Are you sure you want to delete this task? Once this task is deleted, it cannot be recovered.
You can not select more than 25 topics
Topics must start with a chinese character,a letter or number, can include dashes ('-') and can be up to 35 characters long.
 taoht
74f63f1afb
taoht
74f63f1afb
|
1 year ago | |
|---|---|---|
| .. | ||
| bpe_4w_pcl | 1 year ago | |
| spm_13w | 1 year ago | |
| spm_25w | 1 year ago | |
| README.md | 1 year ago | |
| dataset_download.py | 1 year ago | |
| dataset_sample.py | 1 year ago | |
| mindrecord_shuffle.py | 1 year ago | |
| pre_process_bc.py | 1 year ago | |
README.md
数据使用
靶场开源数据下载&本地数据上传
a)、靶场开源数据下载
#导入数据集 一带一路多语言数据集
#测试数据集将下载到当前目录下的"./SAMPLE_DATA"文件夹下,如需改变目录名称请自行修改
import wfio
_INPUT = '{"type":25,"uri":"sample_data/2114/"}'
wfio.load_files(_INPUT, dir_name='./SAMPLE_DATA')

b)、本地数据上传使用
若您的数据集大小小于20G,则可以利用靶场云盘的功能上传到数据集
## 下载数据集
import wfio
wfio.download_from_cloud_disk('path://44047257fdf04ea8b2b59f42875b3126', './USER_DATA/webtext2019zh-train.zip')
#进行解压到指定目录,如需改变目录名称请自行修改
!unzip -d ./USER_DATA ./USER_DATA/webtext2019zh-train.zip
数据抽样
这里以“一带一路多语言数据集”为例(单双语数据格式及容量,详见一带一路多语言数据集):
# 设定抽样文件本地路径和抽样保存路径
data_dir = '/cache/data/'
save_path = '/cache/data_sample/'
# 设定抽样策略, 配置中、英单语文件抽取容量, MB
mono_sample_strategy = {'zh': 1024, 'en': 1024}
# 设定抽样策略, 配置中、英双语文件抽取容量, MB
corpus_sample_strategy = {'zh-en': 1024}
# 单语抽取
!python ./dataset/dataset_sample.py \
--data_path $data_dir \ # 原始数据路径
--output_path $save_path \ # 抽取数据保存路径
--sample_strategy "{mono_sample_strategy}" \ # 数据抽取的策略
--mode 'mono' # 单语抽取模式
# 双语抽取
!python ./dataset/dataset_sample.py \
--data_path $data_dir \ # 原始数据路径
--output_path $save_path \ # 抽取数据保存路径
--sample_strategy "{corpus_sample_strategy}" \ # 数据抽取的策略
--mode 'corpus' # 双语抽取模式

数据转化、打乱
这里以转化为mindRecord数据文件为例:
data_dir = '/cache/data_sample/*.txt'
save_path = '/cache/MindRecord/mPanGu_zh-en_mindrecord'
# 多进程,一个进程绑定一个mindrecord文件写
num_mindrecord = 50 #不要设置的太小,不然进程少,转换较慢
!python ./dataset/pre_process_bc.py \
--data_path "{data_dir}" \
--output_file $save_path \
--num_process $num_mindrecord \
--tokenizer 'spm_13w'
# 文件内打乱
!python ./dataset/mindrecord_shuffle.py \
--input-dir "/cache/MindRecord/" \
--output-dir "/cache/MindRecord_shuffle/"
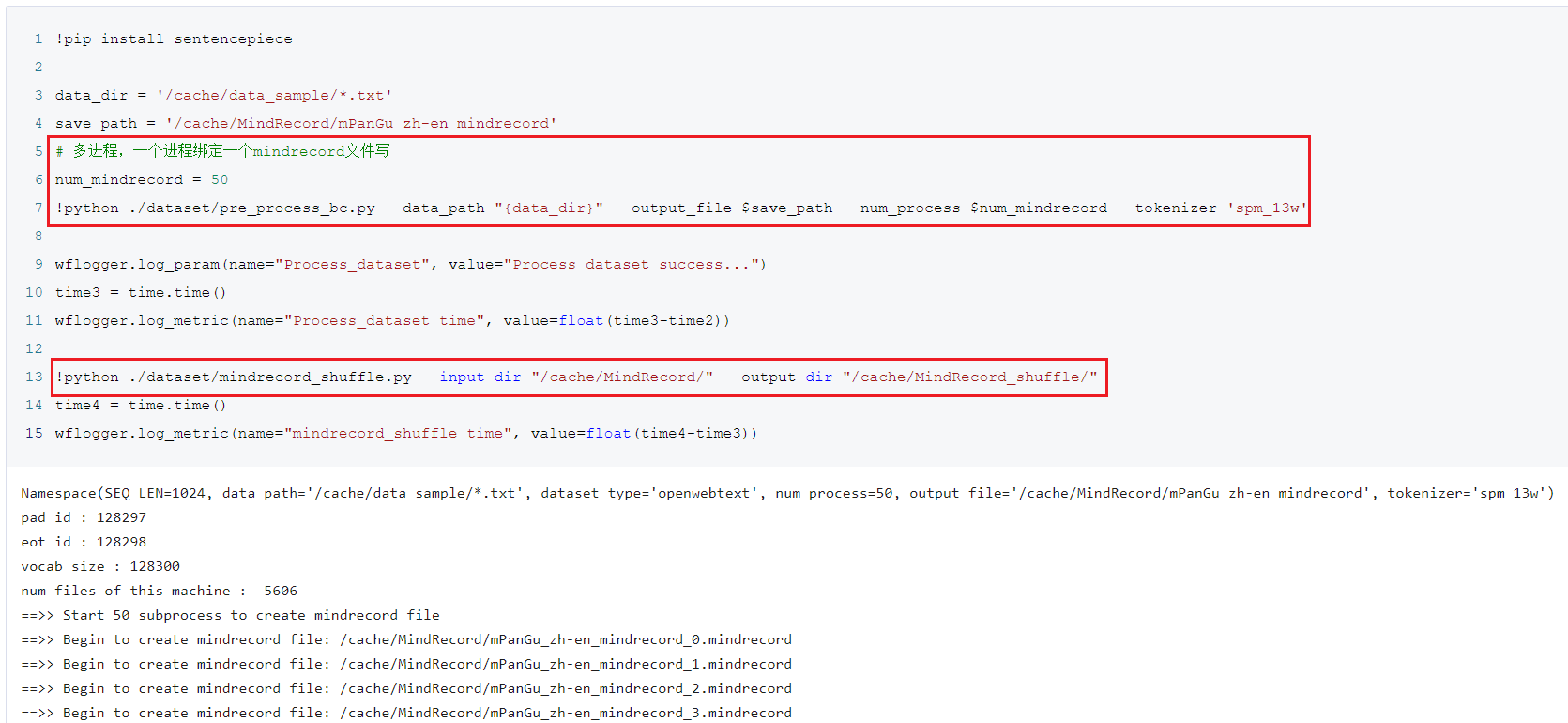
数据处理案例
client 1, client 2数据处理流程一致
#导入数据集 一带一路多语言数据集
#测试数据集将下载到当前目录下的"./SAMPLE_DATA"文件夹下,如需改变目录名称请自行修改
import wfio
_INPUT = '{"type":25,"uri":"sample_data/2114/"}'
wfio.load_files(_INPUT, dir_name='./SAMPLE_DATA')
# 设定抽样文件本地路径和抽样保存路径
data_dir = '/cache/data/'
save_path = '/cache/data_sample/'
# 设定抽样策略, 配置中、英单语文件抽取容量, MB
mono_sample_strategy = {'zh': 1024, 'en': 1024}
# 设定抽样策略, 配置中、英双语文件抽取容量, MB
corpus_sample_strategy = {'zh-en': 1024}
# 单语抽取
!python ./dataset/dataset_sample.py --data_path $data_dir --output_path $save_path --sample_strategy "{mono_sample_strategy}" --mode 'mono'
# 双语抽取
!python ./dataset/dataset_sample.py --data_path $data_dir --output_path $save_path --sample_strategy "{corpus_sample_strategy}" --mode 'corpus'
data_dir = '/cache/data_sample/*.txt'
save_path = '/cache/MindRecord/mPanGu_zh-en_mindrecord'
# 多进程,一个进程绑定一个mindrecord文件写
num_mindrecord = 50 #不要设置的太小,不然进程少,转换较慢
!python ./dataset/pre_process_bc.py --data_path "{data_dir}" --output_file $save_path --num_process $num_mindrecord --tokenizer 'spm_13w'
# 文件内打乱
!python ./dataset/mindrecord_shuffle.py --input-dir "/cache/MindRecord/" --output-dir "/cache/MindRecord_shuffle/"
b)、server启动
#调用API获取协同计算任务的端口
打开 AISynserver_client.py文件,修改 port = ais.start_server('333444')里面的字符串 #字符串用户指定标识
!python AISynserver_client.py
可得到port端口, 对应client使用的ng_port配置
c)、client启动(靶场)
!bash ma-pre-start.sh
import os
from davincirunsdk import start_and_wait_distributed_train
cmd = ['python', 'train_aisyn.py', '--distribute=true',
'--device_num=8',
'--data_url=/cache/MindRecord/',
'--run_type=train',
'--mode=350M',
'--per_batch_size=4',
'--ng_port=30021']
start_and_wait_distributed_train(cmd, output_notebook=True)
d)、client启动(GPU)
export NCCL_DEBUG=INFO
export NCCL_SOCKET_IFNAME=ib
export NCCL_IB_HCA=^mlx5_16,mlx5_17
bash scripts/run_train_aisyn_GPU.sh RANK_SIZE HOSTFILE DATASET PER_BATCH MOD PORT
example: bash run_train_350M_GPU.sh 2 hostfile /cache/MindRecord_shuffle/ 4 350M 30021
交流通道
- 提问:https://git.openi.org.cn/PCL-Platform.Intelligence/mPanGu-Alpha-53/issues
- 邮箱:taoht@pcl.ac.cn
项目信息
鹏城实验室-智能部-高效能云计算所-分布式计算研究室
许可证
[Apache License 2.0]
鹏城众智AI协同计算平台AISynergy是一个分布式智能协同计算平台。该平台的目标是通过智算网络基础设施使能数据、算力、模型、网络和服务,完成跨多个智算中心的协同计算作业,进而实现全新计算范式和业务场景,如大模型跨域协同计算、多中心模型聚合、多中心联邦学习等。
Java Vue Python JavaScript Go other







