【AI达人创造营第二期】-基于MoviNet检测视频中危险暴力行为
本项目根据MoviNet检测视频或是摄像头中的内容检测是否包含可能的暴力行为。帮助相关人员及时的了解可能的危险行为,避免事态的进一步加剧。
项目介绍
背景
在公共场合斗殴,欺凌此类悲剧还是不停的在我们的身边重演,这种恶劣行为对于当今社会的稳定性有着非常大的影响,
在我设计这个项目途中还发生了如唐山打人案这种举国震惊的事件。对这种情况如果我们有方法
在悲剧发生的途中或是之后立刻由警方进行干预,可以极大程度的避免事态加剧或是犯人逃亡。
但传统的依赖人工报警具有非常高的不确定性和延迟性,
周遭的监控设备虽然可以实时记录但仍是被动记录为主,大多数情况下只能作为事后发生的证据。如果需要通过视频画面了解风险或是即时的阻止悲剧的发生,
现阶段主流的方式还是安排专业人员盯着显示器进行判断。然而,这种方式也只能应用于专门监控线路或是特殊情况,对应浩如烟海的通用监控网络而言,
采用人力监控的方式显然是不可及。

因此,我的项目便是争对这一问题设计出来能够能在嵌入式平台上进行分析和预测可能的暴力行为,并及时的发送提醒给有关人员进行干预。在模型方面,为了适配jetson Nano不算充分的算力,采用了最新的轻量化网络MoviNet(timesformer之类的大型网络效果会更好),同时建立了一套完整的前后端逻辑以便用户使用
设计
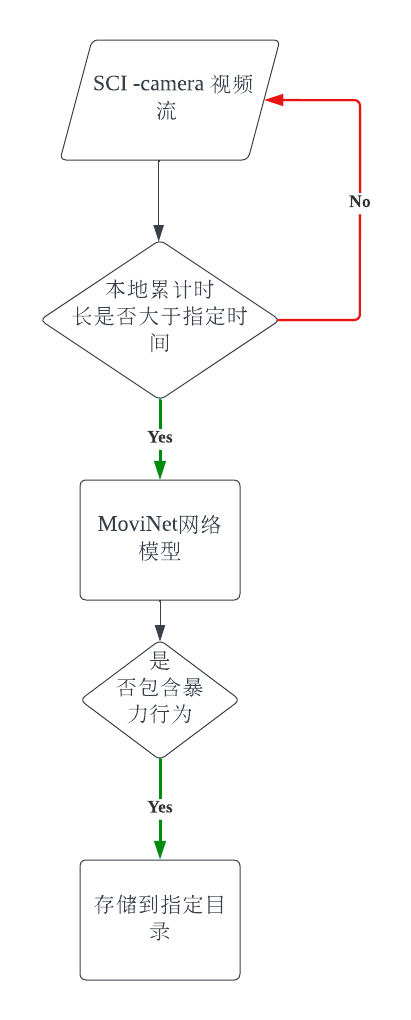
设计流程图:
安装对应的requirement
pip install -r paddleViolenceDection/PaddleVideo/requirements.txt
MoviNet 网络介绍
3D卷积网络CNN在视屏识别方面的准确率是有目共睹的,但通常需要大量的计算和内存预算,此类特性是此类型网络很难在移动设备上进行工作或是在线推理。另一方面,2D卷积网络需要的资源则少的多,可以使用框架进行在线推理允许,但精度上有所不足。
为了克服以上缺点,MoviNet定义了一个搜索空间,以允许神经体系结构搜索能有效的全很时空特征表示。然后,MoviNet还设有引入流缓冲区,能以小的连续的子片段处理视频,在不牺牲长时间依赖性的前提下设定了稳定的内存来实现在线推理。最后MoviNet创建了时间合集,从流缓冲区恢复丢失的精度。
训练数据库介绍
训练数据库名字为“Real Life Violence Situations Dataset”,是由 M.Soliman 等一行人在ICICS‘19 上发布的公开数据集。数据集包含了1000个暴力与非暴力的视频片段。暴力片段则包含了在不同环境不同情况下的真实街头格斗。非暴力视频则打出取材于一些通常的人类行为如吃饭,运动,走路等。

模型测试
对包含暴力场景的画面进行测试
使用以下脚本来快速检测:
bash inference.sh 视频目录
因为模拟嵌入式环境用的是cpu进行推理,可以自行去inference.sh文件进行修改使用GPU
cd paddleViolenceDection/
bash inference.sh "test/tang2.mp4"
对有类似情况但非暴力行为进行检测(例如训练)
bash inference.sh "/home/aistudio/paddleViolenceDection/test/test3.mp4"
jetsonNano 部署
git clone 到nano上指定目录,安装完对应依赖之后,运行python runtime.py启动服务的后端,程序将读取nano的sci相机数据流并进行本地缓存,缓存到指定时间后作为模型的输入。如果模型判断包含指定暴力视频则会存储到指定目录。 程序将持续循环直到手动终止
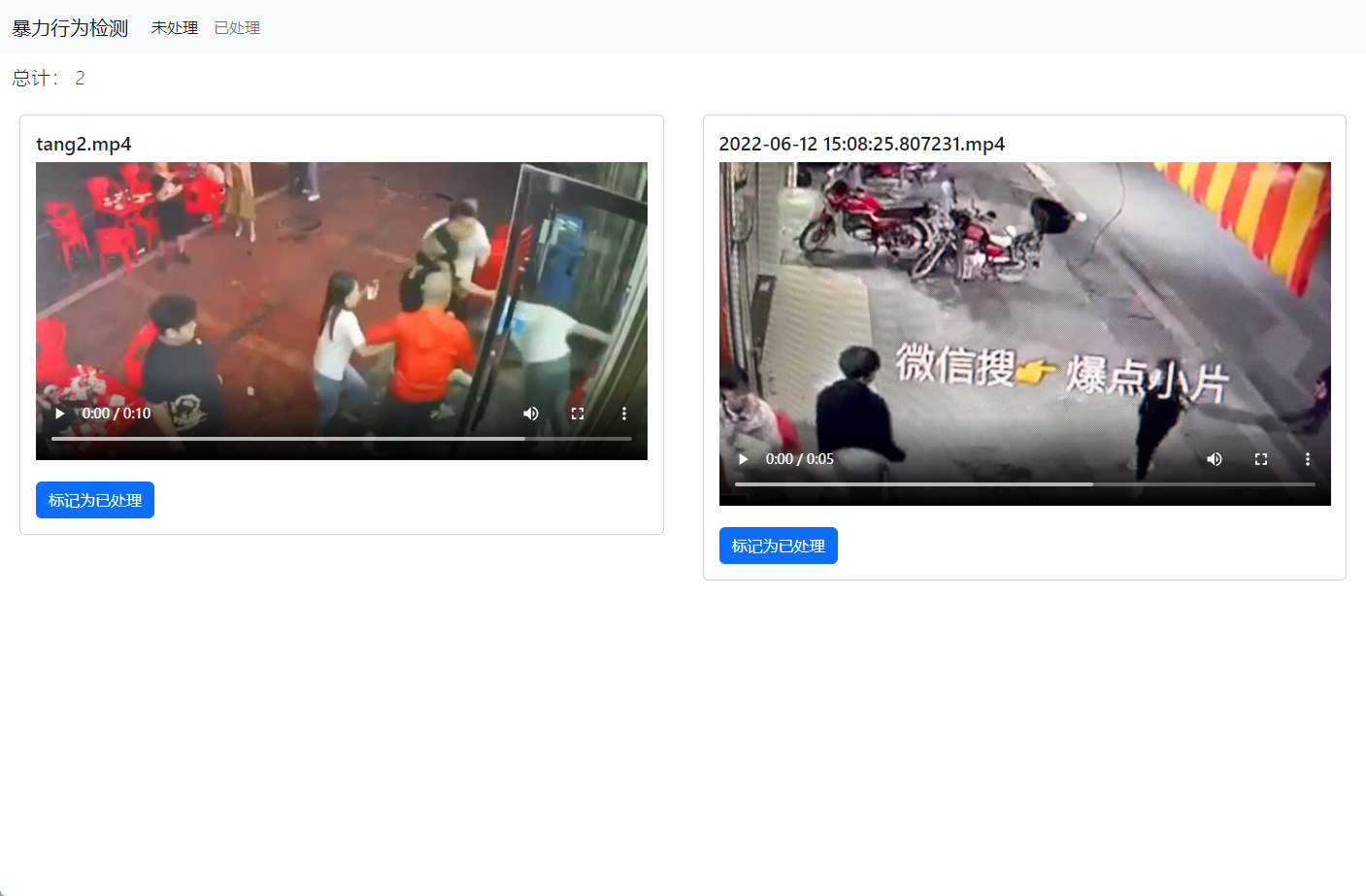
这个项目同时还有后端,运行 python app.py 可以查看一个基于Flask的网页,在页面上可以对于视频进行查看,归档。
(请务必全部使用python3.6作为环境,其他版本会有读取不了SCI相机的问题)
参数
在jetson nano上使用cpu 输入10s视频,大小为114x114,推理耗时 5-6s
(jetson 算力和显存严重不足,换成GPU GPU/CPU/内存开销太大,也无法转换成tensorrt加速)
服务器上 AIstudio最低档CPU推理5s视频约2-3秒
之后方向
- 性能上为了配合嵌入式还有优化的空间,现如今使用的还是float32.
- 训练数据集不算大,只包含1000多个5s的暴力与非暴力视频