PCL-Tongyan
中文|English
PCL-tongyan is a multi-language machine translation model. The single model supports 17 minority languages translation with Chinese, it also supports translation between any two languages. PCL-Tongyan is a multilingual machine translation model improved on the structure of M2M-100 model. Through parameter reusing and incremental training, the model parameters are increased from 1.2B to 13.2B, which greatly improves the translation performance of multiple minority languages. We use a lifelong learning approach based on dynamic playback, PCL-Tongyan can continuously learn new language translation without forgetting old languages. More details are given in the PPT.
Features
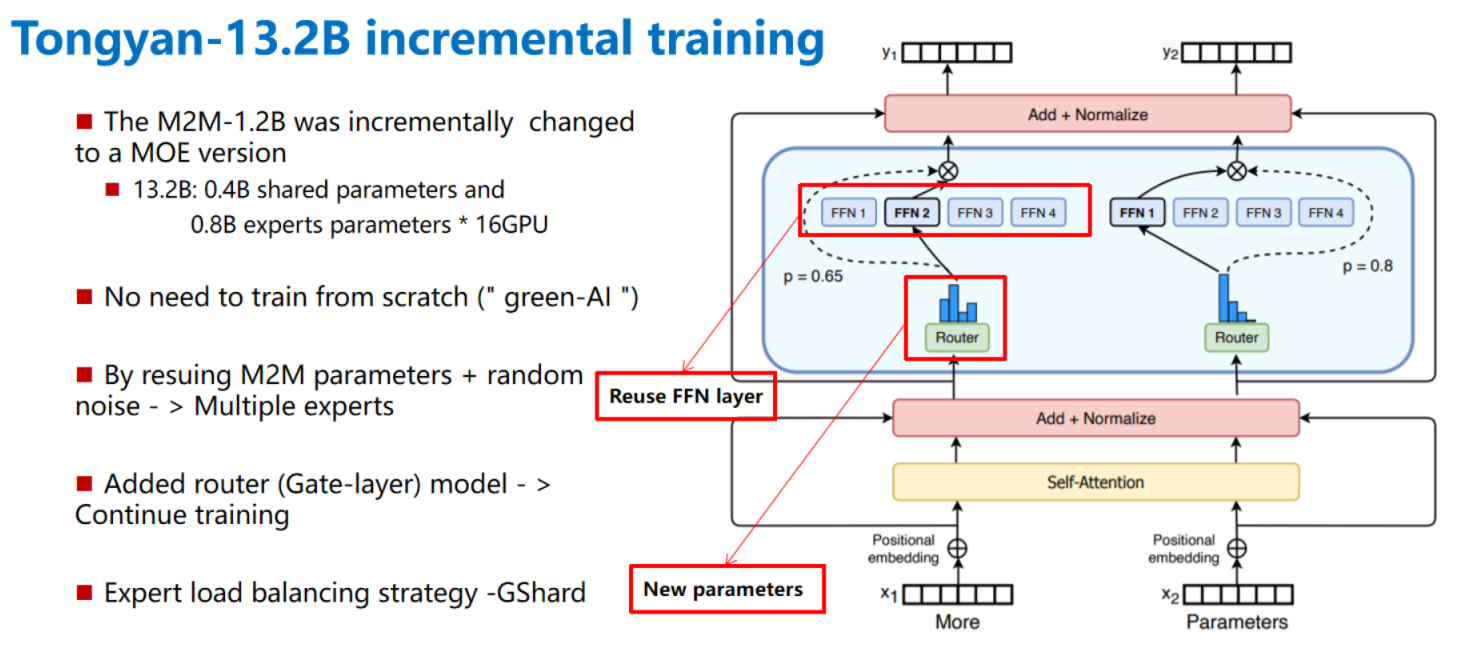
- The M2M-1.2B model was incrementally improved to a MOE version
- Incremental training is used to reduce computational consumption, in line with the concept of "green-AI"
- By resuing M2M parameters + random noise - > Multiple experts
- Support lifelong learning of new languages by the sustainable learning solutions based on dynamic playback
- Using distributed MOE strategy to improve resource utilization efficiency, only 16 V100 are enough to data and expert hybrid parallel
- Based on FairseQ and FastMOe, fast to train and easy to deploy
- Using a single V100 graphics card for inference, without inter-card communication, greatly improving the inference speed.
Model structure

Data source
https://git.pcl.ac.cn/PCMachineTranslation/PCMT/src/branch/master/datasets
-- See Excel for data statistics
Incremental training principle
Training steps
- According to the official instructions install fairseq and fastmoe (We use NVCR. IO/nvidia/pytorch: 21.06 py3 docker environment installation, also can bash sh_dir/Install_fair.sh for installation)
- Copy all files from pcl-tongyan directory to fairseq installation directory (overwrite)
- Download the "silk road" dataset: https://git.pcl.ac.cn/PCMachineTranslation/PCMT/src/branch/master/datasets
- Process data (change the directory)
bash sh_dir/process.sh
- Download m2m - 100 dict and checkpoint files from https://github.com/pytorch/fairseq/tree/master/examples/m2m_100
- Convert M2M-100 into MOE model
Python change_1.2b_to_16moe_version.py
- Start incremental MOE training
sh_dir/train-16MOe-silu-inhert.sh
Single V100 inference step (32G video memory is required)
- Convert the distributed MOE model to a single-card deployment
uer_dir/Comerge_16To1.py
- Test bleu on xx->zh/h->xx
sh_dir/Test-16Moe-multi-silu.sh
Function command
-
Switch from normal model to MOE model
python Change_1.2B_To_16Moe_Version.py
-
Convert distributed MOE model to single card deployment
python Comerge_16To1.py
-
Fine-tuning multilingual translation task
bash sh_dir/Train-16moe-SiLu-Inhert.sh 16 GShardGate 2
-
Test bleu on xx->zh and zh->xx direction
bash sh_dir/Test-16Moe-multi-silu.sh 0 xx
-
Data processing
bash sh_dir/process.sh
Service Invocation API
import requests
def Tongyan_Translate(sentences=None,direction=None,PyTorch_REST_API_URL = 'http://192.168.202.124:5000/predict'):
c_lgs=['Chinese (zh)', 'Italian (it)', 'German (DE)', 'Czech (cs)', 'Dutch (nl)', 'Portuguese (pt)',
'bahasa Indonesia (id)', 'Bulgarian (bg)', 'bosnia (bs)', 'Greek (el)', 'farsi (fa)', 'Croatian (hr)',
'Hungarian(hu)', 'Estonian (et)', 'Hebrew (he)' ,'Slovenia (sl)', 'polish (pl)', 'Turkish (tr)', 'Urdu (ur)']
lgs=['zh','it','de','cs','nl','pt','id','bg','bs','bs','el','fa','hr','hu','et','he','sl','pl','tr','ur']
src,tgt=direction.split("-")
if src not in lgs or tgt not in lgs:
print(f"Please enter the languages in the following collection in xx-XX format: \n{','.join(c_lgs)}")
return None
else:
payload = {'data': [direction,sentences]}
# Submit the request.
r = requests.post(PyTorch_REST_API_URL, data=payload).json()
if r['success']:
translations=[sent for sent in enumerate(r['predictions'])]
return translations
else:
return None
if __name__ == '__main__':
sentences = [
"I want to eat an apple ",
"Today is a fine day! ",
"Hello, I am THE senior engineer OF PCL XXX, please give me your advice!"
]
direction = "zh-pt"
res=Tongyan_Translate(sentences=sentences,direction=direction)
print(res)
Environments
fairseq 1.0.0a0+2fd9d8a
fastmoe 0.2.0
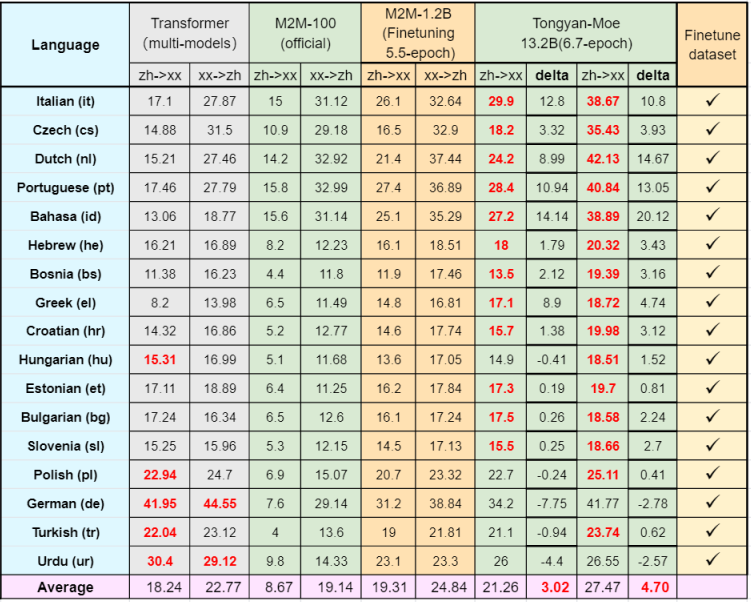
Model performance
Multilingual machine translation performance
Lifelong learning performance
