Are you sure you want to delete this task? Once this task is deleted, it cannot be recovered.
You can not select more than 25 topics
Topics must start with a chinese character,a letter or number, can include dashes ('-') and can be up to 35 characters long.
 Lan
402f157eb4
Lan
402f157eb4
|
4 months ago | |
|---|---|---|
| .github/workflows | 1 year ago | |
| benchmarks | 10 months ago | |
| ci/st/online_learning | 1 year ago | |
| datasets/criteo_1tb | 1 year ago | |
| docs | 1 year ago | |
| examples | 10 months ago | |
| mindspore_rec | 6 months ago | |
| models | 4 months ago | |
| requirements | 1 year ago | |
| tests | 1 year ago | |
| .flake8 | 1 year ago | |
| .gitignore | 1 year ago | |
| .pre-commit-config.yaml | 1 year ago | |
| LICENSE | 1 year ago | |
| OWNERS | 1 year ago | |
| README.md | 10 months ago | |
| RELEASE.md | 8 months ago | |
| RELEASE_CN.md | 8 months ago | |
| build.sh | 1 year ago | |
| pylintrc | 1 year ago | |
| setup.py | 9 months ago | |
README.md
MindRec

![]()
概述
MindRec是昇思MindSpore在推荐领域的高性能加速库,提供了推荐领域AI模型的高效训推一体解决方案及流程指导。MindRec基于MindSpore自动并行、图算融合等基础技术能力,增加了分布式多级特征缓存以支持TB级推荐模型训练推理、基于Hash结构的动态特征表达以支持运行期特征的动态准入与淘汰、在线学习以支持分钟级模型实时更新等推荐领域的特殊场景支持,同时提供了开箱即用的数据集下载与转换工具、模型训练样例、典型模型Benchmark等内容,为用户提供了一站式的解决方案。
目录结构
└── mindrec
├── benchmarks // 推荐网络训练性能benchmark
├── datasets // 数据集下载与转换工具
├── docs // 高级特性使用教程
├── examples // 高级特性示例代码
├── mindspore_rec // 推荐网络训练相关API
│ └── train
├── models // 典型推荐模型库
│ ├── deep_and_cross
│ └── wide_deep
├── README.md
├── build.sh // 编译打包入口脚本
└── setup.py
模型库
持续丰富的模型库为用户提供了推荐领域经典模型的端到端训练流程及使用指导,直接下载MindRec源码即可使用,无需编译构建。训练不同的模型会有少量的Python依赖包需要安装,详见各个模型目录中的requirements.txt。
| 模型 | MindRec版本 | 硬件 | 数据集 | ||
|---|---|---|---|---|---|
| CPU | GPU | Ascend | |||
| Wide&Deep | >= 0.2 | / | ✔️ | ✔️ | Criteo |
| Deep&Cross Network (DCN) | >= 0.2 | / | ✔️ | / | Criteo |
模型脚本及训练精度见下表:
| model | dataset | auc | mindrec recipe | vanilla mindspore |
|---|---|---|---|---|
| Wide&Deep | Criteo | 0.8 | link | link |
| Deep&Cross Network (DCN) | Criteo | 0.8 | link | link |
编译安装
安装MindRec前,请先安装MindSpore,具体详见MindSpore安装指南。
1) 下载代码
git clone https://github.com/mindspore-lab/mindrec.git
cd mindrec
2) 编译安装
bash build.sh
pip install output/mindspore_rec-{recommender_version}-py3-none-any.whl
特性介绍
推荐领域在工程实践上面临的三个主要问题包含了持续增长的模型规模、特征的动态变化、以及模型更新的实时性,MindRec针对每个场景提供了相应的解决方案。
I. 推荐大模型
从2016年发布的Wide&Deep模型及其后续各种改进中可以了解到,推荐模型的规模主要取决于模型中特征向量的大小,随着业界在推荐业务规模上的持续发展,模型大小也快速突破了数百GB,甚至达到TB级别,因此需要一套高性能的分布式架构来解决大规模特征向量的存储、训练以及推理的问题。
根据模型规模的差异,MindRec提供了三种训练方案,分别是单卡训练、混合并行以及层级化特征缓存。
1)单卡训练
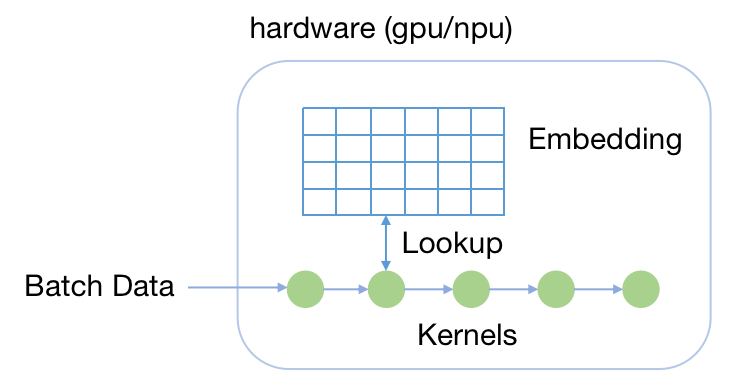
单卡训练模式与普通神经网络模型的计算方式相同,通过一张GPU或者NPU加速卡可以装载完整的模型并执行训练或者推理,该模式适合网络模型(尤其是特征表)小于加速卡显存容量(例如Nvidia GPU V100的32GB显存)的情况,训练以及推理的性能最佳。
2)多卡混合并行

混合并行模式是单卡训练的分布式版本,支持多机多卡并行训练以进一步提升模型规模和训练的吞吐量。该模式将模型中的特征表的部分通过模型并行的方式切分并保存到多张加速卡的显存中,而模型的其余部分则通过数据并行的方式完成规约计算。混合并行模式适合模型大小超过单一加速卡显存容量的情况。
3)分布式特征缓存

分布式特征缓存适用于超大规模推荐网络模型(例如TB级特征向量)的场景,该模式建立在混合并行的基础上,通过多层级特征缓存(Device <-> Local Host <-> Remote Host <-> SSD)将特征向量通过逐层级存储分离的方式扩展到更大范围的分布式存储上,从而能够在不改变计算规模的情况下,轻松扩展模型的规模,实现单张加速卡对于TB级模型的训练。
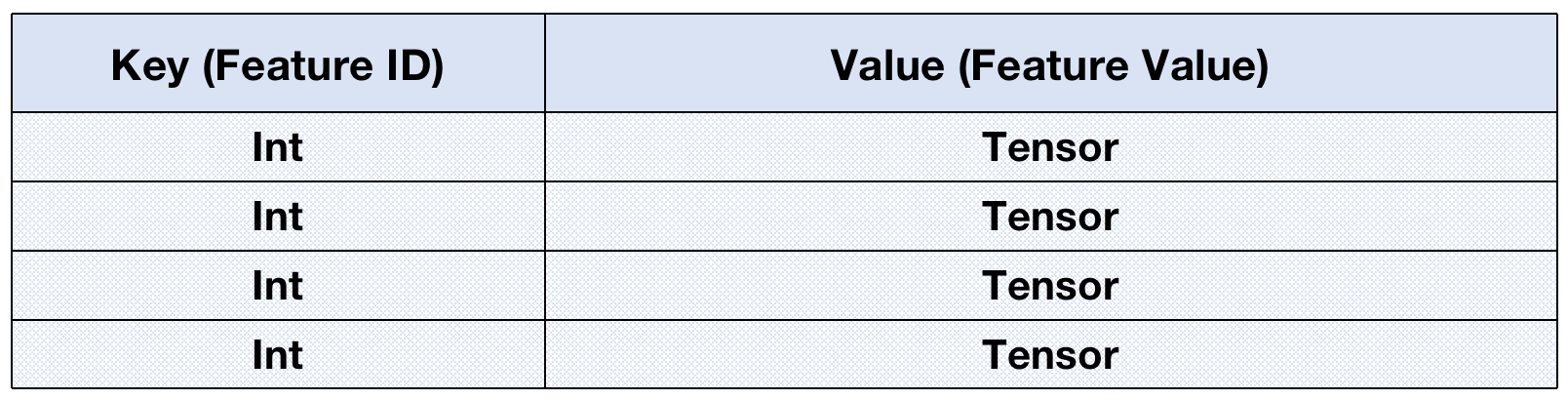
II. Hash动态特征
针对训练过程中特征会跟随时间而发生变化(新增或者消除)的场景,特征向量在表达上更加适合使用Hash结构进行存储和计算,在MindRec中可以使用名为MapParameter的数据类型表达一个Hash类型。逻辑数据结构以及示例代码如下所示:
import mindspore as ms
import mindspore.nn as nn
import mindspore.context as context
from mindspore.common.initializer import One
from mindspore.experimental import MapParameter
from mindspore import context, Tensor, Parameter
context.set_context(mode=context.GRAPH_MODE, device_target="GPU")
# Define the network.
class DemoNet(nn.Cell):
def __init__(self):
nn.Cell.__init__(self)
self.map = MapParameter(
name="HashEmbeddingTable", # The name of this hash.
key_dtype=ms.int32, # The data type of the key.
value_dtype=ms.float32, # The data type of the value.
value_shape=(128), # The shape of the value.
default_value="normal", # The default values.
permit_filter_value=1, # The threshold(the number of training step) for new features.
evict_filter_value=1000 # The threshold(the number of training step) for feature elimination.
)
def construct(self, key, val):
# Insert a key-val pair.
self.map[key] = val
# Lookup a value.
val2 = self.map[key]
# Delete a key-val pair.
self.map.erase(key)
return val2
# Execute the network.
net = DemoNet()
key = Tensor([1, 2], dtype=ms.int32)
val = Tensor(shape=(2, 128), dtype=ms.float32, init=One())
out = net(key, val)
print(out)
III. 在线学习
推荐系统中另外一个关注点是如何根据用户的实时行为数据,以在线的方式增量训练以及更新模型。MindRec支持的在线学习流程如下图所示,整个Pipeline分为四个阶段:
1)实时数据写入:增量的行为数据实时写入数据管道(例如Kafka)。
2)实时特征工程:通过MindPandas提供的实时数据处理能力,完成特征工程,将训练数据写入分布式存储中。
3)在线增量训练:MindData从分布式存储中将增量的训练数据输入MindSpore的在线训练模块中完成训练,并导出增量模型。
4)增量模型更新:增量模型导入到MindSpore推理模块,完成模型的实时更新。

上述四个阶段的开发均可通过MindSpore和MindRec生态组件以及Python表达实现,无需借助三方系统,示例代码如下所示(需要提前搭建和启动Kafka服务),详细步骤可参考在线学习指导文档:
from mindpandas.channel import DataReceiver
from mindspore_rec import RecModel as Model
# Prepare the realtime dataset.
receiver = DataReceiver(address=config.address,
namespace=config.namespace,
dataset_name=config.dataset_name, shard_id=0)
stream_dataset = StreamingDataset(receiver)
dataset = ds.GeneratorDataset(stream_dataset, column_names=["id", "weight", "label"])
dataset = dataset.batch(config.batch_size)
# Create the RecModel.
train_net, _ = GetWideDeepNet(config)
train_net.set_train()
model = Model(train_net)
# Configure the policy for model export.
ckpt_config = CheckpointConfig(save_checkpoint_steps=100, keep_checkpoint_max=5)
ckpt_cb = ModelCheckpoint(prefix="train", directory="./ckpt", config=ckpt_config)
# Start the online training process.
model.online_train(dataset,
callbacks=[TimeMonitor(1), callback, ckpt_cb],
dataset_sink_mode=True)
社区
I. 治理
查看MindSpore如何进行开放治理。
参与贡献
欢迎参与贡献。更多详情,请参阅我们的贡献者Wiki。
许可证
MindSpore large-scale recommender system library.
Python Shell C++ Markdown Text other
