English|中文
mPanGu-Alpha-53
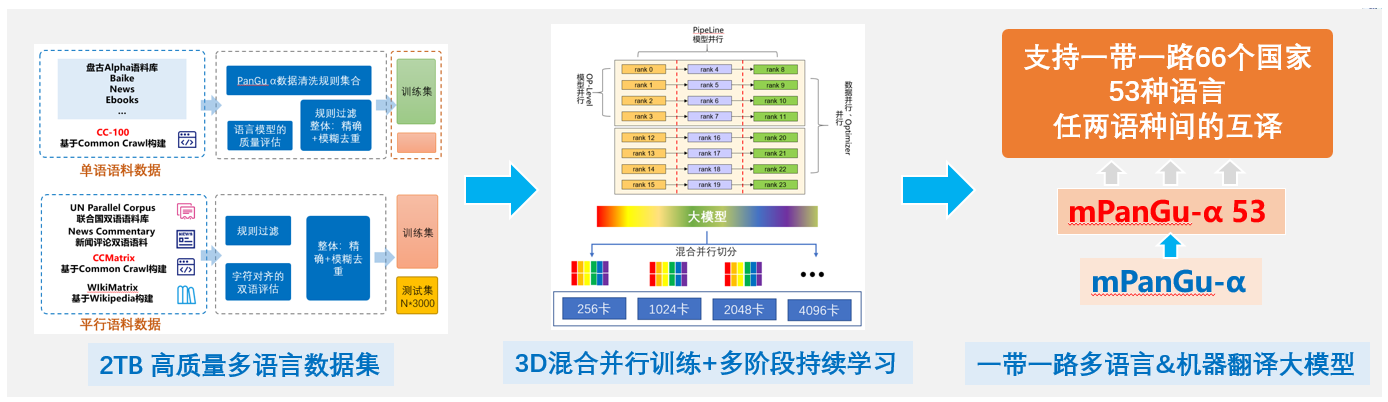
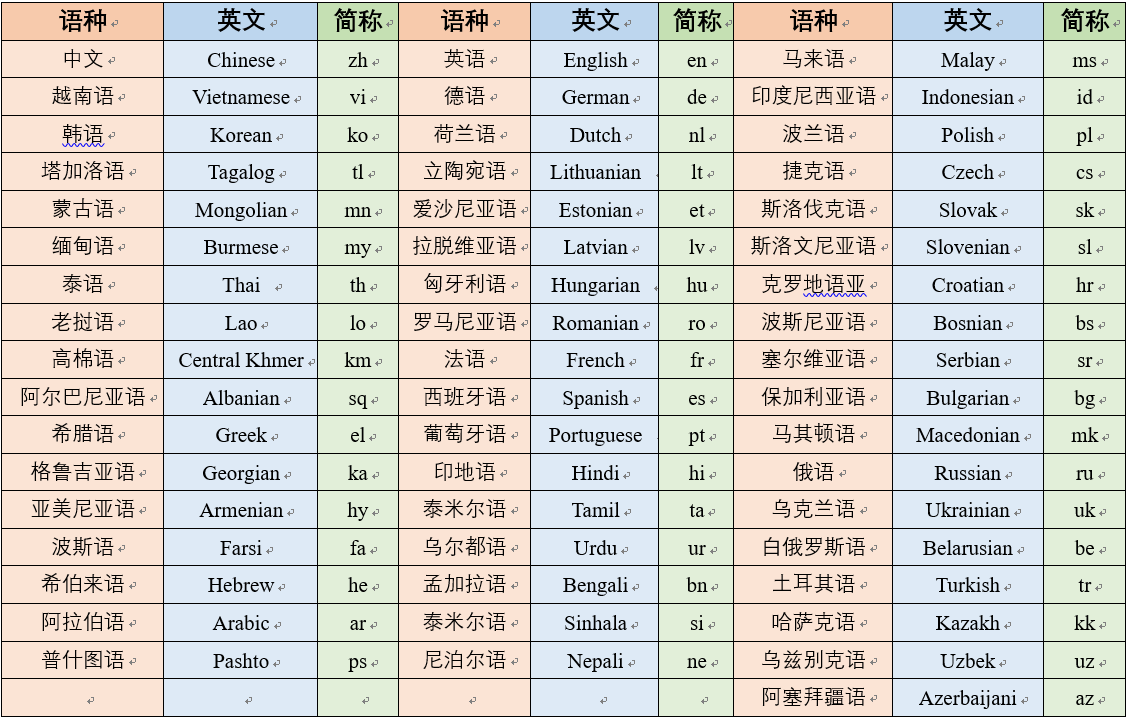
mPanGu-α-53 Come from Pengcheng·PanGu-α,Based on the multi-language translation scenario application of the Belt and Road, pre-training + mixed corpus training was conducted on the self-constructed 2TB high-quality multi-language single and dual language corpus set based on "Pengcheng Yunnao 2" 128 card, and 2.6B pre-training multi-language model +2.6B Belt and Road 53 language machine translation model was obtained, supporting the "transfer learning" of multi-language translation tasks. It supports distributed training (at least 8 cards) and reasoning (full precision /FP16, 1 card) based on MindSpore on NPU/GPU. The single model supports the mutual translation between any two languages of 53 languages. In the WMT2021 Multilingual quest track, in the FLORES-101 devtest dataset, compare the 50 languages covered by Quest List No.1. -> The average BLEU value in 100 translation directions increased by 0.354.
At present, there are two versions of GPU/NPU because MindSpore versions are different. The mainstream version of MindSpore supported by 'Pengcheng Yunnao 2' NPU is 1.3 at present, and the MS1.6 version of GPU platform has better adaptability
Implementation process
| stage |
Learning rate |
warmup |
beta1 |
beta2 |
batchsize |
steps |
equivalent token |
| pre-training |
1e-4~1e-6 |
2000 |
0.9 |
0.94 |
512 |
915000 |
480 B |
| Mixed incremental learning |
5e-5~5e-7 |
2000 |
0.9 |
0.94 |
512 |
765000 |
400 B |
Supporting language
Environmental requirements
GPU operating environment
- mPanGu_alpha_GPU, cuda versions 11.1 to 11.3 are recommended. Cuda versions of other versions have not been tested and may have compatibility problems
MindSpore 1.6.1
docker pull hengtao2/mindspore:gpu_ms_1.6.1
Or use MindSpore official inDocker Hubhosting the Docker image.
NPU operating environment
MindSpore 1.3
Based on "Pengcheng Yunnao 2" +ModelArts, running in the C76 version environment (with OpenI Qizi collaboration platform NPU training task environment)
BaChang operating environment
AI BaChang is a new infrastructure platform for data element circulation and trading built in Pengcheng Laboratory based on Academician Fang Binxing's new privacy protection concepts of "data not moving program, data available invisible, value sharing without data sharing, ownership retention and right of use release". Through the separation of the architecture from the debugging environment and the innovative technologies such as the generation of simulation data and the debugging under the premise of privacy protection, to ensure the separation of data ownership and use right, more data providers can dare to safely host their data, so that more data users can fully mine the real scene real data.
mPanGu based on the BaChang, single machine, multi-card + unilateral and multi-party data collaborative training scenarios
AiSynergy Cooperative operation
AiSynergyIntercloud collaborative training
Model file download
Open source data
Our data is open source based on the Ai BaChang environment
| dataset |
Apply for data use permission |
description |
name |
| The Belt and Road multilingual 1T dataset |
If have a need to use data sets, please email feedback to taoht@pcl.ac.cn |
Each file is a single or bilingual sample corpus for the language, and currently contains data of 52 languages. The Corpus was obtained from PanGu-Alpha Chinese corpus, CC-100, CCMatrix, UN Parallel Corpus, WMT and other cleaning processes, such as rule filtering, global precision and fuzzy weight removal, bilingual character alignment filtering, etc |
B&R-M-1T |
dataset: Email to submit user information, project annotation data source, completely open source, please contact: taoht@pcl.ac.cn
Model: mPanGu-α, mPanGu-α-53 Full open source(FP32, FP16)
code: GPU/NPU dual platform support, training, reasoning fully open source, support AIsynergy cross-cluster collaborative training
Operating environment: OpenI Collaboration platform (GPU/NPU)
Technical communication: PengChengPanGu alpha technology exchange group, openid intelligence community
Data processing
Data processing flow
Quick Start
GPU inference
./mPanGu_alpha_GPU/
1. Script startup
bash scripts/run_distribute_inference.sh #Startup script
8 #Number of cards used
hostfile_8gpus #hostfile file
2.6B #Model size
'8,9,10,11,12,13,14,15' #Use card id
bash scripts/run_distribute_inference.sh 8 /tmp/hostfile_8gpus 2.6B '8,9,10,11,12,13,14,15'
2. Command line startup
# Take single-card reasoning, for example
mpirun --allow-run-as-root -x PATH -x LD_LIBRARY_PATH -x PYTHONPATH -x NCCL_DEBUG -x GLOG_v \
-n 1 \#Number of cards used
--hostfile hostfile_1gpus \
--output-filename log_output \
--merge-stderr-to-stdout \
python -s /path/to/predict.py \
--mode 2.6B \
--run_type predict \
--distribute false \
--op_level_model_parallel_num 1 \#Be consistent with the number of cards used
--load_ckpt_path /path/to/ckpt_path/ \
--load_ckpt_name /ckpt_name \
--param_init_type "fp16" #"fp16" or "fp32"
NPU inference
ModelArts starts the task and starts the predict.py file
Operation parameter configuration:
device_num=1
op_level_model_parallel_num=1
run_type=predict
Resource selection:
Ascend: 1 * Ascend-910(32GB) | ARM: 24 核 256GB
GPU training
Run the following command to start training on a 2.6B single machine with 16 GPU cards
bash scripts/run_distribute_train_gpu.sh
16 #Number of cards used
hostfile #hostfile file
dataset/test/ #train dataset
8 #batchsize
2.6B #model size
bash scripts/run_distribute_train_gpu.sh 16 /tmp/hostfile dataset/test/ 8 2.6B
NPU training
ModelArts starts the task (using Card 8 as an example) and starts the file train.py
The model-related configuration is located at./src/utils.py and./src/pangu_alpha_config.py
Operation parameter configuration:
data_url=Data set catalog
device_num=8
op_level_model_parallel_num=1(Either 1 or 8 will do)
per_batch_size=8
mode=2.6B (Model size 350M/2.6B/13B/200B...)
full_batch=1
run_type=train
Resource selection:
Ascend: 8 * Ascend-910(32GB) | ARM: 192 核 2048GB
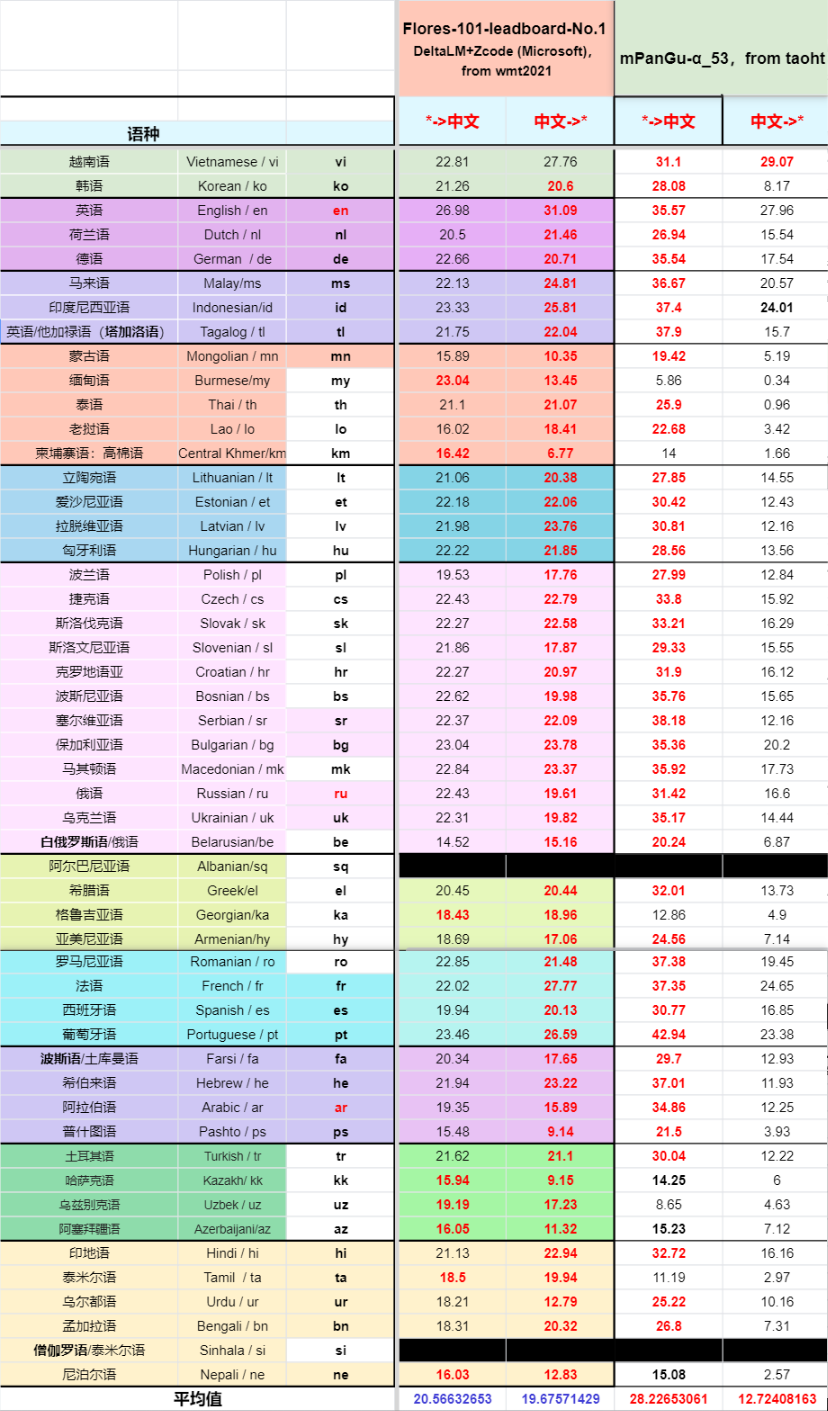
Evaluation result
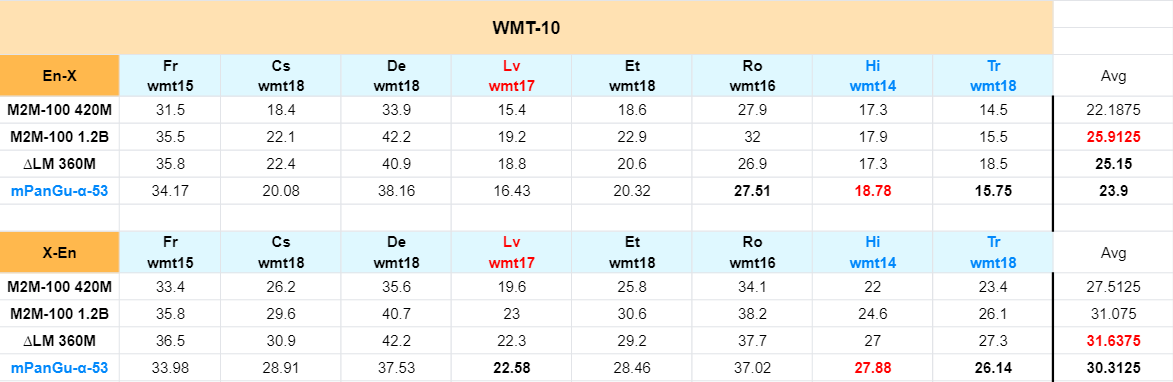
- In the official devtest dataset" -> Comparing the score of WMT2021 "Multilingual Track" No.1
-
Compare Facebook M2M-100, Microsoft delta LM and other multi-language models in the paper "English < -> Comparison of the results of "foreign" translation direction (no specific language direction enhancement, specific language direction transfer learning will be further improved)
-
Transfer learning research
- The experiment was conducted at zh<->mn、zh<->lo language direction transfer learning fine-tuning, about 64 card NPU training hours, preliminary comparison results are as follows:
- test set from manual review of each language direction contains about 3000 standard test sets in 5 major areas (not yet open)
- The evaluation results used a single model of 2.6bpencheng ·mPanGu-α-53_mn-lo. The evaluation data and results were not processed before and after, and were directly compared with the first-line commercial translation system
| Model/system (BLEU) |
lo2zh |
zh2lo |
mn2zh |
zh2mn |
| Domestic commercial system 1 |
40.4 |
25.9 |
37.48 |
41.32 |
| Domestic commercial system 2 |
36.74 |
15.5 |
33.52 |
33.11 |
| google |
35.08 |
23.64 |
30.78 |
34.15 |
| microsoft |
28.63 |
20.35 |
23.39 |
19.18 |
| PengCheng·mPanGu-α-53_mn-lo |
38.16 |
26.76 |
34.65 |
28.17 |
Alternating current channel

Project information
Pengcheng Laboratory - Intelligence Department - High Efficiency cloud Computing Institute - distributed Technology Research Laboratory
License
Apache License 2.0