 avadesian
avadesian tanglj
tanglj






Deleting a branch is permanent. It CANNOT be undone. Continue?
Loading…
There is no content yet.
Delete Branch '%!s(MISSING)'
Deleting a branch is permanent. It CANNOT be undone. Continue?
Dear OpenI User
Thank you for your continuous support to the Openl Qizhi Community AI Collaboration Platform. In order to protect your usage rights and ensure network security, we updated the Openl Qizhi Community AI Collaboration Platform Usage Agreement in January 2024. The updated agreement specifies that users are prohibited from using intranet penetration tools. After you click "Agree and continue", you can continue to use our services. Thank you for your cooperation and understanding.
For more agreement content, please refer to the《Openl Qizhi Community AI Collaboration Platform Usage Agreement》
活动介绍
为了更好的帮助和推动国产芯片发展,鼓励大家使用平台国产芯片,社区联合燧原科技将结合打榜活动开展一系列GCU相关开源活动,4.10-4.16开启GCU热身之旅,凡参与以下任务并按要求输出相应结果与心得,由平台审核通过后可在打榜活动基础活跃榜中获得20积分/任务(每个任务每个用户仅加分一次)。
同时,平台GCU不消耗算力积分!平台GCU不消耗算力积分!平台GCU不消耗算力积分!
参与本周期热身活动并表现优异的小伙伴将额外获得活动专属礼物(限3名)。
案例地址:
1、https://openi.pcl.ac.cn/Enflame/GCU_PaddlePaddle_Example
2、https://openi.pcl.ac.cn/Enflame/GCU_Pytorch1.10.0_Example
3、https://openi.pcl.ac.cn/Enflame/GCU_Pytorch_Mnist
任务一: 基于PyTorch + GCU跑通ResNet50或Bert_base模型并测试GCU性能
任务二:基于PaddlePaddle + GCU跑通模型并测试GCU性能
请将热身心得链接附在小白训练营本Issue评论中,心得内容要求包含:
欢迎对GCU感兴趣的小伙伴扫码入群交流
任务二:基于PaddlePaddle + GCU跑通模型并测试GCU性能
resnet50
1.GCU单卡或8卡至少支持1个模型
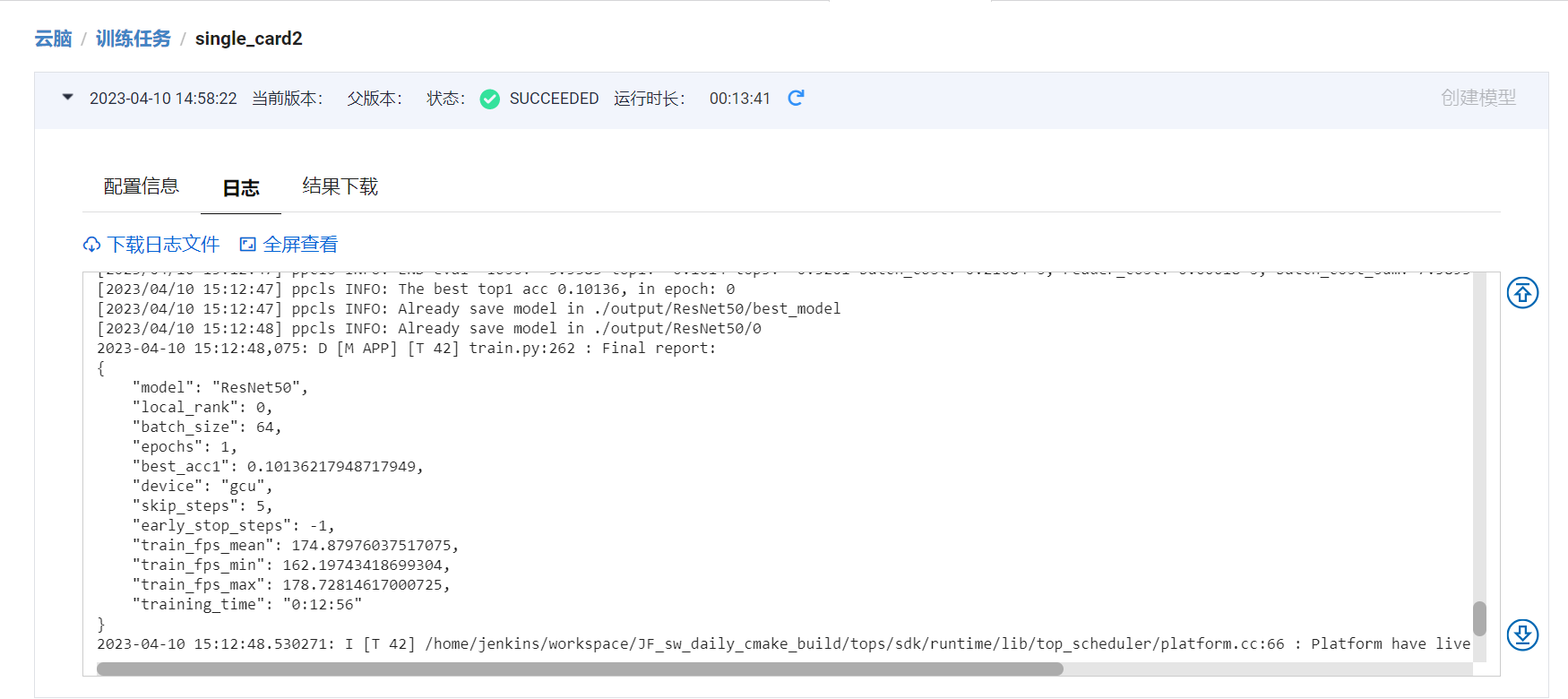
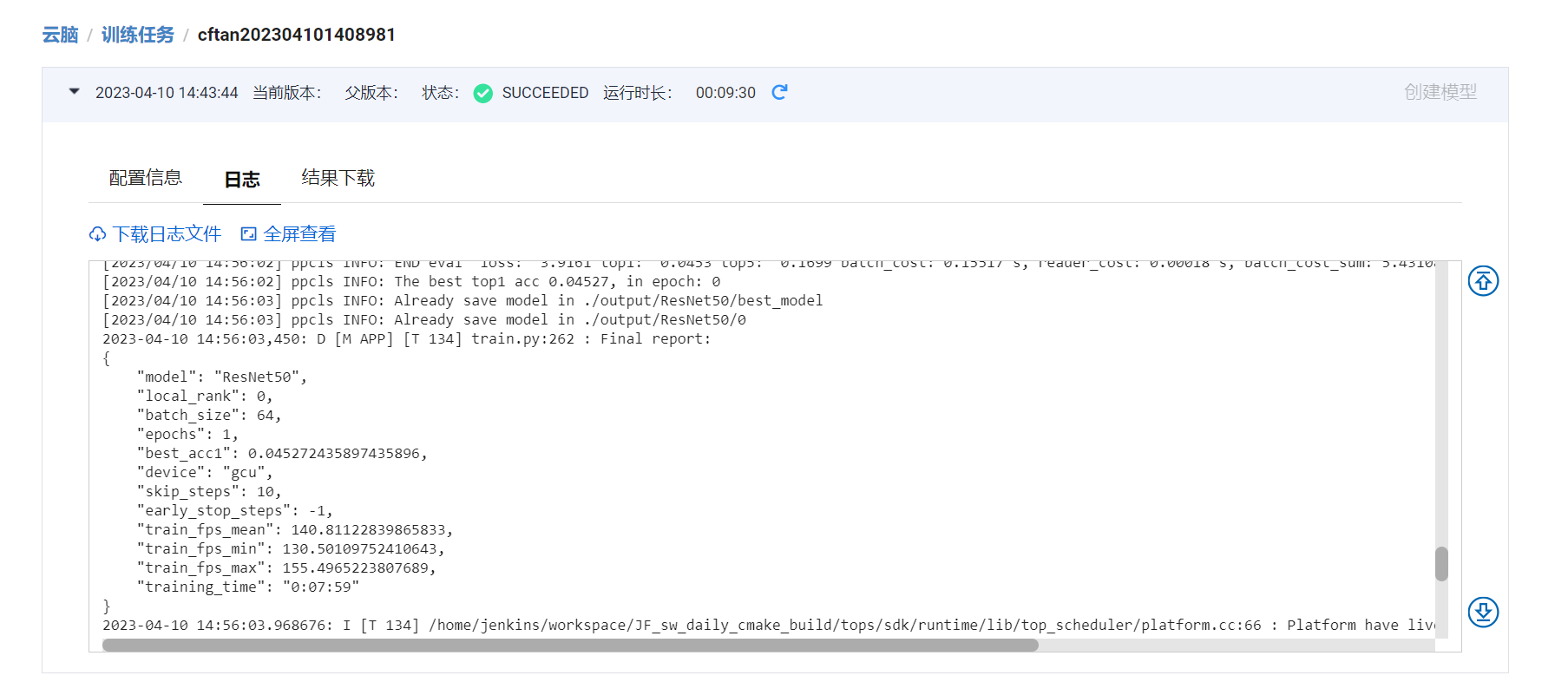
1.1 单卡 epoch=1
1.2 8卡 epoch=1
2.统计GCU单卡/8卡线性度: 8卡FPS/(单卡FPS*8)
8卡
"train_fps_mean": 140.81122839865833,
单卡
"train_fps_mean": 174.87976037517075,
线性度 = 0.80518882286077608658489404384979
任务一:https://blog.csdn.net/yichao_ding/article/details/130080698
这个修正为任务二的链接
任务一的链接是这个:https://blog.csdn.net/yichao_ding/article/details/130081018
run_resnet50_8card.py这个是不是有问题啊,我配置环境每次运行,不到一分钟都显示successed,但是实际上应该是failed,在logs里并没有看到与单卡相似的输出。
我这里运行正常的,能正常跑起来
飞桨:
Pytorch:
任务一: 基于PyTorch + GCU跑通ResNet50或Bert_base模型并测试GCU性能
GCU单卡或8卡跑通resnet50、bert_base其中1个模型
修改其中一个模型的bs或epoch跑通resnet50、bert_base其中1个模型,以resnet50为例acc1>75,bert_base为例f1>87
统计GCU单卡/8卡线性度: 8卡FPS/(单卡FPS*8)
| 线性度=694.555028113764/(8*706.0710535424497)=0.12296124884122704 |
总结
基于Pytorch+GCU跑通ResNet50模型并测试其性能,GCU_1card_1epoch这个测试是最好跑的,相对的,其他的就是有点坑了。简单看下启动文件,找到模型的配置文件,修改epoch,其他参数默认。使用GCU_8card_100epochs,甚至GCU_8card_1epoch,好像logs有问题,最初是程序2分钟内玄学运行结束,进群问了大佬,晾了程序一夜之后突然就可以了。但还是会存在logs不能稳定输出的情况,简直是魔鬼啊,运行了1个多点,看不到运行结果,呜呜呜。简单看一下,GCU_1card_1epoch的acc竟然比GCU_8card_1epoch的高,而与paddle相比,训练100轮pytorch的acc还没有到75,而且时间也较长一点,这是pytorch没有优化好吗?唔,我以为是没有收敛,就多训练了50轮,没想到效果这么差,时间有限,搞不动了
心得
Epochs数量较少多卡acc,运行时间的优势都不太明显
飞桨在GCU下运行resnet+imagenet_raw总体感觉速度比torch在GCU下面运行的快,收敛速度更快,实验做的少,基于目前的资料是这个样子
建议
GCU平台操作的话示例比较简单,自己布置很麻烦,接口很复杂,用GCU还要重新改程序,移植开发难度太高了
GCU平台现在不需要支持更多的框架,但是需要有自己的优势,适应场景,如果太泛泛,兼容性还不好,那没有必要使用
训练时logs多次没有相应输出,程序应该还是有bug
另外,云脑的GPU、NPU很复杂,现在还有GCU,希望教程多一点
任务1(pythorch):
任务2(paddle):
1. 单卡dbnet:
{
"model": "DBnet",
"local_rank": 0,
"batch_size": 16,
"epochs": 100,
"best_eval_hmean": 0.39548022598870053,
"skip_steps": 5,
"train_fps_mean": 29.211012213276934,
"train_fps_min": 10.442378444051494,
"train_fps_max": 53.38021899702987,
"training_time": "0:36:10"
}
总结&建议:
1. log突然间没了,以为是自己的问题,查看又是running状态,神了。然后修改sh文件打开log,满屏打印吓死个人,这是基本功,感觉没法接受
2. 有几个没跑通,提了几个问题,希望能够处理,另外有几次都要排队,等了好久
3. 建议启智增加tensorboard,以便查看accurate和loss曲线,这应该是一个基础项
4. 建议多一些迁移文档,期望每个模型都有示例从v100切换到gcu,要改哪些,缺少这类的文档和介绍
5. paddle FPS波动大,train_fps_mean vs train_fps_max
修改哪里的sh文件啊,修改一些什么啊
我也来跑
1. pytorch+resnet:
- 单卡(https://openi.pcl.ac.cn/huang2007/GCU_Pytorch_test/grampus/train-job/a8a3b0d6ea024b10b15a728da687e8cc)
2023-04-14 14:17:44,572: D [M APP] [T 53] train.py:419 : Final report:
{
"model": "resnet50",
"local_rank": 0,
"batch_size": 256,
"epochs": 1,
"acc1": 10.677083015441895,
"acc5": 34.50520706176758,
"device": "dtu",
"skip_steps": 2,
"train_fps_mean": 709.8853026525236,
"train_fps_min": 667.3509740321892,
"train_fps_max": 757.2675842574596,
"training_time": "0:12:34"
}
2. paddlepaddle+resnet50
- 单卡(https://openi.pcl.ac.cn/huang2007/paddlepaddle/grampus/train-job/hcee3888375a4cc0a8f07b3eb4c71282)
2023-04-14 14:34:29,783: D [M APP] [T 42] train.py:262 : Final report:
{
"model": "ResNet50",
"local_rank": 0,
"batch_size": 64,
"epochs": 1,
"best_acc1": 0.12540064102564102,
"device": "gcu",
"skip_steps": 5,
"train_fps_mean": 188.0064930505954,
"train_fps_min": 175.83622926958998,
"train_fps_max": 190.35572926184304,
"training_time": "0:12:23"
}
3. 建议
1、 启智可以显示任务占用的资源情况,如cpu%,加速卡%,mem%,温度等等
2、 如上建议,增加tensorboard,方便查看结果曲线
3、 log经常获取失败
4、 启动任务时每次都需要download&unzip data,等待比较久,是否考虑增加只读的共享数据集方案(如果读写速度允许),可以省去非必要拷贝
任务1(pythorch):
bert_base
场景 卡 epochs train_batch_size predict_batch_size train_fps_mean exact_match f1 线性度
a 1 1 48 48 67.94706955 79.61210974 87.08313104
b 1 10 48 48 68.29758169 79.02554399 87.23861865
c 8 1 48 48 64.43498743 78.94985809 86.47563451 0.9483115
d 8 10 48 48 63.775345 78.11731315 86.64708563 0.933786284
e 8 100 24 24 23.92116933 77.61589404 85.68731233
根据场景c/a计算线性度=0.9483115(64.43498743/67.94706955)
根据场景d/b计算线性度=0.933786284(68.29758169/63.775345)
问题:单卡,100 epochs,train_batch_size=96时直接报line 46: 42 Illegal instruction (core dumped),可能内存不够了,最好有报错信息返回
./TopsRider_t2x_2.1.52_samples/samples/model/torch/single_card/run_pytorch_bert_base_convergence_test.sh: line 46: 42 Illegal instruction (core dumped) python3 -u ./run_squad.py --device=dtu --do_train --do_predict --do_eval --train_batch_size=96 --predict_batch_size=96 --learning_rate=3e-5 --num_train_epochs=100 --max_steps=-1 --max_seq_length=384 --doc_stride=128 --do_lower_case --bert_model=bert-base-uncased --print_freq=20 --skip_steps=5 --init_checkpoint=${DATASET_DIR}/pytorch_bert_base/bert_base_init/bert_base.pt --train_file=${DATASET_DIR}/pytorch_bert_base/squad/v1.1/train-v1.1.json --predict_file=${DATASET_DIR}/pytorch_bert_base/squad/v1.1/dev-v1.1.json --vocab_file=${DATASET_DIR}/pytorch_bert_base/bert_base_init/vocab.txt --config_file=${DATASET_DIR}/pytorch_bert_base/bert_base_init/bert_config.json --eval_script=${DATASET_DIR}/pytorch_bert_base/squad/v1.1/evaluate-v1.1.py --output_dir=./output > ${LOG_FILE} 2>&1
一. 用户完成任务加分情况:
cftang ——完成任务1+任务2,加30积分(缺少心得,但表现最积极,获得GCU礼品一份)
JeffDing ——完成任务1+任务2,加40积分 (获得礼品一份)
Susie134244 ——完成任务1+任务2,加40积分 (获得礼品一份)
ArFFy ——完成任务1,加20积分(心得总结最佳,获得GCU礼品一份)
请以上用户通过GCU微信交流群联系群主zeizei,发送联系人收货地址~
二. 建议:
对于启智:
对于GCU:
三. ISSUE待解决: