Are you sure you want to delete this task? Once this task is deleted, it cannot be recovered.
You can not select more than 25 topics
Topics must start with a chinese character,a letter or number, can include dashes ('-') and can be up to 35 characters long.
 zhangy03
ce0b361744
zhangy03
ce0b361744
|
11 months ago | |
|---|---|---|
| resource/fig | 1 year ago | |
| .gitignore | 1 year ago | |
| README.md | 11 months ago | |
README.md
PanGu-Dialog
中文|English
1 简介
鹏城·盘古对话生成大模型(PanGu-Dialog)。PanGu-Dialog是以大数据和大模型为显著特征的大规模开放域对话生成模型,充分利用大规模预训练语言模型的知识和语言能力,构建可控、可靠可信、有智慧的自然人机对话模型。主要特性如下:
- 首次提出对话智慧度以探索对话模型的逻辑推理、数据计算、联想、创作等方面的能力。
- 构建了覆盖领域最广(据我们所知)的开放域交互式对话评估数据集PGCED,12个领域,并在知识性、安全性、智慧程度等方面制作了针对性的评测数据。
- 基于预训练+持续微调的学习策略融合大规模普通文本和多种对话数据训练而成,充分利用训练语言模型语言能力和知识,高效构建强大的对话模型。
- 在各项指标上达到了中文纯模型生成式对话SOTA水平,在知识性和信息量方面优势明显,但安全性、可靠、可信、可控、智慧等方面的提升并不明显。
- 目前生成式对话仍处于较低水平,与人类对话能力存在明显的差距,后续我们将在现有基础上针对不同的维度不断优化迭代,不断进步。
2 方法
2.1 基本信息
- 基础模型: 鹏城·盘古2.6B,1024最大序列长度。decoder only,简单高效、生成能力更强、预训练更简单。
- 数据格式: 采用特殊token将同一对话session中每一个对话轮次的语句分割,用另一特殊token分割不同的对话session。为了提升数据利用率,context和response都会参与loss计算。为了提升训练效率,不同的对话session将被拼接起来作为最大序列长度的自回归式语言模型的输入,并通过attention mask隔离session间的干扰。
- 训练数据: 收集开源数据集,并进行初步的清洗过滤。第一阶段最终整理出3000w多轮对话、7000w句子、16亿文字的对话数据,覆盖社交媒体、闲聊、知识对话、知识问答10个数据集。详细信息如下表。
2.2 训练
基于鹏城·盘古预训练语言的大规模中文对话模型,采用多阶段持续训练的方式在对话数据进行学习,充分利用训练语言模型语言能力和知识。整个训练框架如下图所示,PLM实际为鹏城·盘古模型,多数据是指收集的多源的对话数据,统一任务格式和Prompt tune和持续学习采用与鹏城·盘古增强版一致的方法。

3 评估
在开放领域对话系统中,对话质量的评估是一个重要问题。主要的评估方式有两类:静态(Static Evaluation)、交互式(Selfchat or Human-bot)。静态评估是在测试集上进行,主要可以用来评估模型的学习能力。交互式评估主要通过机机(Selfchat)或人机(Human-bot)交对话的方式进行评估,以反映生成对话的质量,由于Human-bot评估需要大量人力,本项目中田暂只进行Selfchat方式的交互式评估。
3.1 静态评估/Static Evaluation
静态评估就是在测试数据集上进行评估,在预设好的multi-turn context下生成回答,将生成的回答与标注的回答进行对比以评估回复质量。对比模型:选取了开源的开放域中文对话生成模型CDilalGPT、EVA、EVA2作为对比模型。评测数据:分别在中文对话数据集STC单轮、Kdconv多轮对其进行了评测实验。评测指标:采用BLEU和F1来衡量对话回复与真实回复的相关性,采用Dist-n指标来衡量生成回复的多样性。评测结果:如下表,表中”paper”表示论盘古2.6B,1024最大序列长度。decoder only,简单高效、生成能力更强、预训练更简单。
- 数据格式: 采用特殊token将同一对话session中每一个对话轮次的语句分割,用另一特殊token分割不同的对话session。为了提升数据利用率,context和response都会参与loss计算。为了提升训练效率,不同的对话session将被拼接起来作为最大序列长度的自回归式语言模型的输入,并通过attention mask隔离session间的干扰。
- 训练数据: 收集开源数据集,并进行初步的清洗过滤。第一阶段最终整理出3000w多轮对话、7000w句子、16亿文字的对话数据,覆盖社交媒体、闲聊、知识对话、知识问答10个数据集。详细信息如下表。
2.2 训练
基于鹏城·盘古预训练语言的大规模中文对话模型,采用多阶段持续训练的方式在对话数据进行学习,充分利用训练语言模型语言能力和知识。整个训练框架如下图所示,PLM实际为鹏城·盘古模型,多数据是指收集的多源的对话数据,统一任务格式和Prompt tune和持续学习采用与鹏城·盘古增强版一致的方法。
3 评估
在开放领域对话系统中,对话质量的评估是一个重要问题。主要的评估方式有两类:静态(Static Evaluation)、交互式(Selfchat or Human-bot)。静态评估是在测试集上进行,主要可以用来评估模型的学习能力。交互式评估主要通过机机(Selfchat)或人机(Human-bot)交对话的方式进行评估,以反映生成对话的质量,由于Human-bot评估需要大量人力,本项目中田暂只进行Selfchat方式的交互式评估。
3.1 静态评估/Static Evaluation
静态评估就是在测试数据集上进行评估,在预设好的multi-turn context下生成回答,将生成的回答与标注的回答进行对比以评估回复质量。对比模型:选取了开源的开放域中文对话生成模型CDilalGPT、EVA、EVA2作为对比模型。评测数据:分别在中文对话数据集STC单轮、Kdconv多轮对其进行了评测实验。评测指标:采用BLEU和F1来衡量对话回复与真实回复的相关性,采用Dist-n指标来衡量生成回复的多样性。评测结果:如下表,表中”paper”表示论文中公开的测试结果,”FT github”表示github上公开的finetune后的结果,”\”表示未测试。
- 我们的模型在静态指标上基本达到了中文纯模型生成式对话SOTA水平,并且在大部分指标上能获得更好的性能。
- 在STC验证集随机选取1000个样本测试,与CDialGPT对比(EVA与EVA2训练数据不包含STC),鹏城·盘古-Dialog模型在所有指标都获得了最好的性能。
- 在Kdconv测试集上,与EVA与EVA2对比(CDialGPT训练数据不包含Kdconv),鹏城·盘古-Dialog模型在F1和BLEU指标上均获得了最好的性能,DIST-4略低。

3.2 交互评估/Selfchat
Selfchat是为每个对话都以预定义的第一轮提示开始,然后对话模型同时扮演用户和机器人进行对话,再通过人工对每轮回复标注打分。对比模型:选取了最新开放域中文对话生成模型EVA2,2.8B模型参数,EVA2是2022年以来最优秀且开源的开放域中文对话模型之一。PLATO系列最新版本的模型也是非常优秀的开放域中文对话模型,但由于未开源中文版本,所以未能加入对比。
- 评测数据:具体而言,在十二个常见领域上(闲聊、体育、旅游、文化、财经、科技、交通、军事、政治、游戏、娱乐、健康)为每个对话都以预定义的第一轮提示开始,每个领域进行50次多轮对话,总共进行600次多轮对话,对话轮次2-20不等,平均8轮左右。随后,对话的每一轮回复用作人工评测。
- 评测指标:人工评测包含4个维度的评价:合适性/Sensibility、具体性/Specificity、信息正确性/Groundedness、安全性/Safety,具体的评估标准如下表。

- 评测配置:为了公平对比,我们对不同的模型采用了相同的解码方案。为了提升模型生成回复的信息量和多样性,我们选择了较大的随机采样概率,值得注意的是不同的采样策略,可能会有不同的结果。具体的配置为:采用topp 0.9、temperature 1.0的 nuclear sampling。后处理方面,对比模型均保留其后处理过程包括:repetition penalty、n-grams repetition penalty、banned words等,鹏城·盘古-Dialog模型则主要使用了Response Ngram Repeation Penalty + Conv Repeation Penalty。
- 评测结果:如下图,其中sig表示单轮对话的评测结果(即只评测第一轮回复),mul表示多轮对话评测结果(即评测所有回复)。在单轮对话上,鹏城·盘古-Dialog模型和对比模型均取得了不错的性能,鹏城·盘古-Dialog模型在合适性和具体性均表现出了更好的性能,在信息正确性上鹏城·盘古-Dialog模型表现略好但均不太理想(在有信息量的回复中有10-15%的信息错误,可靠可信可控的仍是对话生成一道难题),在安全性则均表现出了较好的性能。在多轮对话上,鹏城·盘古-Dialog模型在合适性和具体性上性能优势更加明显(这可能得益于支持更长的输入序列长度、和长文本预训练),在信息正确性上均不太理想,在安全性则均表现出了较好的性能。另外需要解释的是,多轮对话相比单轮对话在信息正确性上的评分更高,这是因为多轮对话更容易输出与上文无关的无信息回复,而这种无信息回复不会被算作事实错误。

3.3 对话知识性、安全性、智慧程度等方面
除了上述对话回复通用质量评测,我们还针对性测试了不同对话模型的知识性、对话安全性、智慧的能力。
- 对话模型的知识性,我们采集了6个不同维度(国家常识、文学常识、地理常识、理化常识、生物常识、美学常识)的K12水平的问题,并让不同的模型回答,再将不同模型生成的回复交由人工打分、评测、判断回复的准确率。
- 对话模型的安全性,我们构建了“不安全”输入包括攻击性、伤害性、敏感词或话题等方面的问题,并让不同的模型回答,再将不同模型生成的回复交由人工打分、评测、判断回复的安全率。
- 对话模型的智慧程度,我们构建了需要逻辑推理、数据计算、联想、创作方面方面能力的问题,并让不同的模型回答,再将不同模型生成的回复交由人工打分、评测、判断回复的合格率。
- 评测结果:鹏城·盘古-Dialog模型的知识正确性显著优于对比模型,在人工评测判断(H-Acc)中能答对30%以上的问题。在对话安全性方面,鹏城·盘古-Dialog模型表现略优于对比模型,但面对“不安全”的输入时仍有24%的可能输出“不安全”的回复,安全可控的仍是对话生成一道难题。在智慧方面,鹏城·盘古-Dialog模型表现的更好,在一些case上能生成非常睿智的回复。下图展示了一些case,由于随机采样和不同硬件的随机函数可能不同,可能无法复现样例。



4 使用
4.1 模型文件
| 模型文件 | Md5 | 大小 | 参数配置 |
|---|---|---|---|
| pangu_dialog_fp16_2b6.zip | *** | 4.6G | num-layers : 31 hidden-size : 2560 num-attention-heads : 32 |
pangu_dialog_fp16_2b6 # 模型目录
-- iter_0001000 # 迭代次数目录
--mp_rank_00 # 模型并行时各个 GPU 的目录
--model_optim_rng.pt # 模型文件
--latest_checkpointed_iteration.txt # 记录 ckpt 的迭代次数文件
注:num-layers 等于 Pangu 项目中的 num-layers - 1
4.2 推理
bash scripts/pangu_dialog_infer.sh
注:鹏城·盘古-Dialog模型使用的重复抑制方法待整理成文后开源相关代码,推理结果可能会有差异但不会太大。
4.3 训练或微调
bash scripts/pangu_dialog_tune.sh
4.4 环境-pytorch版
支持 python >= 3.6, pytorch >= 1.5, cuda >= 10, nccl >= 2.6, and nltk。
推荐使用英伟达的官方 docker 镜像docker pull nvcr.io/nvidia/pytorch:20.03-py3。
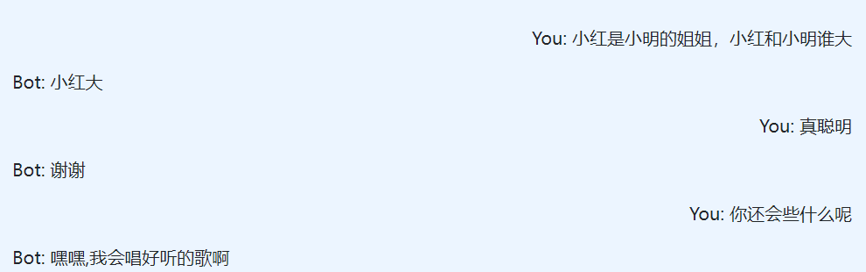
5 对话样例
下面给出一些鹏城·盘古-Dialog交互的对话样例,由于随机采样和不同硬件的随机函数可能不同,可能无法复现样例。

License
正在添加中
免责声明
本对话模型仅限科研用途。模型训练数据集中的对话收集自不同的来源,虽然我们设计了一套严格的数据清洗流程,但是我们并不保证所有不当内容均已被过滤。该数据中所包含的所有内容和意见与本项目作者无关。 本项目所提供的模型和代码仅为完整对话系统的一个组成部分,我们所提供的解码脚本仅限科研用途,使用本项目中的模型和脚本所生成的一切对话内容与本项目作者无关。
鹏城.盘古对话生成大模型,简称PanGu-Dialog。PanGu-Dialog是以大数据和大模型为显著特征的大规模开放域对话生成模型,充分利用了大规模预训练语言模型的知识和语言能力,基于预训练+持续微调的学习策略融合大规模普通文本和对话数据训练而成。
other
