的认为$y^n$的结果代表序列的表征
- 对每一个时间步的特征输出做一个Mean Pooling,也就是对$ Y = [y^1,y^2,...,y^n] $ 做均值处理,以此得到序列的表征
这里我们选择第一种方法来获取序列表征,在明确了RNN的一般处理机制之后,我们就会发现,RNN中可以操作的主要集中在对每个时间步$i$信息和前$i-1$信息的处理上,这就衍生出LSTM,GRU等一系列方案,下面我们给出GRU的计算逻辑,大家可以自行研究,我们这里就不多做介绍
1.3.2 基于GRU的序列召回
a.模型训练部分
我们这里首先对Item进行Embedding操作,这里的Embedding层可以认为是一张表,他内部存储的是每一个Item ID到其向量表征的映射,例如:我有10个Item,我想对每个Item表征成一个4维的向量,那么我们可以有如下的Embedding层:
emb_layer = nn.Embedding(10,4) #声明一个10个Item,维度为4的Embedding表
query_index = paddle.to_tensor([1,0,1,2,3]) #比如我查询index为 [1,0,1,2,3]的向量
print(emb_layer.weight) # 可以看出embedding内部的存储是一个10x4的二维矩阵,其中每一行都是一个4维的向量,也就是一个item的向量表征
print(emb_layer(query_index)) # 查询结果却是是对应index对应在embedding里面的行向量
输出为:
Parameter containing:
Tensor(shape=[10, 4], dtype=float32, place=Place(cpu), stop_gradient=False,
[[ 0.48999012, 0.23852265, -0.24145952, 0.57672238],
[-0.09576172, 0.08986044, -0.63121289, -0.02598906],
[-0.44023734, 0.31829000, -0.65259022, -0.31957576],
[ 0.37807786, -0.14285791, -0.29132205, 0.50795472],
[ 0.49052703, -0.49909633, -0.55534846, 0.17601246],
[-0.49354345, 0.61451089, 0.12685758, 0.37117445],
[ 0.62036407, -0.59030831, -0.55749607, -0.58575040],
[ 0.18010908, 0.34986722, -0.10237777, -0.34165010],
[ 0.17282718, -0.58883876, -0.33249515, 0.11425638],
[-0.01826757, 0.17947799, -0.21948734, -0.17575613]])
Tensor(shape=[5, 4], dtype=float32, place=Place(cpu), stop_gradient=False,
[[-0.09576172, 0.08986044, -0.63121289, -0.02598906],
[ 0.48999012, 0.23852265, -0.24145952, 0.57672238],
[-0.09576172, 0.08986044, -0.63121289, -0.02598906],
[-0.44023734, 0.31829000, -0.65259022, -0.31957576],
[ 0.37807786, -0.14285791, -0.29132205, 0.50795472]])
在获取Item的Embedding向量之后,我们就对序列进行GRU特征提取,这里要注意,我们选择的是GRU输出的最后一个节点的向量,我们将这个向量作为序列整体的特征表达,核心代码如下:
seq_emb = self.item_emb(item_seq)
seq_emb,_ = self.gru(seq_emb)
user_emb = seq_emb[:,-1,:] #取GRU输出的最后一个Hidden作为User的Embedding
在得到用户的向量表征之后就好办了,这里直接通过多分类进行损失计算,多分类的标签就是用户下一次点击的Item的index,我们直接通过User的向量表征和所有的Item的向量做内积算出User对所有Item的点击概率,然后通过Softmax进行多分类损失计算,核心代码如下:
def calculate_loss(self,user_emb,pos_item):
all_items = self.item_emb.weight
scores = paddle.matmul(user_emb, all_items.transpose([1, 0]))
return self.loss_fun(scores,pos_item)
在可以计算模型的Loss之后,我们就可以开始训练模型了~~~
b.模型验证
我们这里给大家提供的数据集是:Movielens-20M,我们对其按照User进行了数据划分,按照8 1的比例做成了train/valid/test数据集,对于测试阶段,我们选择用户的前80%的行为作为序列输入,我们的标签是用户后20%的行为,那这里就涉及到我们前面所说的使用Faiss进行向量召回了,我们来详细看一下这个流程:
1的比例做成了train/valid/test数据集,对于测试阶段,我们选择用户的前80%的行为作为序列输入,我们的标签是用户后20%的行为,那这里就涉及到我们前面所说的使用Faiss进行向量召回了,我们来详细看一下这个流程:
# 第一步:我们获取所有Item的Embedding表征,然后将其插入Faiss(向量数据库)中
item_embs = model.output_items().cpu().detach().numpy()
item_embs = normalize(item_embs, norm='l2')
gpu_index = faiss.IndexFlatIP(hidden_size)
gpu_index.add(item_embs)
# 第二步:根据用户的行为序列生产User的向量表征
user_embs = model(item_seq,mask,None,train=False)['user_emb']
user_embs = user_embs.cpu().detach().numpy()
# 第三步:对User的向量表征在所有Item的向量中进行Top-K检索
D, I = gpu_index.search(user_embs, topN) # Inner Product近邻搜索,D为distance,I是index
当然了,,上面的只是流程中的核心代码,只能给大家一个核心思路,具体的代码实现见 2.4 基于Faiss的向量召回,至此我们就完成了模型的验证,也就顺利的完成了我们的全流程了!!!
2.代码实践
!pip install faiss
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting faiss
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/ef/2e/dc5697e9ff6f313dcaf3afe5ca39d7d8334114cbabaed069d0026bbc3c61/faiss-1.5.3-cp37-cp37m-manylinux1_x86_64.whl (4.7 MB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m4.7/4.7 MB[0m [31m3.3 MB/s[0m eta [36m0:00:00[0m00:01[0m00:01[0m
[?25hRequirement already satisfied: numpy in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from faiss) (1.19.5)
Installing collected packages: faiss
Successfully installed faiss-1.5.3
[1m[[0m[34;49mnotice[0m[1;39;49m][0m[39;49m A new release of pip available: [0m[31;49m22.1.2[0m[39;49m -> [0m[32;49m22.3[0m
[1m[[0m[34;49mnotice[0m[1;39;49m][0m[39;49m To update, run: [0m[32;49mpip install --upgrade pip[0m
import paddle
from paddle import nn
from paddle.io import DataLoader, Dataset
import paddle.nn.functional as F
import pandas as pd
import numpy as np
import copy
import os
import math
import random
from sklearn.metrics import roc_auc_score,log_loss
from sklearn.preprocessing import normalize
from tqdm import tqdm
from collections import defaultdict
from sklearn.manifold import TSNE
from matplotlib import pyplot as plt
import faiss
# paddle.device.set_device('gpu:0')
import warnings
warnings.filterwarnings("ignore")
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/__init__.py:107: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import MutableMapping
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/rcsetup.py:20: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Iterable, Mapping
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/colors.py:53: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Sized
2.1 Dataset
class SeqnenceDataset(Dataset):
def __init__(self, config, df, phase='train'):
self.config = config
self.df = df
self.max_length = self.config['max_length']
self.df = self.df.sort_values(by=['user_id', 'timestamp'])
self.user2item = self.df.groupby('user_id')['item_id'].apply(list).to_dict()
self.user_list = self.df['user_id'].unique()
self.phase = phase
def __len__(self, ):
return len(self.user2item)
def __getitem__(self, index):
if self.phase == 'train':
user_id = self.user_list[index]
item_list = self.user2item[user_id]
hist_item_list = []
hist_mask_list = []
k = random.choice(range(4, len(item_list))) # 从[8,len(item_list))中随机选择一个index
# k = np.random.randint(2,len(item_list))
item_id = item_list[k] # 该index对应的item加入item_id_list
if k >= self.max_length: # 选取seq_len个物品
hist_item_list.append(item_list[k - self.max_length: k])
hist_mask_list.append([1.0] * self.max_length)
else:
hist_item_list.append(item_list[:k] + [0] * (self.max_length - k))
hist_mask_list.append([1.0] * k + [0.0] * (self.max_length - k))
return paddle.to_tensor(hist_item_list).squeeze(0), paddle.to_tensor(hist_mask_list).squeeze(
0), paddle.to_tensor([item_id])
else:
user_id = self.user_list[index]
item_list = self.user2item[user_id]
hist_item_list = []
hist_mask_list = []
k = int(0.8 * len(item_list))
# k = len(item_list)-1
if k >= self.max_length: # 选取seq_len个物品
hist_item_list.append(item_list[k - self.max_length: k])
hist_mask_list.append([1.0] * self.max_length)
else:
hist_item_list.append(item_list[:k] + [0] * (self.max_length - k))
hist_mask_list.append([1.0] * k + [0.0] * (self.max_length - k))
return paddle.to_tensor(hist_item_list).squeeze(0), paddle.to_tensor(hist_mask_list).squeeze(
0), item_list[k:]
def get_test_gd(self):
self.test_gd = {}
for user in self.user2item:
item_list = self.user2item[user]
test_item_index = int(0.8 * len(item_list))
self.test_gd[user] = item_list[test_item_index:]
return self.test_gd
2.2 基础序列召回模型定义
class GRU4Rec(nn.Layer):
def __init__(self, config):
super(GRU4Rec, self).__init__()
self.config = config
self.embedding_dim = self.config['embedding_dim']
self.max_length = self.config['max_length']
self.n_items = self.config['n_items']
self.num_layers = self.config['num_layers']
self.item_emb = nn.Embedding(self.n_items, self.embedding_dim, padding_idx=0)
self.gru = nn.GRU(
input_size=self.embedding_dim,
hidden_size=self.embedding_dim,
num_layers=self.num_layers,
time_major=False,
)
self.loss_fun = nn.CrossEntropyLoss()
self.reset_parameters()
def calculate_loss(self,user_emb,pos_item):
all_items = self.item_emb.weight
scores = paddle.matmul(user_emb, all_items.transpose([1, 0]))
return self.loss_fun(scores,pos_item)
def output_items(self):
return self.item_emb.weight
def reset_parameters(self, initializer=None):
for weight in self.parameters():
paddle.nn.initializer.KaimingNormal(weight)
def forward(self, item_seq, mask, item, train=True):
seq_emb = self.item_emb(item_seq)
seq_emb,_ = self.gru(seq_emb)
user_emb = seq_emb[:,-1,:] #取GRU输出的最后一个Hidden作为User的Embedding
if train:
loss = self.calculate_loss(user_emb,item)
output_dict = {
'user_emb':user_emb,
'loss':loss
}
else:
output_dict = {
'user_emb':user_emb
}
return output_dict
2.3 Pipeline
config = {
'train_path':'/home/aistudio/data/data173799/train_enc.csv',
'valid_path':'/home/aistudio/data/data173799/valid_enc.csv',
'test_path':'/home/aistudio/data/data173799/test_enc.csv',
'lr':1e-4,
'Epoch':100,
'batch_size':256,
'embedding_dim':16,
'num_layers':1,
'max_length':20,
'n_items':15406,
'K':4
}
def my_collate(batch):
hist_item, hist_mask, item_list = list(zip(*batch))
hist_item = [x.unsqueeze(0) for x in hist_item]
hist_mask = [x.unsqueeze(0) for x in hist_mask]
hist_item = paddle.concat(hist_item,axis=0)
hist_mask = paddle.concat(hist_mask,axis=0)
return hist_item,hist_mask,item_list
def save_model(model, path):
if not os.path.exists(path):
os.makedirs(path)
paddle.save(model.state_dict(), path + 'model.pdparams')
def load_model(model, path):
state_dict = paddle.load(path + 'model.pdparams')
model.set_state_dict(state_dict)
print('model loaded from %s' % path)
return model
2.4 基于Faiss的向量召回
def get_predict(model, test_data, hidden_size, topN=20):
item_embs = model.output_items().cpu().detach().numpy()
item_embs = normalize(item_embs, norm='l2')
gpu_index = faiss.IndexFlatIP(hidden_size)
gpu_index.add(item_embs)
test_gd = dict()
preds = dict()
user_id = 0
for (item_seq, mask, targets) in tqdm(test_data):
# 获取用户嵌入
# 多兴趣模型,shape=(batch_size, num_interest, embedding_dim)
# 其他模型,shape=(batch_size, embedding_dim)
user_embs = model(item_seq,mask,None,train=False)['user_emb']
user_embs = user_embs.cpu().detach().numpy()
# 用内积来近邻搜索,实际是内积的值越大,向量越近(越相似)
if len(user_embs.shape) == 2: # 非多兴趣模型评估
user_embs = normalize(user_embs, norm='l2').astype('float32')
D, I = gpu_index.search(user_embs, topN) # Inner Product近邻搜索,D为distance,I是index
# D,I = faiss.knn(user_embs, item_embs, topN,metric=faiss.METRIC_INNER_PRODUCT)
for i, iid_list in enumerate(targets): # 每个用户的label列表,此处item_id为一个二维list,验证和测试是多label的
test_gd[user_id] = iid_list
preds[user_id] = I[i,:]
user_id +=1
else: # 多兴趣模型评估
ni = user_embs.shape[1] # num_interest
user_embs = np.reshape(user_embs,
[-1, user_embs.shape[-1]]) # shape=(batch_size*num_interest, embedding_dim)
user_embs = normalize(user_embs, norm='l2').astype('float32')
D, I = gpu_index.search(user_embs, topN) # Inner Product近邻搜索,D为distance,I是index
# D,I = faiss.knn(user_embs, item_embs, topN,metric=faiss.METRIC_INNER_PRODUCT)
for i, iid_list in enumerate(targets): # 每个用户的label列表,此处item_id为一个二维list,验证和测试是多label的
recall = 0
dcg = 0.0
item_list_set = []
# 将num_interest个兴趣向量的所有topN近邻物品(num_interest*topN个物品)集合起来按照距离重新排序
item_list = list(
zip(np.reshape(I[i * ni:(i + 1) * ni], -1), np.reshape(D[i * ni:(i + 1) * ni], -1)))
item_list.sort(key=lambda x: x[1], reverse=True) # 降序排序,内积越大,向量越近
for j in range(len(item_list)): # 按距离由近到远遍历推荐物品列表,最后选出最近的topN个物品作为最终的推荐物品
if item_list[j][0] not in item_list_set and item_list[j][0] != 0:
item_list_set.append(item_list[j][0])
if len(item_list_set) >= topN:
break
test_gd[user_id] = iid_list
preds[user_id] = item_list_set
user_id +=1
return test_gd, preds
def evaluate(preds,test_gd, topN=50):
total_recall = 0.0
total_ndcg = 0.0
total_hitrate = 0
for user in test_gd.keys():
recall = 0
dcg = 0.0
item_list = test_gd[user]
for no, item_id in enumerate(item_list):
if item_id in preds[user][:topN]:
recall += 1
dcg += 1.0 / math.log(no+2, 2)
idcg = 0.0
for no in range(recall):
idcg += 1.0 / math.log(no+2, 2)
total_recall += recall * 1.0 / len(item_list)
if recall > 0:
total_ndcg += dcg / idcg
total_hitrate += 1
total = len(test_gd)
recall = total_recall / total
ndcg = total_ndcg / total
hitrate = total_hitrate * 1.0 / total
return {f'recall@{topN}': recall, f'ndcg@{topN}': ndcg, f'hitrate@{topN}': hitrate}
# 指标计算
def evaluate_model(model, test_loader, embedding_dim,topN=20):
test_gd, preds = get_predict(model, test_loader, embedding_dim, topN=topN)
return evaluate(preds, test_gd, topN=topN)
# 读取数据
train_df = pd.read_csv(config['train_path'])
valid_df = pd.read_csv(config['valid_path'])
test_df = pd.read_csv(config['test_path'])
train_dataset = SeqnenceDataset(config, train_df, phase='train')
valid_dataset = SeqnenceDataset(config, valid_df, phase='test')
test_dataset = SeqnenceDataset(config, test_df, phase='test')
train_loader = DataLoader(dataset=train_dataset, batch_size=config['batch_size'], shuffle=True,num_workers=8)
valid_loader = DataLoader(dataset=valid_dataset, batch_size=config['batch_size'], shuffle=False,collate_fn=my_collate)
test_loader = DataLoader(dataset=test_dataset, batch_size=config['batch_size'], shuffle=False,collate_fn=my_collate)
model = GRU4Rec(config)
optimizer = paddle.optimizer.Adam(parameters=model.parameters(), learning_rate=config['lr'])
log_df = pd.DataFrame()
best_reacall = -1
exp_path = './exp/ml-20m_softmax/MIND_{}_{}_{}/'.format(config['lr'],config['batch_size'],config['embedding_dim'])
os.makedirs(exp_path,exist_ok=True,mode=0o777)
patience = 5
last_improve_epoch = 1
log_csv = exp_path+'log.csv'
# *****************************************************train*********************************************
for epoch in range(1, 1 + config['Epoch']):
# try :
pbar = tqdm(train_loader)
model.train()
loss_list = []
acc_50_list = []
print()
print('Training:')
print()
for batch_data in pbar:
(item_seq, mask, item) = batch_data
output_dict = model(item_seq, mask, item)
loss = output_dict['loss']
loss.backward()
optimizer.step()
optimizer.clear_grad()
loss_list.append(loss.item())
pbar.set_description('Epoch [{}/{}]'.format(epoch,config['Epoch']))
pbar.set_postfix(loss = np.mean(loss_list))
# *****************************************************valid*********************************************
print('Valid')
recall_metric = evaluate_model(model, valid_loader, config['embedding_dim'], topN=50)
print(recall_metric)
recall_metric['phase'] = 'valid'
log_df = log_df.append(recall_metric, ignore_index=True)
log_df.to_csv(log_csv)
if recall_metric['recall@50'] > best_reacall:
save_model(model,exp_path)
best_reacall = recall_metric['recall@50']
last_improve_epoch = epoch
if epoch - last_improve_epoch > patience:
break
print('Testing')
model = load_model(model,exp_path)
recall_metric = evaluate_model(model, test_loader, config['embedding_dim'], topN=50)
print(recall_metric)
recall_metric['phase'] = 'test'
log_df = log_df.append(recall_metric, ignore_index=True)
log_df.to_csv(log_csv)
log_df
| hitrate@50 | ndcg@50 | phase | recall@50 | |
|---|---|---|---|---|
| 0 | 0.557147 | 0.285557 | valid | 0.096399 |
| 1 | 0.569507 | 0.302592 | valid | 0.108762 |
| 2 | 0.571616 | 0.307585 | valid | 0.114703 |
| 3 | 0.570525 | 0.307391 | valid | 0.114341 |
| 4 | 0.575105 | 0.311675 | valid | 0.118512 |
| 5 | 0.573506 | 0.310686 | valid | 0.117828 |
| 6 | 0.573288 | 0.310596 | valid | 0.117805 |
| 7 | 0.571834 | 0.308188 | valid | 0.116070 |
| 8 | 0.569798 | 0.306870 | valid | 0.114970 |
| 9 | 0.567180 | 0.304358 | valid | 0.112723 |
| 10 | 0.569216 | 0.304015 | valid | 0.112012 |
| 11 | 0.582059 | 0.313141 | test | 0.118526 |
2.5 基于TSNE的Item Embedding分布可视化
def plot_embedding(data, title):
x_min, x_max = np.min(data, 0), np.max(data, 0)
data = (data - x_min) / (x_max - x_min)
fig = plt.figure(dpi=120)
plt.scatter(data[:,0], data[:,1], marker='.')
plt.xticks([])
plt.yticks([])
plt.title(title)
plt.show()
item_emb = model.output_items().numpy()
tsne_emb = TSNE(n_components=2).fit_transform(item_emb)
plot_embedding(tsne_emb,'GRU4Rec Item Embedding')

3.总结
我们这里首先介绍了推荐系统的整体架构以及各部分的算法特点,这里着重介绍了召回算法的特点,接下来我们以GRU4Rec为例给大家把序列召回的全流程理清楚,最后给了大家一套完完整整可以跑的代码来让大家更加系统的理解这一套逻辑,希望大家认认真真的梳理这一套逻辑以及相关代码细节!
4.参考资料
本项目总述了推荐系统,并且着重对序列召回进行介绍,并且最后使用Paddle和Faiss实现了GRU4Rec完成完整的序列召回实践
Jupyter Notebook