Are you sure you want to delete this task? Once this task is deleted, it cannot be recovered.
You can not select more than 25 topics
Topics must start with a chinese character,a letter or number, can include dashes ('-') and can be up to 35 characters long.
 xutianbao
b0e1a3866d
xutianbao
b0e1a3866d
|
1 year ago | |
|---|---|---|
| cfgs | 1 year ago | |
| data | 1 year ago | |
| datasets | 1 year ago | |
| extensions/chamfer_dist | 1 year ago | |
| figure | 1 year ago | |
| model_zoo | 1 year ago | |
| models | 1 year ago | |
| part_segmentation | 1 year ago | |
| semantic_segmentation | 1 year ago | |
| tools | 1 year ago | |
| utils | 1 year ago | |
| .gitignore | 1 year ago | |
| DATASET.md | 1 year ago | |
| LICENSE | 1 year ago | |
| README.md | 1 year ago | |
| main.py | 1 year ago | |
| main_autoencoder.py | 1 year ago | |
| main_tsne.py | 1 year ago | |
| pretrain.sh | 1 year ago | |
| requirements.txt | 1 year ago | |
| test_dvae.sh | 1 year ago | |
| train_autoencoder.sh | 1 year ago | |
README.md
Autoencoders as Cross-Modal Teachers
Created by Runpei Dong, Zekun Qi, Linfeng Zhang, Junbo Zhang, Jianjian Sun, Zheng Ge, Li Yi, Kaisheng Ma
OpenReview | arXiv | Models
This repository contains the code release of paper Autoencoders as Cross-Modal Teachers: Can Pretrained 2D Image Transformers Help 3D Representation Learning? (ICLR 2023).
ACT🎬
The success of deep learning heavily relies on large-scale data with comprehensive labels, which is more expensive and time-consuming to fetch in 3D compared to 2D images or natural languages.
This promotes the potential of utilizing models pretrained with data more than 3D as teachers for cross-modal knowledge transferring.
In this paper, we revisit masked modeling in a unified fashion of knowledge distillation, and we show that foundational Transformers pretrained with 2D images or natural languages can help self-supervised 3D representation learning through training Autoencoders as Cross-Modal Teachers (ACT🎬).
The pretrained Transformers are transferred as cross-modal 3D teachers using discrete variational autoencoding self-supervision, during which the Transformers are frozen with prompt tuning for better knowledge inheritance.
The latent features encoded by the 3D teachers are used as the target of masked point modeling, wherein the dark knowledge is distilled to the 3D Transformer students as foundational geometry understanding.
Our ACT pretrained 3D learner achieves state-of-the-art generalization capacity across various downstream benchmarks, e.g., 88.21% overall accuracy on ScanObjectNN.
The success of deep learning heavily relies on large-scale data with comprehensive labels, which is more expensive and time-consuming to fetch in 3D compared to 2D images or natural languages.
This promotes the potential of utilizing models pretrained with data more than 3D as teachers for cross-modal knowledge transferring.
In this paper, we revisit masked modeling in a unified fashion of knowledge distillation, and we show that foundational Transformers pretrained with 2D images or natural languages can help self-supervised 3D representation learning through training Autoencoders as Cross-Modal Teachers (ACT🎬).
The pretrained Transformers are transferred as cross-modal 3D teachers using discrete variational autoencoding self-supervision, during which the Transformers are frozen with prompt tuning for better knowledge inheritance.
The latent features encoded by the 3D teachers are used as the target of masked point modeling, wherein the dark knowledge is distilled to the 3D Transformer students as foundational geometry understanding.
Our ACT pretrained 3D learner achieves state-of-the-art generalization capacity across various downstream benchmarks, e.g., 88.21% overall accuracy on ScanObjectNN.
The success of deep learning heavily relies on large-scale data with comprehensive labels, which is more expensive and time-consuming to fetch in 3D compared to 2D images or natural languages. This promotes the potential of utilizing models pretrained with data more than 3D as teachers for cross-modal knowledge transferring. In this paper, we revisit masked modeling in a unified fashion of knowledge distillation, and we show that foundational Transformers pretrained with 2D images or natural languages can help self-supervised 3D representation learning through training Autoencoders as Cross-Modal Teachers (ACT🎬). The pretrained Transformers are transferred as cross-modal 3D teachers using discrete variational autoencoding self-supervision, during which the Transformers are frozen with prompt tuning for better knowledge inheritance. The latent features encoded by the 3D teachers are used as the target of masked point modeling, wherein the dark knowledge is distilled to the 3D Transformer students as foundational geometry understanding. Our ACT pretrained 3D learner achieves state-of-the-art generalization capacity across various downstream benchmarks, e.g., 88.21% overall accuracy on ScanObjectNN.
The success of deep learning heavily relies on large-scale data with comprehensive labels, which is more expensive and time-consuming to fetch in 3D compared to 2D images or natural languages. This promotes the potential of utilizing models pretrained with data more than 3D as teachers for cross-modal knowledge transferring. In this paper, we revisit masked modeling in a unified fashion of knowledge distillation, and we show that foundational Transformers pretrained with 2D images or natural languages can help self-supervised 3D representation learning through training Autoencoders as Cross-Modal Teachers (ACT🎬). The pretrained Transformers are transferred as cross-modal 3D teachers using discrete variational autoencoding self-supervision, during which the Transformers are frozen with prompt tuning for better knowledge inheritance. The latent features encoded by the 3D teachers are used as the target of masked point modeling, wherein the dark knowledge is distilled to the 3D Transformer students as foundational geometry understanding. Our ACT pretrained 3D learner achieves state-of-the-art generalization capacity across various downstream benchmarks, e.g., 88.21% overall accuracy on ScanObjectNN.
The success of deep learning heavily relies on large-scale data with comprehensive labels, which is more expensive and time-consuming to fetch in 3D compared to 2D images or natural languages. This promotes the potential of utilizing models pretrained with data more than 3D as teachers for cross-modal knowledge transferring. In this paper, we revisit masked modeling in a unified fashion of knowledge distillation, and we show that foundational Transformers pretrained with 2D images or natural languages can help self-supervised 3D representation learning through training Autoencoders as Cross-Modal Teachers (ACT🎬). The pretrained Transformers are transferred as cross-modal 3D teachers using discrete variational autoencoding self-supervision, during which the Transformers are frozen with prompt tuning for better knowledge inheritance. The latent features encoded by the 3D teachers are used as the target of masked point modeling, wherein the dark knowledge is distilled to the 3D Transformer students as foundational geometry understanding. Our ACT pretrained 3D learner achieves state-of-the-art generalization capacity across various downstream benchmarks, e.g., 88.21% overall accuracy on ScanObjectNN.
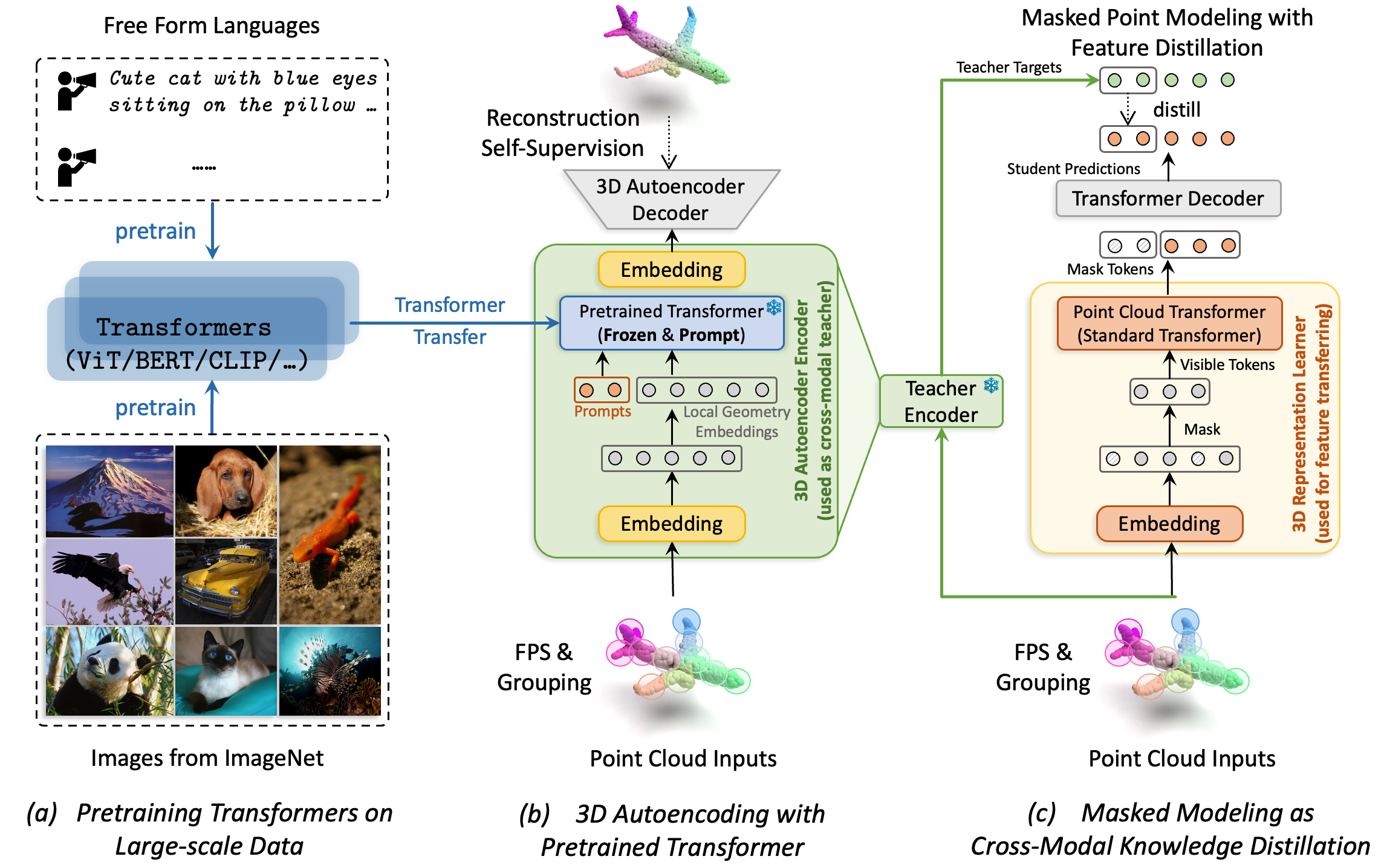
News
- 📌 Feb, 2023: Check out our latest work ReCon, which achieves 91.26% accuracy on ScanObjectNN
- 💥 Jan, 2023: ACT accepted by ICLR 2023
Environment
This codebase was tested with the following environment configurations. It may work with other versions.
- Ubuntu 18.04
- CUDA 11.3
- GCC 7.5.0
- Python 3.8.8
- PyTorch 1.10.0
1. Installation
We recommend using Anaconda for the installation process:
# Make sure `g++-7 --version` is at least 7.4.0
$ sudo apt install g++-7 # For CUDA 10.2, must use GCC < 8
# Create virtual env and install PyTorch
$ conda create -n act python=3.8.8
$ conda activate act
(act) $ conda install openblas-devel -c anaconda
(act) $ conda install pytorch==1.10.0 torchvision==0.11.0 cudatoolkit=11.3 -c pytorch -c nvidia
# Or, you can set up Pytorch with pip from official link:
# (act) $ pip install torch==1.10.0+cu113 torchvision==0.11.0+cu113 torchaudio==0.10.0+cu113 -f https://download.pytorch.org/whl/torch_stable.html # recommended
# For CUDA 10.2, use conda:
# (act) $ conda install pytorch==1.11.0 torchvision==0.12.0 torchaudio==0.11.0 -c pytorch -c nvidia
# Or pip:
# (act) $ pip install torch==1.11.0+cu102 torchvision==0.12.0+cu102 torchaudio==0.11.0 --extra-index-url https://download.pytorch.org/whl/cu102
# Install basic required packages
(act) $ pip install -r requirements.txt
# Chamfer Distance
(act) $ cd ./extensions/chamfer_dist && python setup.py install --user
# PointNet++
(act) $ pip install "git+https://github.com/erikwijmans/Pointnet2_PyTorch.git#egg=pointnet2_ops&subdirectory=pointnet2_ops_lib"
# GPU kNN
(act) $ pip install --upgrade https://github.com/unlimblue/KNN_CUDA/releases/download/0.2/KNN_CUDA-0.2-py3-none-any.whl
2. Datasets
We use ShapeNet, ScanObjectNN, ModelNet40, S3DIS and ShapeNetPart in this work. See DATASET.md for details.
3. Models
The models and logs have been released on Google Drive. See MODEL_ZOO.md for details.
4. ACT Pre-training
To pretrain ACT on the ShapeNet training set, run the following command. If you want to try different models or masking ratios etc., first create a new config file, and pass its path to --config.
ACT pretraining includes two stages:
-
Stage I, transferring pretrained Transformer on ShapeNet as 3D autoencoder by running:
CUDA_VISIBLE_DEVICES=<GPUs> python main_autoencoder.py \ --config "cfgs/autoencoder/act_dvae_with_pretrained_transformer.yaml" \ --exp_name <output_file_name>or
sh train_autoencoder.sh <GPU> -
Stage II, pretrain 3D Transformer student on ShapeNet by running:
CUDA_VISIBLE_DEVICES=<GPUs> \ python main.py --config "cfgs/pretrain/pretrain_act_distill.yaml" \ --exp_name <output_file_name>or
sh pretrain.sh <GPU>
5. ACT Fine-tuning
Fine-tuning on ScanObjectNN, run:
CUDA_VISIBLE_DEVICES=<GPUs> python main.py --config cfgs/finetune_classification/full/finetune_scan_hardest.yaml \
--finetune_model --exp_name <output_file_name> --ckpts <path/to/pre-trained/model>
Fine-tuning on ModelNet40, run:
CUDA_VISIBLE_DEVICES=<GPUs> python main.py --config cfgs/finetune_classification/full/finetune_modelnet.yaml \
--finetune_model --exp_name <output_file_name> --ckpts <path/to/pre-trained/model>
Voting on ModelNet40, run:
CUDA_VISIBLE_DEVICES=<GPUs> python main.py --test --config cfgs/finetune_classification/full/finetune_modelnet.yaml \
--exp_name <output_file_name> --ckpts <path/to/best/fine-tuned/model>
Few-shot learning, run:
CUDA_VISIBLE_DEVICES=<GPUs> python main.py --config cfgs/finetune_classification/few_shot/fewshot_modelnet.yaml --finetune_model \
--ckpts <path/to/pre-trained/model> --exp_name <output_file_name> --way <5 or 10> --shot <10 or 20> --fold <0-9>
Semantic segmentation on S3DIS, run:
cd semantic_segmentation
python main.py --ckpts <path/to/pre-trained/model> --root path/to/data --learning_rate 0.0002 --epoch 60
6. Visualization
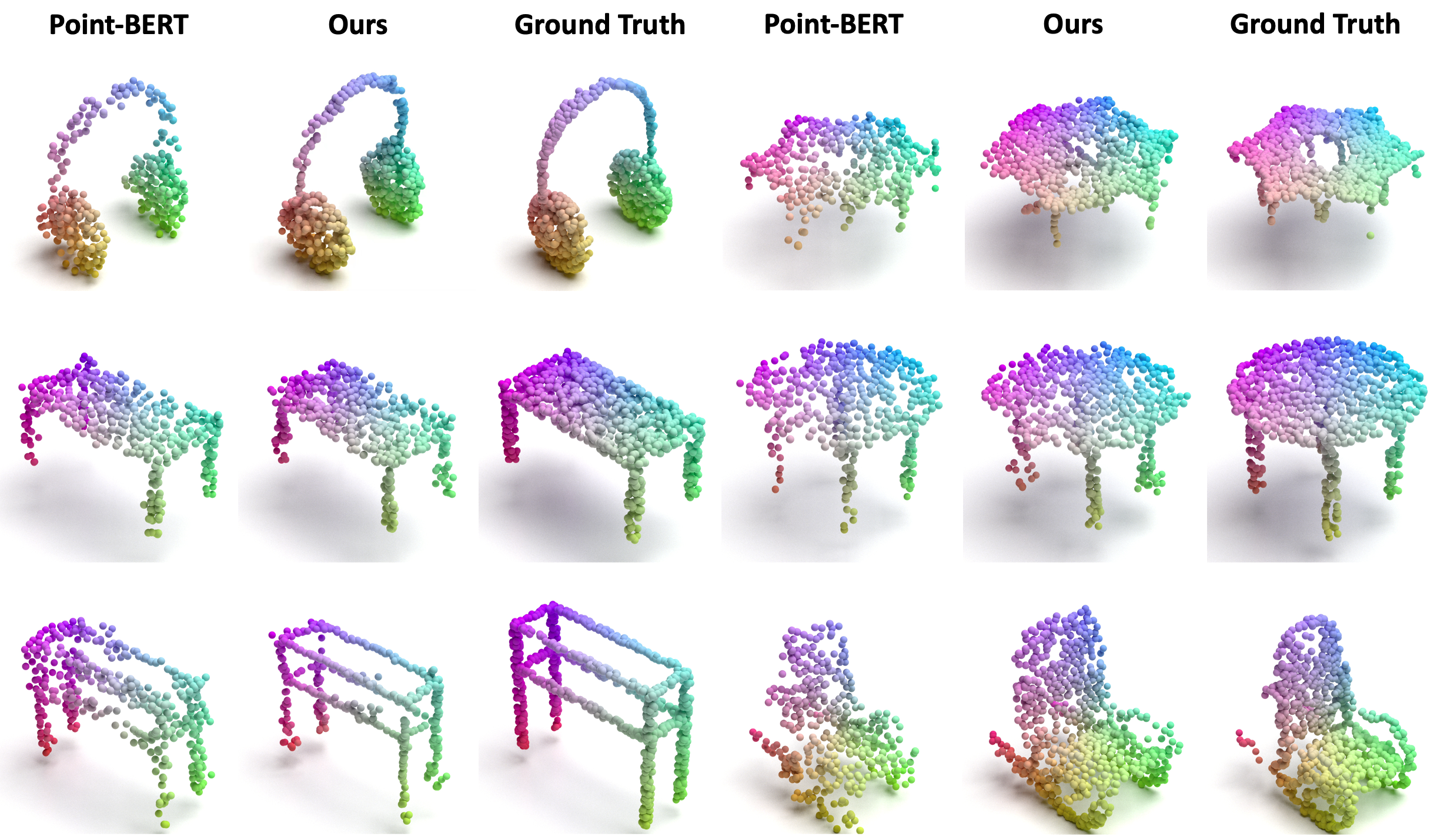
Reconstruction results of synthetic objects from ShapeNet test set. We show the comparison of our ACT autoencoder and Point-BERT dVAE model:
License
ACT is released under the MIT License. See the LICENSE file for more details. Besides, the licensing information for pointnet2 modules is available here.
Acknowledgements
Many thanks to the following codes that help us a lot in building this codebase:
Contact
If you have any questions related to the code or the paper, feel free to email Runpei (runpei.dong@gmail.com). If you encounter any problems when using the code, or want to report a bug, you can open an issue. Please try to specify the problem with details so we can help you better and quicker!
Citation
If you find our work useful in your research, please consider citing:
@inproceedings{dong2023act,
title={Autoencoders as Cross-Modal Teachers: Can Pretrained 2D Image Transformers Help 3D Representation Learning?},
author={Runpei Dong and Zekun Qi and Linfeng Zhang and Junbo Zhang and Jianjian Sun and Zheng Ge and Li Yi and Kaisheng Ma},
booktitle={The Eleventh International Conference on Learning Representations (ICLR) },
year={2023},
url={https://openreview.net/forum?id=8Oun8ZUVe8N}
}
No Description
Text Python Markdown Cuda other