Reinforce learning SIG
1. Background
Reinforcement learning (RL) is a machine learning method based on rewarding desired behaviours and/or punishing undesired ones. In general, reinforcement learning agents are able to perceive and interpret their environment, take actions, and learn through trial and error. After the success of AlphaGo, reinforcement learning attracted broader attention and has been applied in many fields.
Currently, the traditional AI framework is used for the simulation and application of RL algorithm. Due to the flexibility of its interfaces, some basic framework code needs to be developed repeatedly. MindSpore Reinforcement supports scalable distributed multi-agent heterogeneous hardware training and also provides intuitive algorithm programming abstraction. Users are welcome to actively participate in the MindSpore Reinforcement Learning Community and provide feedback. Your feedback is of great importance for the future development of MindSpore Reinforcement.
2. Objectives
The reinforcement learning SIG will focus on the development and research progress of the reinforcement learning computing framework, and practical applications in various scenarios. In particular, it will focus on optimising the high-performance and scalable reinforcement learning distributed computing framework based on MindSpore and providing continuously growing classical algorithm libraries, which enables researchers to carry out research work of their interest in an easier way. The focus of the group includes the following areas:
- Accelerate the application of MindSpore Reinforcement in practical scenarios and the continuous evolution of the framework.
- Share the research progress of reinforcement learning in algorithms, distributed training, and performance optimisation.
- Organize workshops on algorithms built based on MindSpore Reinforcement and distributed training.
- Promote effective communication between users, developers, and researchers of MindSpore Reinforcement.
- Build an open platform for comparing reinforcement learning algorithms.
3. Proposal
To address the limitations of existing reinforcement learning frameworks, suggestions and contributions are welcome in the following areas:
- Programming framework: The programming framework includes algorithm APIs such as actor and learner, and core components such as replay buffer and policy.
- Algorithm examples: The code repository contains the algorithm library and has implemented some common reinforcement learning algorithms. More algorithms will be added in the future.
- Simulation environment: Common environments include gym and mujoco. Diverse simulation environments and higher sampling efficiency contribute to the research and application of reinforcement learning.
- Training performance: The training performance is affected by many factors, including operator performance and inter-process communication optimisation. Any suggestions for performance improvements are welcome.
4. Architecture Framework
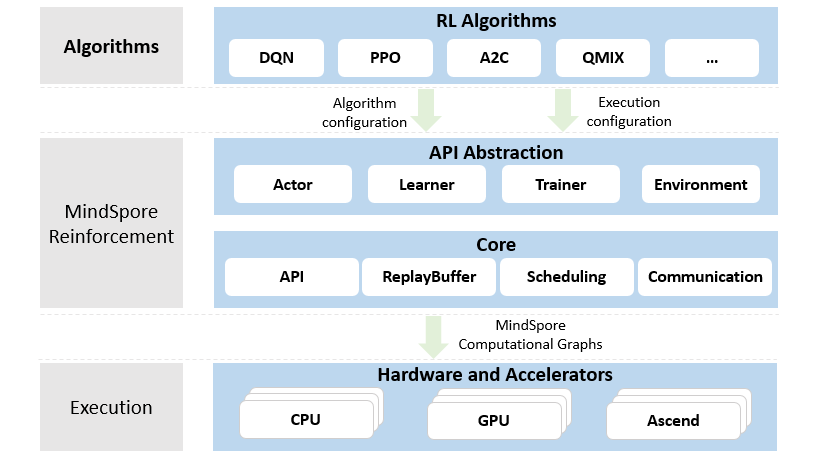
Reinforcement Learning Algorithm Development and Multi-Agent Distributed Training
MindSpore Reinforcement provides a clean API abstraction for writing reinforcement learning algorithms. It decouples algorithms from deployment and execution, including the use of hardware accelerators, parallelism, and distribution of cross-process computing. MindSpore Reinforcement converts the reinforcement learning algorithm into a series of compiled computation graphs, and runs them efficiently on Ascend, GPU and CPU based on MindSpore Framework.
Reinforcement learning code link https://gitee.com/mindspore/reinforcement
5. Work Plan
- Initial Phase: Share the research progress of reinforcement learning algorithms, multi-agent reinforcement learning, scalable distributed training, and performance optimisation, discuss the challenges encountered by academic research and industry applications and provide reference for the evolution of MindSpore Reinforcement.
- Interim: Carry out collaborative research in the community through cooperative development and other modes to promote the implementation of more scenarios.
- Later Phase: Carry out collaborative research on intensive learning worldwide.
6. Group Members
- Team leader: Rongpeng Li, Associate Professor, School of Information and Electronic Engineering, Zhejiang University
- Member: Peter Pietzuch, Professor, Department of Computer Science, Imperial College London
- Member: Huanzhou Zhu, Postdoctoral Fellow, Department of Computer Science, Imperial College London
- Member: Bo Zhao, Postdoctoral Fellow, Department of Computer Science, Imperial College London
- Member: Cristobal, Huawei Shengsi MindSpore Engineer
- Member: Wilfchen, Huawei Shengsi MindSpore Engineer
- Member: VectorSL, Huawei Shengsi MindSpore Engineer
- Member: Chen Yijie6, Huawei Shengsi MindSpore Engineer
- Member: Selina, Huawei Shengsi MindSpore Evangelist