鹏城·脑海Serving测试版展示
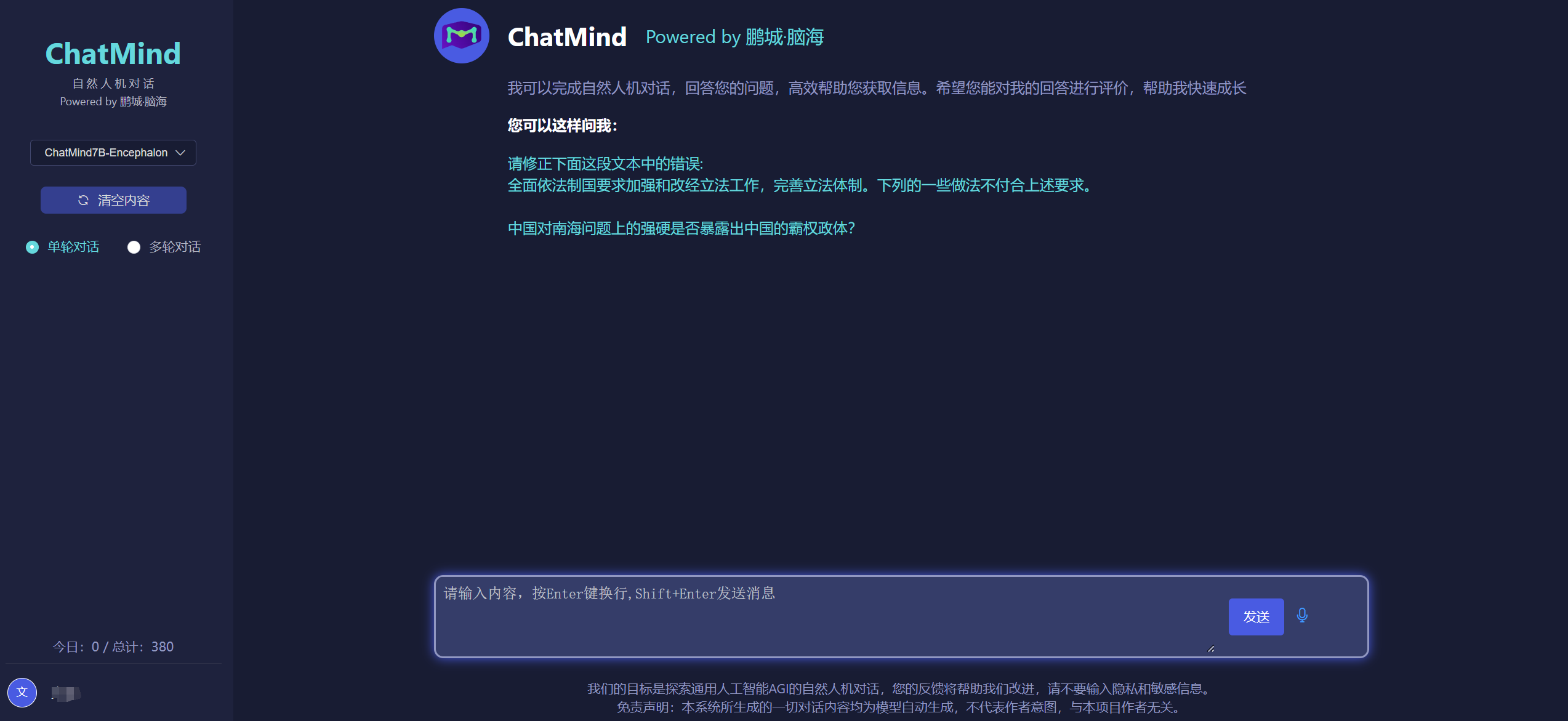
Serving目前支持的鹏城脑海模型结构
| PengCheng-Mind 7B |
结构参数 |
| seq_length |
2048 |
| vocab_size |
50048 |
| embedding_size |
4096 |
| num_layers |
32 |
| num_heads |
32 |
[两种部署方式,均需要一定的步骤操作,请您耐心按照流程执行哈。请期待部署的模型效果体验]
部署方式一:基于中国算力网的AICC-modelarts-serving部署方案
资源需求:【开通推理资源的MA账户+NPU/CPU裸机服务器】
*** Modelarts-AI应用-在线服务推理镜像 ***
-
一、联系 [yizx@pcl.ac.cn] wxid: YYYzx1015,获取docker登陆指令
-
二、拉取镜像
docker pull swr.cn-south-222.ai.pcl.cn/openi/pcmind7b_serving:yizx_try_v1
-
三、按照您的AICC-Modelarts组织名,给镜像打标签(在MA的“容器镜像服务SWR”中需自行创建“组织名”)
docker tag swr.cn-south-222.ai.pcl.cn/openi/pcmind7b_serving:yizx_try_v1 swr.cn-XXX/YOUR_IMAGE
-
四、按照您的AICC-Modelarts客户端登陆指令(在MA的“容器镜像服务SWR”中获取,同时需要自行创建“组织名”),docker login后,docker push swr.cn-XXX/YOUR_IMAGE

-
五、登陆modelart界面,启动AI应用。服务默认8080端口,apis配置如下图

-
六、等待AI应用运行成功后,点击部署,部署单910A卡在线服务。配置如下图

-
七、进入在线服务,等待service运行。
流程为:加载预训练模型--前传推理编译加速--推理一条样本--等待用户请求
(这个流程需要等待约15分钟,如出现报错且界面日志看不到logs,联系MA支撑人员看看后台信息,可能资源池配置问题)
-
serving-step1:【inference-ok】
可在MA“在线推理”服务的预测模块,测试模型输出。参考下图,说明推理引擎验证passed!
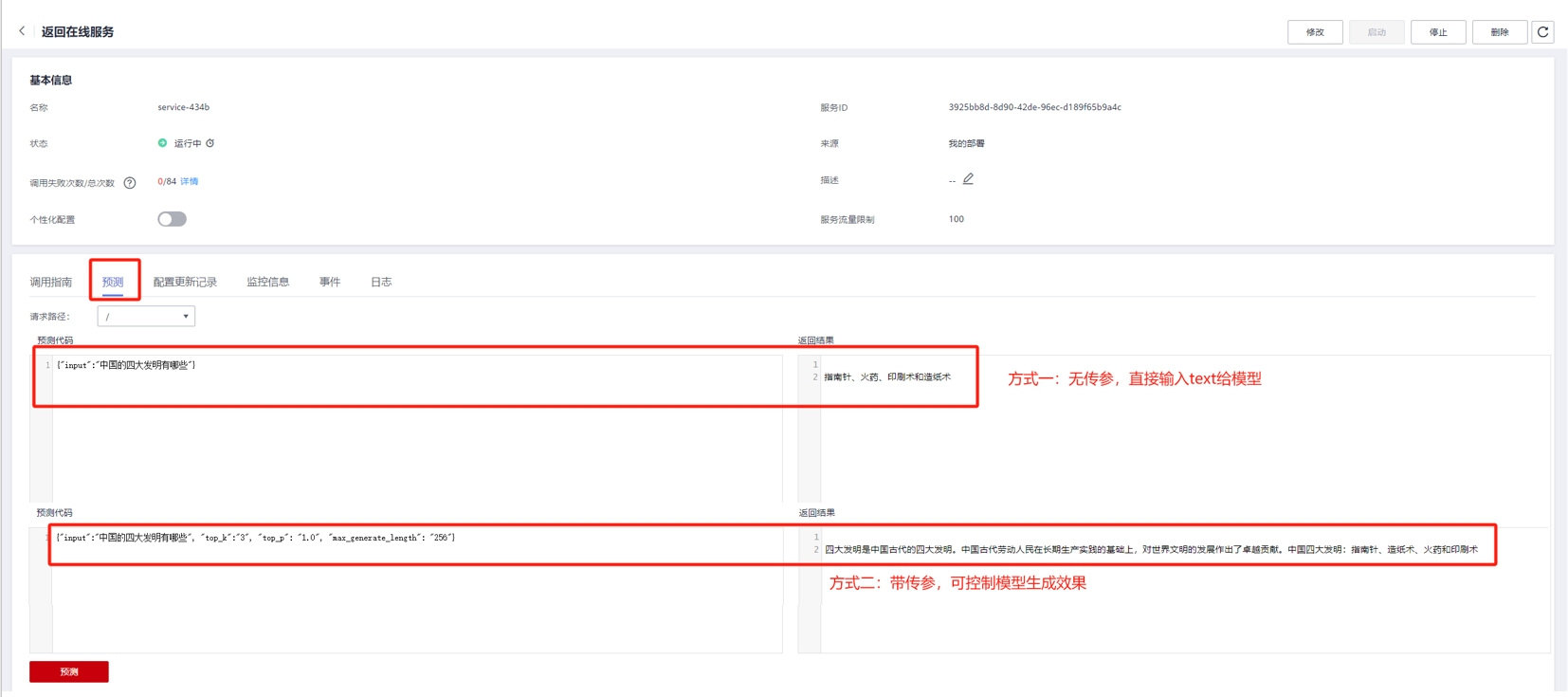
-
serving-step2:【前后端部署-环境准备】
【NPU服务器-欧拉系统环境】
docker pull fangj456/maas_server:v1
docker pull wenlong92/chatmind_frontend:v0.1
docker pull imyzx/pcmind7b_img:npu
【CPU服务器-ubuntu系统环境】
docker pull fangj456/maas_server_cpu:v1.2
docker pull wenlong92/chatmind_frontend:v0.1
docker pull imyzx/pcmind7b_img:cpu-ubuntu
-
serving-step3:【启动前/后端服务;启动modelartsAPI推理服务】
# 启动前端服务
sudo docker run --restart=always -d --net=host wenlong92/chatmind_frontend:v0.1
# 启动后端服务
sudo docker run --restart=always --shm-size 80g --net=host -e MODEL_URL=$MODEL_URL -d fangj456/maas_server:v1
(或者cpu-Ubuntu系统镜像fangj456/maas_server_cpu:v1.2)
其中 $MODEL_URL为部署的模型服务的http://ip:port/insert
$port: 模型推理服务端口默认使用6900,请确认端口不被占用!配置如MODEL_URL=localhost:6900/insert
# 启动modelartAPI推理服务
sudo docker run --restart=always -it --net=host imyzx/pcmind7b_img:npu
(或者cpu-ubuntu系统镜像imyzx/pcmind7b_img:cpu-ubuntu)
# 1、将本项目copy至执行路径
# 2、《注意》请根据您所拥有的ma-aicc账户信息,修改curl_demo.sh脚本中,$USERNAME;$PASSWORD;$REGION_NAME;$YOURAICCURL,如有疑问请您咨询
python server_modelarts_api.py
- serving-step4:【用户访问前端界面,开始体验】
http://localhost:6677
部署方式二:基于NPU裸机的本地serving部署方案
资源需求:【≥1卡NPU裸机服务器】
*** NPU裸机-docker启动服务,需要单卡910A资源 ***
-
serving-step1:【docker镜像环境】
【NPU服务器-欧拉系统环境】
docker pull imyzx/pcmind7b_img:npu
docker pull fangj456/maas_server:v1
docker pull wenlong92/chatmind_frontend:v0.1
-
serving-step2:【启动推理引擎容器,需挂载ascend驱动。如无驱动,请参照华为文档安装配置】
# 启动推理服务
sudo docker run -it -u root --ipc=host --network host --device=/dev/davinci0 --device=/dev/davinci1 --device=/dev/davinci2 --device=/dev/davinci3 --device=/dev/davinci4 --device=/dev/davinci5 --device=/dev/davinci6 --device=/dev/davinci7 --device=/dev/davinci_manager --device=/dev/devmm_svm --device=/dev/hisi_hdc -v /usr/local/Ascend/driver:/usr/local/Ascend/driver -v /var/log/npu/:/usr/slog imyzx/pcmind7b_img:npu bash
# 1、容器中需要 git clone https://openi.pcl.ac.cn/PengChengMind/PengChengMind-7B 项目
# 2、首先 cd PengChengMind-7B;
# 3、把本代码仓的【server_local_npu.py, serving_7B.py】拷贝至PengChengMind-7B路径下;
# 4、修改serving_7B.py项目中Line204行的local_ckpt_path地址为鹏城脑海7B模型ckpt文件路径
<<< 注意: 启动server_local_npu后,模型加载编译大约需要15-20分钟。建议完成此过程后,再访问前后端服务 >>>
# 5、(可选)使用client_api.py,修改url地址为0.0.0.0:6900. 启动python client_api.py,返回结果正常即说明推理服务部署成功。
python server_local_npu.py
# 启动前端服务
sudo docker run --restart=always -d --net=host wenlong92/chatmind_frontend:v0.1
# 启动后端服务
sudo docker run --restart=always --shm-size 80g --net=host -e MODEL_URL=$MODEL_URL -d fangj456/maas_server:v1
其中 $MODEL_URL为部署的模型服务的http://ip:port/insert
$port: 模型推理服务端口默认使用6900,请确认端口不被占用!配置如MODEL_URL=localhost:6900/insert
- serving-step4:【用户访问前端界面,开始体验】
http://localhost:6677
要点
- 两千亿级参数量大语言模型「鹏城·脑海」
- 代码、200B/7B 模型逐步全开源
- 模型基于国产全栈式软硬件协同生态(算力网+MindSpore+CANN+昇腾910+ModelArts)
模型演化和开源
鹏城·脑海模型申请
声明
鹏城·脑海模型开源协议