Contents
Many problems in image processing, computer graphics, and computer vision can be posed as “translating” an input image into a corresponding output image, each of these tasks has been tackled with separate, special-purpose machinery, despite the fact that the setting is always the same: predict pixels from pixels.
Our goal in this paper is to develop a common framework for all these problems. Pix2pix model is a conditional GAN, which includes two modules--generator and discriminator. This model transforms an input image into a corresponding output image. The essence of the model is the mapping from pixel to pixel.
Paper: Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros. "Image-to-Image Translation with Conditional Adversarial Networks", in CVPR 2017.
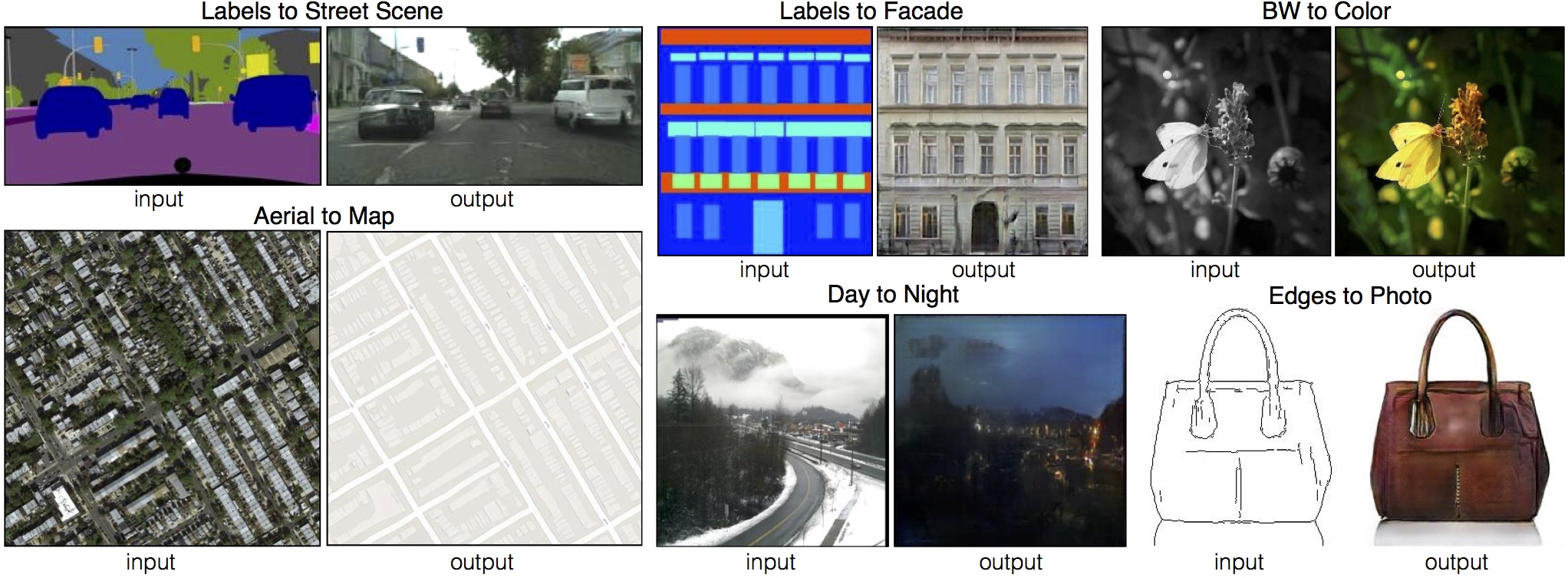
The Pix2Pix contains a generation network and a discriminant networks.In the generator part, the model can be any pixel to pixel mapping network (in the raw paper, the author proposed to use Unet). In the discriminator part, a patch GAN is used to judge whether each N*N patches is fake or true, thus can improve the reality of the generated image.
Generator(Unet-Based) architectures:
Encoder:
C64-C128-C256-C512-C512-C512-C512-C512
Decoder:
CD512-CD1024-CD1024-C1024-C1024-C512-C256-C128
Discriminator(70 × 70 discriminator) architectures:
C64-C128-C256-C512
Note: Let Ck denote a Convolution-BatchNorm-ReLU layer with k filters. CDk denotes a Convolution-BatchNorm-Dropout-ReLU layer with a dropout rate of 50%.
Dataset_1 used: facades
Dataset size: 29M, 606 images
400 train images
100 validation images
106 test images
Data format:.jpg images
Dataset_2 used: maps
Dataset size: 239M, 2194 images
1096 train images
1098 validation images
Data format:.jpg images
Note: We provide data/download_Pix2Pix_dataset.sh to download the datasets.
- Hardware(Ascend)
- Prepare hardware environment with Ascend processor.
- Framework
- For more information, please check the resources below:
- Python==3.8.5
- Mindspore==1.2
The entire code structure is as following:
.Pix2Pix
├─ README.md # descriptions about Pix2Pix
├─ data
└─download_Pix2Pix_dataset.sh # download dataset
├── scripts
└─run_infer_310.sh # launch ascend 310 inference
└─run_train_ascend.sh # launch ascend training(1 pcs)
└─run_distribute_train_ascend.sh # launch ascend training(8 pcs)
└─run_eval_ascend.sh # launch ascend eval
└─run_train_gpu.sh # launch gpu training(1 pcs)
└─run_distribute_train_gpu.sh # launch gpu training(8 pcs)
└─run_eval_gpu.sh # launch gpu eval
├─ imgs
└─Pix2Pix-examples.jpg # Pix2Pix Imgs
├─ src
├─ __init__.py # init file
├─ dataset
├─ __init__.py # init file
├─ pix2pix_dataset.py # create pix2pix dataset
├─ models
├─ __init__.py # init file
├─ discriminator_model.py # define discriminator model——Patch GAN
├─ generator_model.py # define generator model——Unet-based Generator
├─ init_w.py # initialize network weights
├─ loss.py # define losses
└─ pix2pix.py # define Pix2Pix model
└─ utils
├─ __init__.py # init file
├─ config.py # parse args
├─ tools.py # tools for Pix2Pix model
├─ eval.py # evaluate Pix2Pix Model
├─ train.py # train script
└─ export.py # export mindir script
Major parameters in train.py and config.py as follows:
"device_target": Ascend # run platform, only support Ascend.
"device_num": 1 # device num, default is 1.
"device_id": 0 # device id, default is 0.
"save_graphs": False # whether save graphs, default is False.
"init_type": normal # network initialization, default is normal.
"init_gain": 0.02 # scaling factor for normal, xavier and orthogonal, default is 0.02.
"load_size": 286 # scale images to this size, default is 286.
"batch_size": 1 # batch_size, default is 1.
"LAMBDA_Dis": 0.5 # weight for Discriminator Loss, default is 0.5.
"LAMBDA_GAN": 1 # weight for GAN Loss, default is 1.
"LAMBDA_L1": 100 # weight for L1 Loss, default is 100.
"beta1": 0.5 # adam beta1, default is 0.5.
"beta2": 0.999 # adam beta2, default is 0.999.
"lr": 0.0002 # the initial learning rate, default is 0.0002.
"lr_policy": linear # learning rate policy, default is linear.
"epoch_num": 200 # epoch number for training, default is 200.
"n_epochs": 100 # number of epochs with the initial learning rate, default is 100.
"n_epochs_decay": 100 # number of epochs with the dynamic learning rate, default is 100.
"dataset_size": 400 # for Facade_dataset,the number is 400; for Maps_dataset,the number is 1096.
"train_data_dir": None # the file path of input data during training.
"val_data_dir": None # the file path of input data during validating.
"train_fakeimg_dir": ./results/fake_img/ # during training, the file path of stored fake img.
"loss_show_dir": ./results/loss_show # during training, the file path of stored loss img.
"ckpt_dir": ./results/ckpt # during training, the file path of stored CKPT.
"ckpt": None # during validating, the file path of the CKPT used.
"predict_dir": ./results/predict/ # during validating, the file path of Generated images.
- running on Ascend with default parameters
python train.py --device_target [Ascend] --device_id [0] --train_data_dir [./data/facades/train]
- running distributed trainning on Ascend with fixed parameters
bash run_distribute_train_ascend.sh [DEVICE_NUM] [DISTRIBUTE] [RANK_TABLE_FILE] [DATASET_PATH] [DATASET_NAME]
- running on GPU with fixed parameters
python train.py --device_target [GPU] --run_distribute [1] --device_num [8] --dataset_size 400 --train_data_dir [./data/facades/train] --pad_mode REFLECT
OR
bash scripts/run_train_gpu.sh [DATASET_PATH] [DATASET_NAME]
- running distributed trainning on GPU with fixed parameters
bash run_distribute_train_gpu.sh [DATASET_PATH] [DATASET_NAME] [DEVICE_NUM]
python eval.py --device_target [Ascend] --device_id [0] --val_data_dir [./data/facades/test] --ckpt [./results/ckpt/Generator_200.ckpt] --pad_mode REFLECT
OR
bash scripts/run_eval_ascend.sh [DATASET_PATH] [DATASET_NAME] [CKPT_PATH] [RESULT_DIR]
python eval.py --device_target [GPU] --device_id [0] --val_data_dir [./data/facades/test] --ckpt [./train/results/ckpt/Generator_200.ckpt] --predict_dir [./train/results/predict/] \
--dataset_size 1096 --pad_mode REFLECT
OR
bash scripts/run_eval_gpu.sh [DATASET_PATH] [DATASET_NAME] [CKPT_PATH] [RESULT_PATH]
Note:: Before training and evaluating, create folders like "./results/...". Then you will get the results as following in "./results/predict".
bash run_infer_310.sh [The path of the MINDIR for 310 infer] [The path of the dataset for 310 infer] y Ascend 0
Note:: Before executing 310 infer, create the MINDIR/AIR model using "python export.py --ckpt [The path of the CKPT for exporting] --train_data_dir [The path of the training dataset]".
Training Performance on single device
| Parameters |
single Ascend |
single GPU |
| Model Version |
Pix2Pix |
Pix2Pix |
| Resource |
Ascend 910 |
PCIE V100-32G |
| MindSpore Version |
1.2 |
1.3.0 |
| Dataset |
facades |
facades |
| Training Parameters |
epoch=200, steps=400, batch_size=1, lr=0.0002 |
epoch=200, steps=400, batch_size=1, lr=0.0002, pad_mode=REFLECT |
| Optimizer |
Adam |
Adam |
| Loss Function |
SigmoidCrossEntropyWithLogits Loss & L1 Loss |
SigmoidCrossEntropyWithLogits Loss & L1 Loss |
| outputs |
probability |
probability |
| Speed |
1pc(Ascend): 10 ms/step |
1pc(GPU): 40 ms/step |
| Total time |
1pc(Ascend): 0.3h |
1pc(GPU): 0.8 h |
| Checkpoint for Fine tuning |
207M (.ckpt file) |
207M (.ckpt file) |
| Parameters |
single Ascend |
single GPU |
| Model Version |
Pix2Pix |
Pix2Pix |
| Resource |
Ascend 910 |
|
| MindSpore Version |
1.2 |
1.3.0 |
| Dataset |
maps |
maps |
| Training Parameters |
epoch=200, steps=1096, batch_size=1, lr=0.0002 |
epoch=200, steps=400, batch_size=1, lr=0.0002, pad_mode=REFLECT |
| Optimizer |
Adam |
Adam |
| Loss Function |
SigmoidCrossEntropyWithLogits Loss & L1 Loss |
SigmoidCrossEntropyWithLogits Loss & L1 Loss |
| outputs |
probability |
probability |
| Speed |
1pc(Ascend): 20 ms/step |
1pc(GPU): 90 ms/step |
| Total time |
1pc(Ascend): 1.58h |
1pc(GPU): 3.3h |
| Checkpoint for Fine tuning |
207M (.ckpt file) |
207M (.ckpt file) |
Distributed Training Performance
| Parameters |
Ascend (8pcs) |
GPU (8pcs) |
| Model Version |
Pix2Pix |
Pix2Pix |
| Resource |
Ascend 910 |
PCIE V100-32G |
| MindSpore Version |
1.4.1 |
1.3.0 |
| Dataset |
facades |
facades |
| Training Parameters |
epoch=200, steps=400, batch_size=1, lr=0.0002 |
epoch=200, steps=400, batch_size=1, lr=0.0002, pad_mode=REFLECT |
| Optimizer |
Adam |
Adam |
| Loss Function |
SigmoidCrossEntropyWithLogits Loss & L1 Loss |
SigmoidCrossEntropyWithLogits Loss & L1 Loss |
| outputs |
probability |
probability |
| Speed |
8pc(Ascend): 15 ms/step |
8pc(GPU): 30 ms/step |
| Total time |
8pc(Ascend): 0.5h |
8pc(GPU): 1 h |
| Checkpoint for Fine tuning |
207M (.ckpt file) |
207M (.ckpt file) |
| Parameters |
Ascend (8pcs) |
GPU (8pcs) |
| Model Version |
Pix2Pix |
Pix2Pix |
| Resource |
Ascend 910 |
PCIE V100-32G |
| MindSpore Version |
1.4.1 |
1.3.0 |
| Dataset |
maps |
maps |
| Training Parameters |
epoch=200, steps=1096, batch_size=1, lr=0.0002 |
epoch=200, steps=400, batch_size=1, lr=0.0002, pad_mode=REFLECT |
| Optimizer |
Adam |
Adam |
| Loss Function |
SigmoidCross55EntropyWithLogits Loss & L1 Loss |
SigmoidCrossEntropyWithLogits Loss & L1 Loss |
| outputs |
probability |
probability |
| Speed |
8pc(Ascend): 20 ms/step |
8pc(GPU): 40 ms/step |
| Total time |
8pc(Ascend): 1.2h |
8pc(GPU): 2.8h |
| Checkpoint for Fine tuning |
207M (.ckpt file) |
207M (.ckpt file) |
Evaluation Performance
| Parameters |
single Ascend |
single GPU |
| Model Version |
Pix2Pix |
Pix2Pix |
| Resource |
Ascend 910 |
PCIE V100-32G |
| MindSpore Version |
1.2 |
1.3.0 |
| Dataset |
facades / maps |
facades / maps |
| batch_size |
1 |
1 |
| outputs |
probability |
probability |
Please check the official homepage.