简体中文 | English
FAQ
Q1: PaddleSeg 如何从本地加载预训练模型的权重参数?
PaddleSeg 模型的推荐配置参数统一存放在 PaddleSeg/configs 下各个模型文件夹的 yaml 文件中。比如 ANN 的其中一个配置在 /PaddleSeg/configs/ann/ann_resnet50_os8_cityscapes_1024x512_80k.yml 中给出。如下图所示:
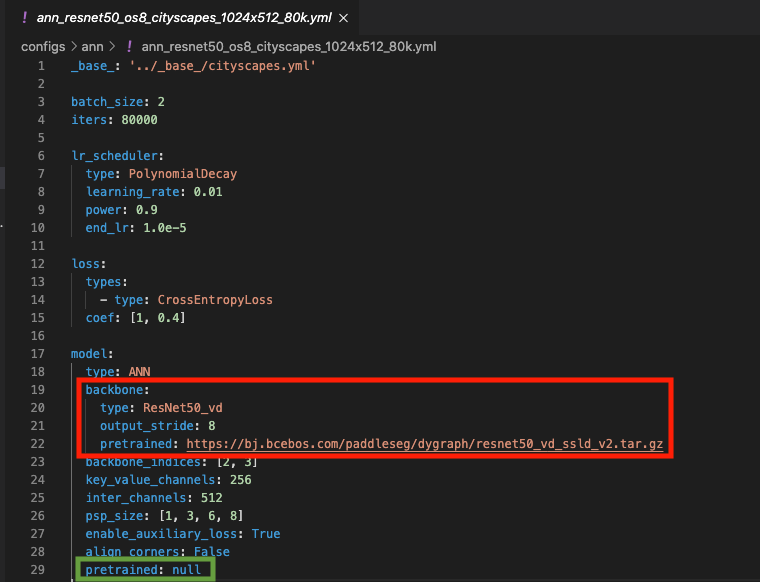
图中红色部分为骨干网络的预训练模型参数文件的存放位置。请注意:此处将直接以 https 链接形式下载我们提供的预训练模型参数。如果你在本地拥有骨干网络的预训练模型参数,请用其存放的绝对路径替换该 yaml 文件中 backbone 下的 pretrained。或者,你可以根据将要执行的 train.py 所在的目录为该预训练模型参数的存放位置设置相对路径。
图中绿色部分为分割网络的预训练模型参数文件的存放位置。如果你在本地拥有分割网络的预训练模型参数,请用其存放的绝对路径或相对路径替换该 yaml 文件中的 pretrained。
Q2: 为什么PaddleSeg不采用设置epoch的方式?
设置 epoch 的方式会受数据集大小的影响。因此PaddleSeg 按照 iters 进行设置。
补充: 常见训练配置参数之间的关系
-
定义参数如下:
-
- 数据集大小: N
-
- 批量大小: batch_size
-
- GPU数量: num_gpus
-
- 总迭代次数: iters
-
则有:
- epoch = (iters * batch_size * num_gpus) / N
Q3: 数据增强配置的加载顺序是怎样的?
由于数据增强的配置要在yaml文件中进行指定,先介绍一下PaddleSeg中配置文件的基本知识。
Cityscapes是图像分割领域最常使用的数据集之一,因此Cityscapes上的一些常用配置已经给出。
PaddleSeg以 _base_ 指定配置之间的继承关系:
_base_: '../_base_/cityscapes.yml'
_base_: '../_base_/cityscapes_1024x1024.yml'
- 说明:
-
- 数据增强以
transforms 所指定,由上到下依次加载。
-
- 子类覆盖父类中的同名配置。
-
- 命令行(如
--batch_size 4)覆盖 --config 内部的同名配置(如yaml中指定的batch_size: 8)。
Q4: 数据增强配置为何会引起 DataLoader reader thread 错误?
如果你使用的是shape各不一致的自定义数据集,这可能是由于不得当的数据增强加载顺序引起的错误。
在Q3中,我们已经知道PaddleSeg的数据增强配置是按顺序加载的。
例如,RandomRotation 会改变图片大小,如果在其他修正尺寸的增强配置之后设置它(如Crop、Resize),将导致图像尺寸的不一致。从而引发 DataLoader reader thread 错误。
因此,在开启训练之前,请参照Q3,仔细检查数据增强配置顺序。
Q5: 目前PaddleSeg在CityScapes上SOTA的模型是什么?
目前在CityScapes上SOTA的模型可达到87%的mIoU。
详见: https://github.com/PaddlePaddle/PaddleSeg/tree/develop/contrib/CityscapesSOTA
Q6: 为什么训练过程中不保存best_model?
best_model是在训练过程中验证对比得到的。因此需要在训练前开启选项 --do_eval。
Q7: 恢复训练后,为什么vdl仅仅可视化了后半部分?如何对训练中断之前进行可视化?
由于算力限制、各种不可抗力,模型可能未能一次训练完毕。
一个比较简单的办法是:把第一次生成的日志和第二次生成的日志中的内容拷贝到一个新的二进制文件中,然后读取。
我们将会在不久的将来在新版本中支持多个日志合并。
另外,如果是类似这种中断后继续训练的情况,可以在调用visualdl的时候指定日志名,这样就可以直接在指定的日志文件中继续续写了。
资料见:https://github.com/PaddlePaddle/VisualDL/blob/develop/docs/faq_CN.md#%E5%A6%82%E4%BD%95%E4%BF%AE%E6%94%B9%E5%B7%B2%E6%9C%89%E7%9A%84%E6%97%A5%E5%BF%97%E6%96%87%E4%BB%B6