Are you sure you want to delete this task? Once this task is deleted, it cannot be recovered.
You can not select more than 25 topics
Topics must start with a chinese character,a letter or number, can include dashes ('-') and can be up to 35 characters long.
 taoht
21c4e444fd
taoht
21c4e444fd
|
1 year ago | |
|---|---|---|
| .idea | 1 year ago | |
| docs | 1 year ago | |
| mPanGu_alpha_GPU | 1 year ago | |
| mPanGu_alpha_NPU | 1 year ago | |
| LICENSE | 2 years ago | |
| README.md | 1 year ago | |
README.md
mPanGu-Alpha-53
mPanGu-α-53 来源于鹏程·PanGu-α,基于一带一路多语言翻译场景应用,基于“鹏城云脑2”128卡在自行构建的2TB高质量多语言单双语语料集上进行预训练+混合语料训练,得到2.6B预训练多语言模型+2.6B一带一路53种语言机器翻译模型,支持多语言翻译任务的“迁移学习”,支持在NPU/GPU上基于MindSpore分布式训练(最少8卡)、推理(全精度/FP16,1卡),单模型支持53种语言任意两种语言间的互译。在WMT2021多语言任务赛道,在FLORES-101 devtest数据集,对比任务榜单No.1已覆盖的50种语言“中<->外”100个翻译方向平均BLEU值提升0.354
目前GPU/NPU两个版本是因为MindSpore使用版本不同,‘鹏城云脑2’NPU目前支持的MindSpore主流版本是1.3, GPU平台使用MS1.6版本的适配性更好
实现流程
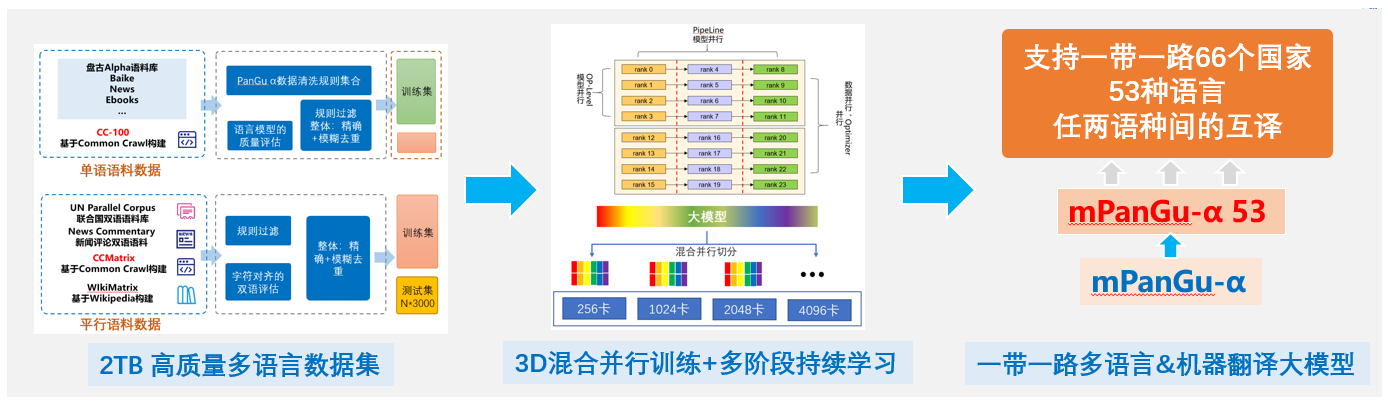
| 阶段 | 学习率 | warmup | beta1 | beta2 | batchsize | steps | 等效token |
|---|---|---|---|---|---|---|---|
| 预训练 | 1e-4~1e-6 | 2000 | 0.9 | 0.94 | 512 | 915000 | 480 B |
| 混合增量学习 | 5e-5~5e-7 | 2000 | 0.9 | 0.94 | 512 | 765000 | 400 B |
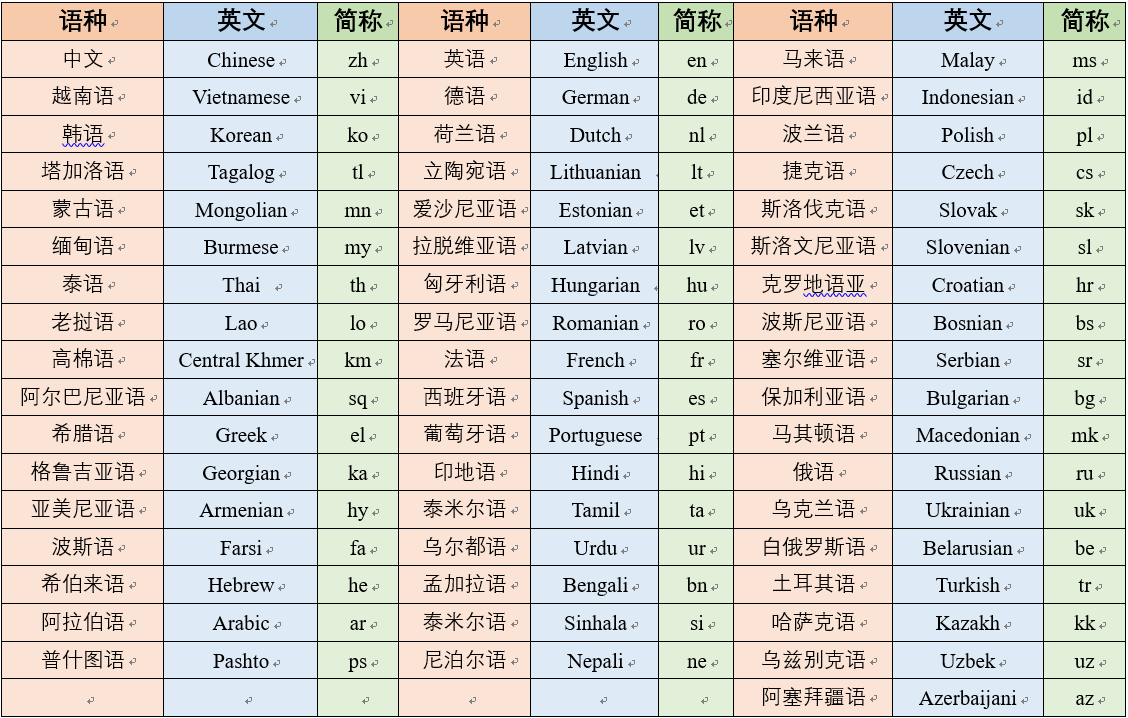
支持语种
环境要求
GPU运行环境
- mPanGu_alpha_GPU, 建议cuda版本在11.1-11.3,其他版本未测试过可能存在兼容性问题
MindSpore 1.6.1
- docker镜像
docker pull hengtao2/mindspore:gpu_ms_1.6.1
或者使用MindSpore官方在Docker Hub上托管的Docker镜像。
NPU运行环境
- mPanGu_alpha_NPU
MindSpore 1.3
基于“鹏城云脑2”+ModelArts,运行在C76版本环境(同OpenI启智协作平台NPU训练任务环境)
靶场环境运行
AI靶场是基于方滨兴院士提出的“数据不动程序动、数据可用不可见、分享价值不分享数据、保留所有权释放使用权”隐私保护新理念, 在鹏城实验室构建的数据要素流通交易新型基础设施平台。通过调试环境与运行环境分离体系架构以及仿真数据生成、隐私保护前提下的调试等创新技术,确保数据所有权和使用权分离,可以让更多的数据提供方敢于将其数据安全托管,让更多的数据使用方能够充分挖掘真实场景真实数据。
基于靶场的mPanGu,单机、多卡+单方、多方数据协同训练场景
AiSynergy协同运行
模型文件下载
| 模型 | 大小 | 来源 | md5 |
|---|---|---|---|
| 鹏程·mPanGu-α-53 FP32 | 11.8 G | 2.6B 多语言预训练 | ed76089e93d097e1991b1575f57af12e |
| 鹏程·mPanGu-α-53 FP16 | 6.56 G | 2.6B 多语言预训练 | 3f2ecdb3860b1b28d9022c6be5dd4f90 |
| 鹏程·mPanGu-α-53 FP32 | 10.9 G | 2.6B 多语言翻译 | f5538e265017c8ed78a3121883a80b04 |
| 鹏程·mPanGu-α-53 FP16 | 5.62 G | 2.6B 多语言翻译 | 4e778059c6c519ec29d64159f8a2dd1a |
数据开源
我们的数据基于Ai靶场环境进行开源开放
| 数据集 | 数据使用权限申请 | 描述 | 数据名称 |
|---|---|---|---|
| 一带一路多语言1T数据集 | 如有使用数据集的需求,请邮件反馈至 taoht@pcl.ac.cn | 每个文件为该语种单或双语抽样语料,目前包含52种语种数据,语料来自于PanGu-Alpha中文语料、CC-100、CCMatrix、UN Parallel Corpus、WMT等经过规则过滤、全局精确和模糊去重、双语字符对齐过滤等清洗流程得到 | B&R-M-1T |
数据:邮件提交使用者信息,项目标注数据来源,完全开源开放,请联系:taoht@pcl.ac.cn
模型:mPanGu-α、 mPanGu-α-53全开源(FP32、FP16)
代码: GPU/NPU双平台支持,训练、推理全开源,支持AIsynergy跨集群协同训练
运行环境:OpenI启智协作平台(GPU/NPU)
技术交流:鹏程盘古α技术交流群、 OpenI启智社区
数据处理
快速入门
1分钟在OpenI AI协作平台实现训练
- 参考本项目->云脑(标题栏) ->训练任务 ->taoht-npu-train-example ->修改 ->新建任务
- 详细步骤可查看npu分支
- master分支启动文件(加上目录结构): mPanGu_alpha_NPU/train.py
GPU推理
./mPanGu_alpha_GPU/
1、脚本启动
bash scripts/run_distribute_inference.sh #启动脚本
8 #使用卡数
hostfile_8gpus #hostfile文件
2.6B #模型规模
'8,9,10,11,12,13,14,15' #使用的卡id
bash scripts/run_distribute_inference.sh 8 /tmp/hostfile_8gpus 2.6B '8,9,10,11,12,13,14,15'
2、命令行启动
# 以单卡推理为例
mpirun --allow-run-as-root -x PATH -x LD_LIBRARY_PATH -x PYTHONPATH -x NCCL_DEBUG -x GLOG_v \
-n 1 \#使用卡数
--hostfile hostfile_1gpus \
--output-filename log_output \
--merge-stderr-to-stdout \
python -s /path/to/predict.py \
--mode 2.6B \
--run_type predict \
--distribute false \
--op_level_model_parallel_num 1 \#同使用卡数保持一致
--load_ckpt_path /path/to/ckpt_path/ \
--load_ckpt_name /ckpt_name \
--param_init_type "fp16" #"fp16" or "fp32"
NPU推理
ModelArts启动任务,启动文件predict.py
运行参数配置:
device_num=1
op_level_model_parallel_num=1
run_type=predict
资源选择:
Ascend: 1 * Ascend-910(32GB) | ARM: 24 核 256GB
GPU训练
运行如下命令开始训练,2.6B 单机16卡GPU运行
bash scripts/run_distribute_train_gpu.sh
16 #使用卡数
hostfile #hostfile文件
dataset/test/ #训练集
8 #batchsize
2.6B #模型规模
bash scripts/run_distribute_train_gpu.sh 16 /tmp/hostfile dataset/test/ 8 2.6B
NPU训练
ModelArts启动任务(以8卡为例),启动文件train.py
模型相关配置位于./src/utils.py和./src/pangu_alpha_config.py
运行参数配置:
data_url=数据集目录
device_num=8
op_level_model_parallel_num=1(1或8都可以)
per_batch_size=8
mode=2.6B (指模型大小350M/2.6B/13B/200B...)
full_batch=1
run_type=train
资源选择:
Ascend: 8 * Ascend-910(32GB) | ARM: 192 核 2048GB
测评结果
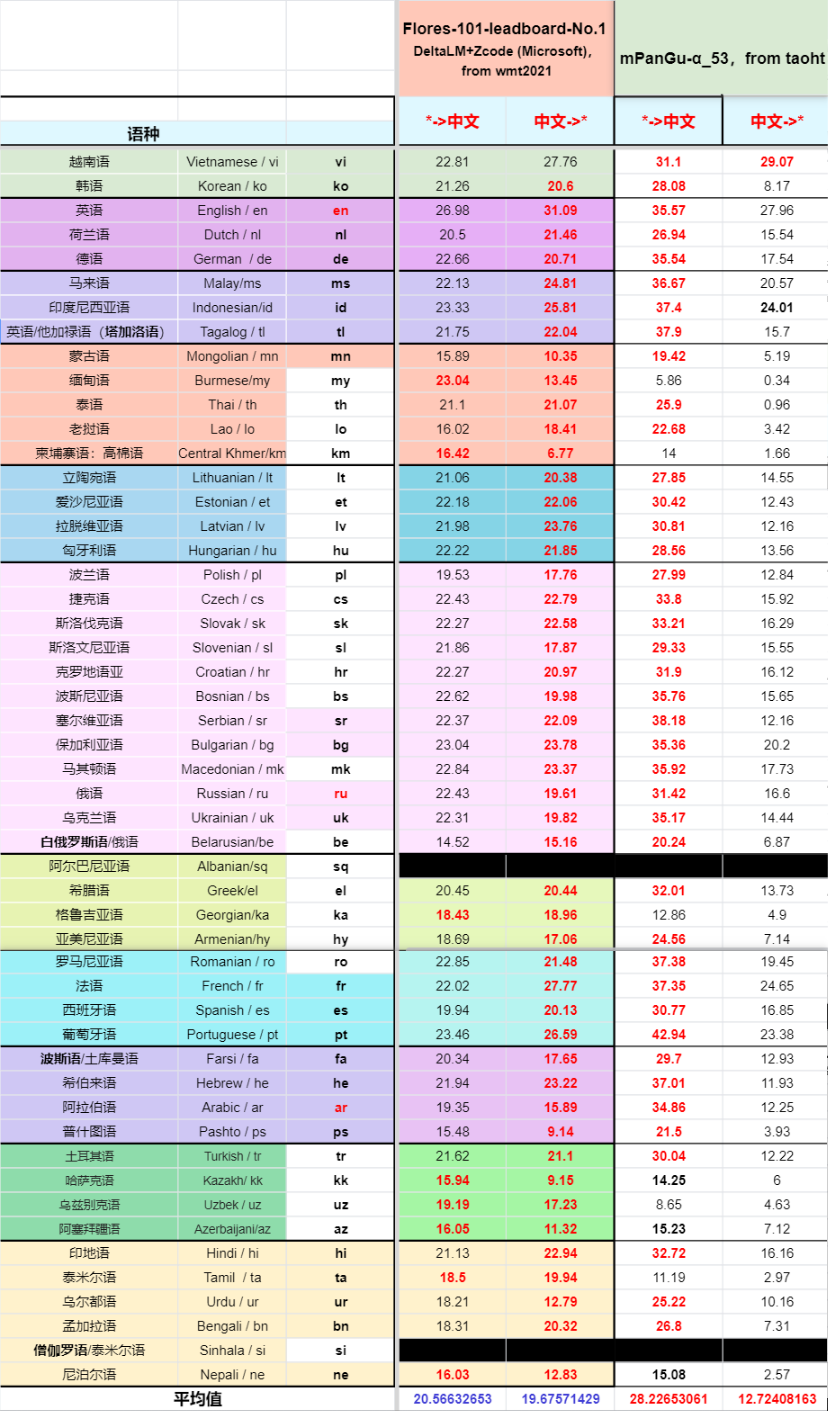
- 在官方devtest数据集“中<->外”翻译方向,对比WMT2021 “多语言赛道”No.1得分的结果
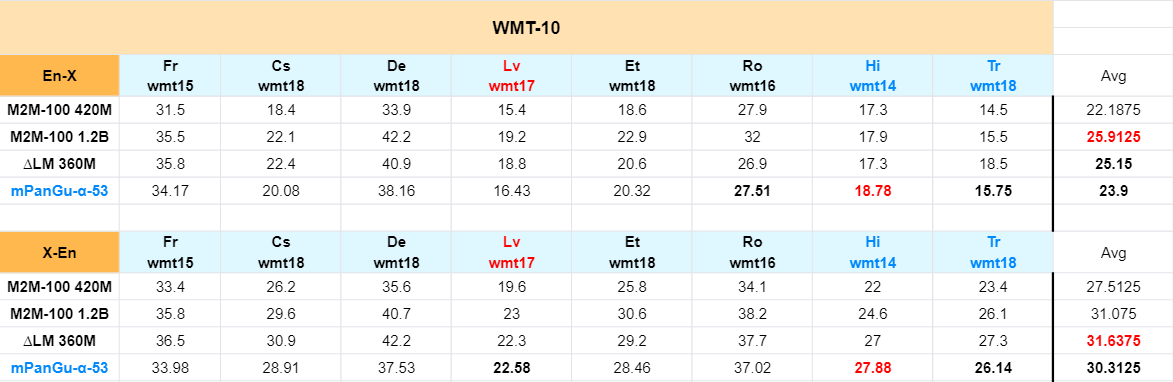
- 对比Facebook M2M-100、Microsoft delta LM等多语言模型论文中在“英<->外”翻译方向的结果对比
交流通道
- 提问:https://git.openi.org.cn/PCL-Platform.Intelligence/mPanGu-Alpha-53/issues
- 邮箱:taoht@pcl.ac.cn
- 微信群: 添加微信(备注交流群)加入技术交流群

项目信息
鹏城实验室-智能部-开源所-基础技术研究室
许可证
mPanGu-α-53是首个以中文为中心的多语言&机器翻译模型,在一带一路沿线66个国家53种语种上进行预训练和单双语混合增量训练,单模型支持一带一路53个语种任两语种间的互译,对比WMT2021多语言任务赛道No.1在”中外“100个方向上平均BLEU值提升0.354,支持在NPU/GPU上基于MindSpore分布式训练(最少8卡)、推理(全精度/FP16,1卡)和多语言任务的迁移学习。
Text Python
Apache-2.0
