You can not select more than 25 topics
Topics must start with a chinese character,a letter or number, can include dashes ('-') and can be up to 35 characters long.
12 KiB
12 KiB
MSAdapter
MSAdapter is a MindSpore ecological adaptation tool, which quickly migrates three-party framework code such as PyTorch/JAX to the MindSpore ecosystem without changing the user's original usage habits, helping users efficiently use the Ascend computing power of the China Computing NET.
简体中文 | [English]
MindTorch




Introduction
MindTorch is MindSpore tool for adapting the PyTorch interface, which is designed to make PyTorch code perform efficiently on Ascend without changing the habits of the original PyTorch users.
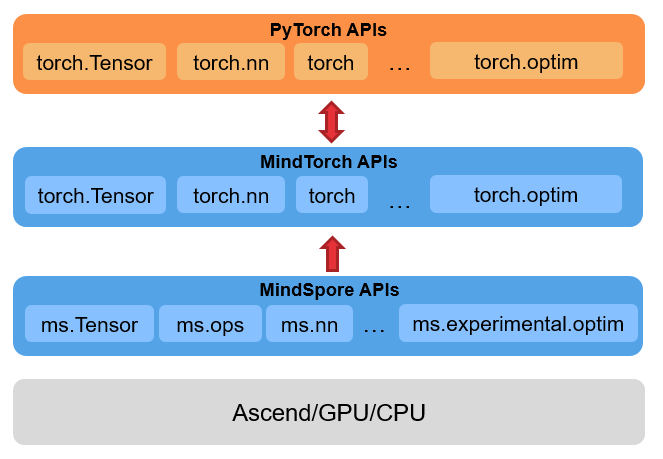
- PyTorch interface support: MindTorch currently supports most commonly used PyTorch APIs. The APIs usage remains unchanged, and is executed on the Ascend computing platform on MindSpore pynative or graph mode. You can check the interface support status in the Torch APIs supported list.
- TorchVision interface support: MindTorch TorchVision is a computer vision tool library migrated from PyTorch's official implementation. It continues to use PyTorch's official api design, and calls
MindSporeoperators for calculations to achieve the same functions as the originaltorchvisionlibrary.
TorchVision support status can be found from TorchVision APIs supported list.
Docs
More details about installation guide, tutorials and APIs, please see the tutorial documentation.
Getting started
Install
Please check the Version Description to select the required version of MindTorch and MindSpore.
Install MindSpore
Please install MindSpore according to the Installation Guide on MindSpore official website.
Install MindTorch
via pip
pip install mindtorch (MindSpore version >= 2.2.1)
or
pip install msadapter (MindSpore version == 2.0.0)
via source code
git clone https://git.openi.org.cn/OpenI/MSAdapter.git
cd MSAdapter
python setup.py install
If there is an insufficient permissions message, install as follows
python setup.py install --user || exit 1
Using MindTorch
After installing MindTorch, you can start using it straight away, for example:
Import mstorch_enable in the main program of the code file to adapt PyTorch code to MindTorch
from mindtorch.tools import mstorch_enable # It needs to be used before importing torch related modules in the main program
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
# 1.Working with data
# Download training data from open datasets.
training_data = datasets.FashionMNIST(root="data", train=True, download=True, transform=ToTensor())
# Download test data from open datasets.
test_data = datasets.FashionMNIST(root="data", train=False, download=True, transform=ToTensor())
# 2.Creating Models
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10)
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
def train(dataloader, model, loss_fn, optimizer, device):
size = len(dataloader.dataset)
model.train()
for batch, (X, y) in enumerate(dataloader):
X, y = X.to(device), y.to(device)
# Compute prediction error
pred = model(X)
loss = loss_fn(pred, y)
# Backpropagation
loss.backward()
optimizer.step()
optimizer.zero_grad()
if batch % 100 == 0:
loss, current = loss.item(), (batch + 1) * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
def test(dataloader, model, loss_fn, device):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
if __name__ == '__main__':
train_dataloader = DataLoader(training_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# Get cpu, gpu or mps device for training.
device = (
"cuda"
if torch.cuda.is_available()
else "mps"
if torch.backends.mps.is_available()
else "cpu"
)
model = NeuralNetwork().to(device)
# 3.Optimizing the Model Parameters
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
epochs = 5
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train(train_dataloader, model, loss_fn, optimizer, device)
test(test_dataloader, model, loss_fn, device)
print("Done!")
# 4.Saving Models
torch.save(model.state_dict(), "model.pth")
print("Saved PyTorch Model State to model.pth")
# 5.Loading Models
model = NeuralNetwork().to(device)
model.load_state_dict(torch.load("model.pth"))
classes = [
"T-shirt/top",
"Trouser",
"Pullover",
"Dress",
"Coat",
"Sandal",
"Shirt",
"Sneaker",
"Bag",
"Ankle boot",
]
# 6.Predicted
model.eval()
x, y = test_data[0][0], test_data[0][1]
with torch.no_grad():
x = x.to(device)
pred = model(x)
predicted, actual = classes[pred[0].argmax(0)], classes[y]
print(f'Predicted: "{predicted}", Actual: "{actual}"')
After importing mstorch_enable, the imported module with the same name of torch will be automatically converted to the corresponding module of mindtorch when the code is executed (currently supports automatic conversion of torch, torchvision, torchaudio related modules), and then execute the .py file of the main program. For more information on how to use it, please refer to User's Guide.
Resources
- Model library: MindTorch supports rich deep learning applications, migration to MindTorch models from the official PyTorch code is given in: MSAdapterModelZoo. Welcome contributions.
Version Description
| Branch | Version | Initial Release Date | MindSpore Version | OpenI Computing Resources |
|---|---|---|---|---|
| master | - | - | MindSpore 2.3.0 | - |
| release_0.3 | 0.3 | 2024-04-29 | MindSpore 2.3.0-rc1 | - |
| release_0.2 | 0.2.1 | 2024-02-01 | MindSpore 2.2.1 / MindSpore 2.2.10 | China Computing NET - Image:mindtorch0.2_mindspore2.2.1_torchnpu2.1.0_cann7.0rc1 |
| release_0.1 | 0.1 | 2023-06-15 | MindSpore 2.0.0 | - |
- For the released version of MindTorch, please refer to RELEASE.
- The MindSpore is recommended to be obtained from the MindSpore official website or from our data resources.
Intermediate Version:
- For MindSpore 2.2.1, and the package name of "msadapter" is still used in the user script (The package name has been changed from "msadapter" to "mindtorch", it is recommended to use Tools to switch to "mindtorch" with one click)
pip install git+https://openi.pcl.ac.cn/OpenI/MSAdapter.git@da13b6719c - For MindSpore 2.1.0:
pip install git+https://openi.pcl.ac.cn/OpenI/MSAdapter.git@59f62a1858
On Going and Future Work
- Supports the Torch automatic differentiation APIs.
- Supports Torch distributed APIs.
- Network performance optimization.
Contributing
Developers are welcome to contribute. For more details, please see our Contribution Guidelines.
Join us
If you have any questions or suggestions, please join MSAdapter SIG for discussion.
