盘古跨域pipeline协同训练
目标
【保护用户隐私】:通过对模型切分成多个子网络进行跨域pipeline训练,保护用户的隐私数据,提升用户对话、问答等多个方面的用户体验。
【协同训练新的范式】:通过对模型切分成多个子网络进行跨域pipeline训练,根据实际算力情况,对算力大的智算中心分配较大的子网络,算力小的智算中心分配较小的子网络,减少客户端计算性能差异带来的影响,促进智算网络健康平衡发展。
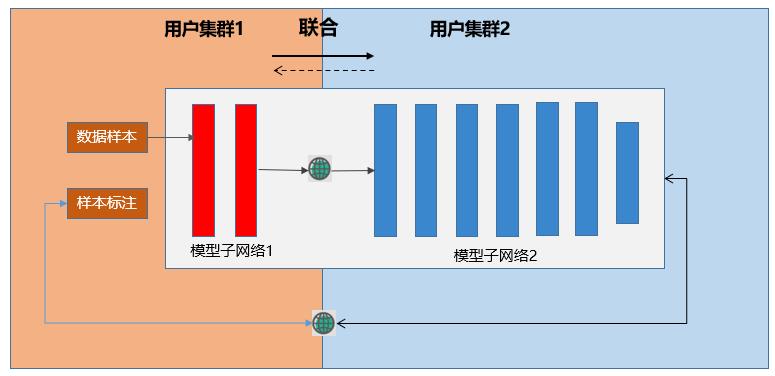
如上图所示,该案例中,用户集群1拥有专业领域数据集,参与方包括用户集群1和用户集群2,模型子网络1参数占比20%左右,模型子网络2参数占比80%,并通过交换embedding向量和梯度向量,在不泄露原始特征和标签信息的前提下,实现对网络模型的协同训练。
pangu网络原理特性的详细介绍,可参考pangu-Alpha。
设计原理
pangu网络切分详细介绍,可参考pangu-pipeline设计原理。
时序分析
pangu跨域pipeline协同训练过程时序详细介绍,可参考pangu-pipeline时序分析。
数据集准备
本样例基于wiki数据集进行训练和测试
如需要对数据进行处理,可以参考 数据处理示例
运行样例
样例提供将盘古模型切分成3个子网络,分别为embedding net、backbone net、head net,其中embedding net和head net在同一参与方,backbone net在另一参与方。
本样例提供2个示例程序,均以Shell脚本拉起Python程序的形式运行。
进入到目录 cd ./pangu_pipeline/splitnn_pangu_alpha
-
./scripts/run_distribute_split_pangu_gpu.sh:单线程示例程序,embedding、head参与方和backbone参与方在同一线程中训练,其以程序内变量的方式,直接传输embedding向量和梯度向量至另一参与方。
-
./scripts/run_distribute_split_pangu_gpu_socket.sh:多线程示例程序,embedding、head参与方和backbone参与方分别运行一个训练线程,其分别将embedding向量和梯度向量封装为protobuf消息后,通过socket通信接口传输至另一参与方。(to do)
以./scripts/run_distribute_split_pangu_gpu.sh为例,运行示例程序的步骤如下:
-
参考MindSpore官网指引,安装MindSpore 1.8.1。
推荐直接 docker pull swr.cn-south-1.myhuaweicloud.com/mindspore/mindspore-gpu-cuda11.1:1.8.1
-
安装MindSpore Federated库,mindspore_federated是一款开源联邦学习框架,实现的主要功能包括:不同子网络前向输出结果的传输与反向计算梯度的传导等。
cd pangu_pipeline
pip install ./whl/mindspore_federated-0.1.0-cp37-cp37m-linux_x86_64_V4.whl
- 运行示例程序启动脚本。
bash scripts/run_distribute_split_pangu_gpu.sh 1 ./scripts/hostfile_1gpus ./dataset/wiki/train/ 2 350M
- 查看训练日志
log_local_gpu.txt
INFO:root:epoch 0 step 10/43391 loss: 10.642237
INFO:root:epoch 0 step 20/43391 loss: 10.378647
INFO:root:epoch 0 step 30/43391 loss: 10.172309
INFO:root:epoch 0 step 40/43391 loss: 9.891272
INFO:root:epoch 0 step 50/43391 loss: 9.643802
INFO:root:epoch 0 step 60/43391 loss: 9.478779
INFO:root:epoch 0 step 70/43391 loss: 9.460744
INFO:root:epoch 0 step 80/43391 loss: 9.285812
INFO:root:epoch 0 step 90/43391 loss: 9.370293
INFO:root:epoch 0 step 100/43391 loss: 8.724071
INFO:root:epoch 0 step 110/43391 loss: 8.522751
INFO:root:epoch 0 step 120/43391 loss: 8.876641
INFO:root:epoch 0 step 130/43391 loss: 8.514479
INFO:root:epoch 0 step 140/43391 loss: 7.996586
INFO:root:epoch 0 step 150/43391 loss: 7.899467
INFO:root:epoch 0 step 160/43391 loss: 7.661634
INFO:root:epoch 0 step 170/43391 loss: 9.237949
INFO:root:epoch 0 step 180/43391 loss: 7.449853
...
- 查看训练loss
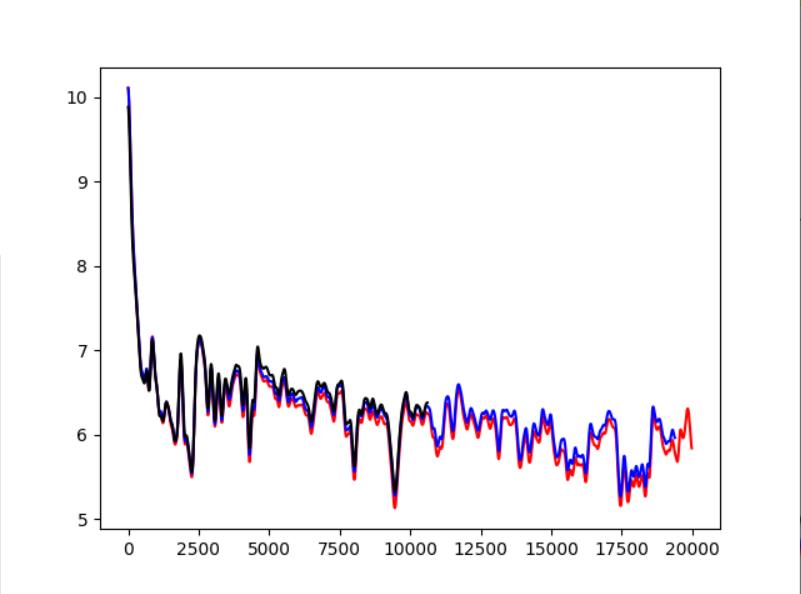

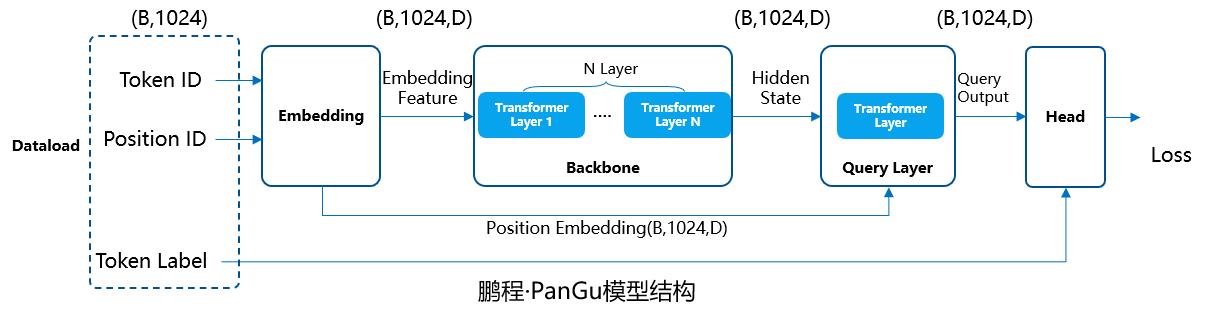
pangu-pipeline设计原理
盘古模型参数量如下表所示:
| 参数量 |
层数 |
词表大小(V) |
embedding_size |
Seq_length |
Hidden size(D) |
FFN size |
Heads |
| 350M(MindSpore) |
16 |
4W |
1280 |
1024 |
1280 |
5120 |
32 |
| 350M(Megatron) |
24 |
4W |
1024 |
1024 |
1024 |
4096 |
16 |
| 2.6B |
32 |
4W |
2560 |
1024 |
2560 |
10240 |
32 |
| 13B |
40 |
4W |
5120 |
1024 |
5120 |
20480 |
40 |
| 200B |
64 |
4W |
16384 |
1024 |
16384 |
65536 |
128 |
应用场景如下表所示:
| 场景 |
算力分布 |
数据分布 |
场景Motivation |
| 场景1 |
一方算力大、一方算力小 |
一方拥有领域数据、一方无数据 |
通过智算网络大算力方支持,实现领域数据拥有方大模型能力在领域任务中的性能增强 |
| 场景2 |
一方算力大、一方算力小 |
一方拥有领域数据、一方拥有通用数据 |
通过智算网络大算力方支持,实现领域数据和通用数据融合下得到更高性能的大模型 |
| 场景3 |
两方算力均衡 |
双方拥有同类型数据、数据分布不同 |
通过智算网络算力的协同,实现大模型训练在智算网络中的规模化扩展 |
| 场景4 |
两方算力均衡 |
双方拥有数据同分布 |
通过智算网络算力的协同,实现大模型训练在智算网络中的规模化扩展 |
| 场景5 |
两方算力均衡 |
双方拥有同一份数据 |
通过智算网络算力的协同,实现大模型训练在智算网络中的规模化扩展 |
模型切分方式
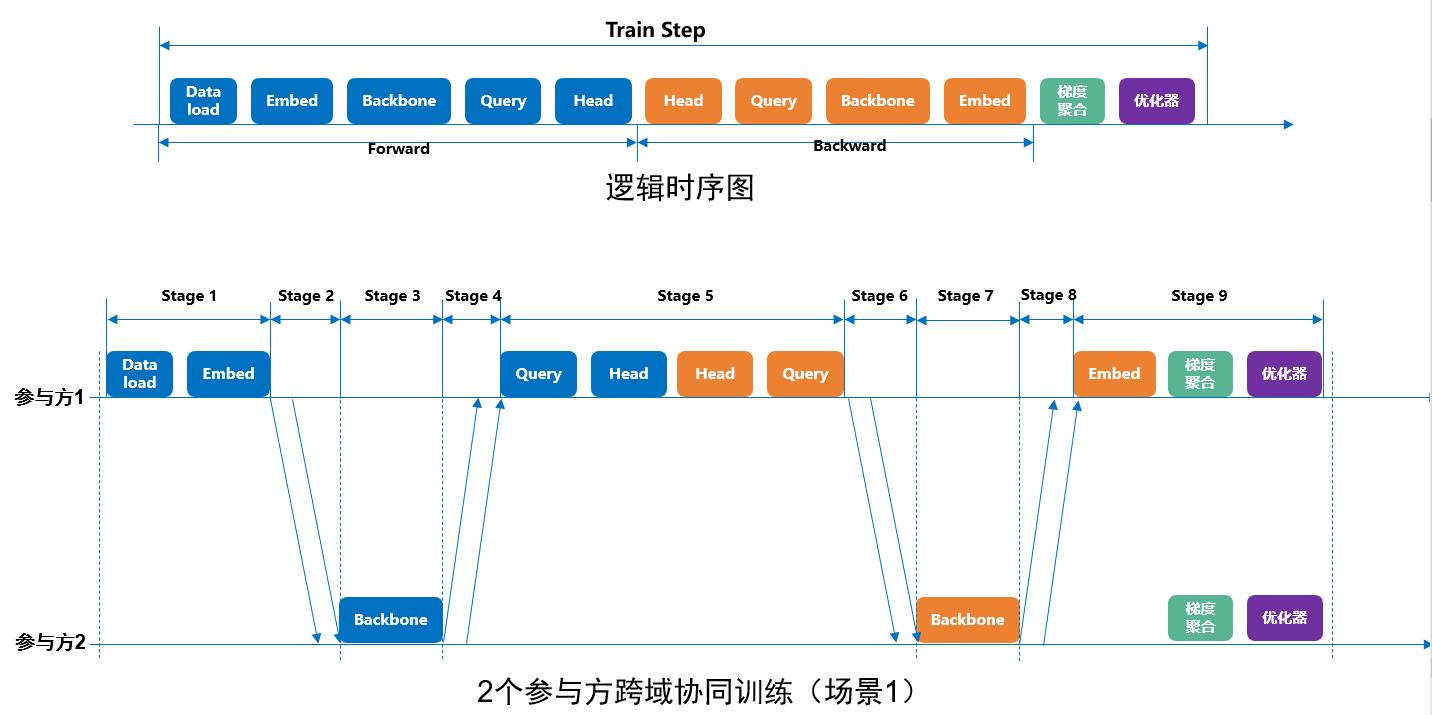
pangu-pipeline时序分析
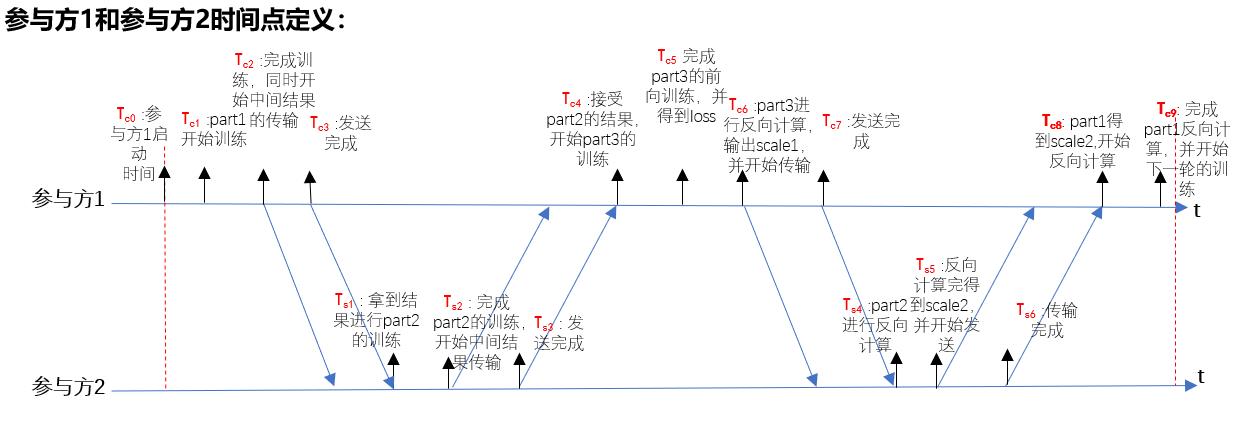

在V100和A100上运行的耗时分析数据如下:
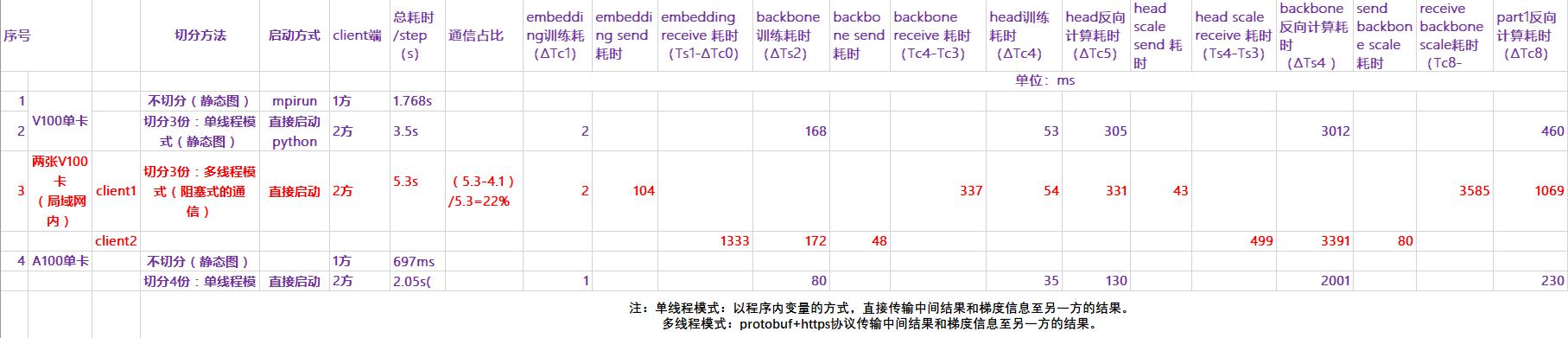
结论:目前在单线程模式下,切分后的训练效率较baseline有2倍效率的损失。还需进一步的性能优化