
Are you sure you want to delete this task? Once this task is deleted, it cannot be recovered.
You can not select more than 25 topics
Topics must start with a chinese character,a letter or number, can include dashes ('-') and can be up to 35 characters long.
 freatraum
c16a0feb0e
freatraum
c16a0feb0e
|
1 year ago | |
|---|---|---|
| .github/workflows | 1 year ago | |
| augmentation | 1 year ago | |
| basics | 1 year ago | |
| checkpoints | 1 year ago | |
| configs | 1 year ago | |
| data | 1 year ago | |
| data_gen | 1 year ago | |
| dictionaries | 1 year ago | |
| docs | 1 year ago | |
| inference | 1 year ago | |
| modules | 1 year ago | |
| onnx | 1 year ago | |
| pipelines | 1 year ago | |
| preprocessing | 1 year ago | |
| samples | 1 year ago | |
| src | 1 year ago | |
| training | 1 year ago | |
| tts | 1 year ago | |
| utils | 1 year ago | |
| .gitignore | 1 year ago | |
| LICENSE | 2 years ago | |
| README.md | 1 year ago | |
| main.py | 1 year ago | |
| requirements.txt | 1 year ago | |
| run.py | 1 year ago | |
| test_crepe.py | 1 year ago | |
| vocode.py | 1 year ago | |
README.md
更新
训练后的模型将自动保存到启智的结果里,更新多人
2023/2/23更新
同步官方最新版本。
Usage of Refactor Branch
This is a cleaner version of Diffsinger, which provides:
- fewer code: scripts unused in the DiffSinger are marked *isolated*;
- better readability: many important functions are annotated (however, we assume the reader already knows how the neural networks work);
- abstract classes: the bass classes are filtered out into the "basics/" folder and are annotated. Other classes inherent from the base classes.
- better file structre: tts-related files are filtered out into the "tts/" folder, as they are not used in DiffSinger.
- (new) Much condensed version of the preprocessing, training, and inference pipeline. The preprocessing pipeline is at 'preprocessing/opencpop.py', the training pipeline is at 'training/diffsinger.py', the inference pipeline is at 'inference/ds_cascade.py' or 'inference/ds_e2e.py'.
Progress since we forked into this repository
TBD
Getting Started
**[ 中文教程 | Chinese Tutorial ]**
Installation
Environments and dependencies
# Install PyTorch manually (1.8.2 LTS recommended)
# See instructions at https://pytorch.org/get-started/locally/
# Below is an example for CUDA 11.1
pip3 install torch==1.8.2 torchvision==0.9.2 torchaudio==0.8.2 --extra-index-url https://download.pytorch.org/whl/lts/1.8/cu111
# Install other requirements
pip install -r requirements.txt
Pretrained models
- (Required) Get the pretrained vocoder from the DiffSinger Community Vocoders Project and unzip it into
checkpoints/folder, or train a ultra-lightweight DDSP vocoder first by yourself, then configure it according to the relevant instructions. - Get the acoustic model from releases or elsewhere and unzip into the
checkpoints/folder.
Building your own dataset
This pipeline will guide you from installing dependencies to formatting your recordings and generating the final configuration file.
Preprocessing
The following is only an example for opencpop dataset.
export PYTHONPATH=.
CUDA_VISIBLE_DEVICES=0 python data_gen/binarize.py --config configs/acoustic/nomidi.yaml
Training
The following is only an example for opencpop dataset.
CUDA_VISIBLE_DEVICES=0 python run.py --config configs/acoustic/nomidi.yaml --exp_name $MY_DS_EXP_NAME --reset
Inference
Infer from *.ds file
python main.py path/to/your.ds --exp $MY_DS_EXP_NAME
See more supported arguments with python main.py -h. See examples of *.ds files in the samples/ folder.
Deployment
Export model to ONNX format
Please see this documentation before you run the following command:
python onnx/export/export_acoustic.py --exp $MY_DS_EXP_NAME
See more supported arguments with python onnx/export/export_acoustic.py -h.
Use DiffSinger via OpenUTAU editor
OpenUTAU, an open-sourced SVS editor with modern GUI, has unofficial temporary support for DiffSinger. See OpenUTAU for DiffSinger for more details.
Algorithms, principles and advanced features
See the original paper, the docs/ folder and releases for more details.
Below is the README inherited from the original repository.
DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism
![]()

| Interactive🤗 TTS
| Interactive🤗 SVS
This repository is the official PyTorch implementation of our AAAI-2022 paper, in which we propose DiffSinger (for Singing-Voice-Synthesis) and DiffSpeech (for Text-to-Speech).
| DiffSinger/DiffSpeech at training | DiffSinger/DiffSpeech at inference |
|---|---|
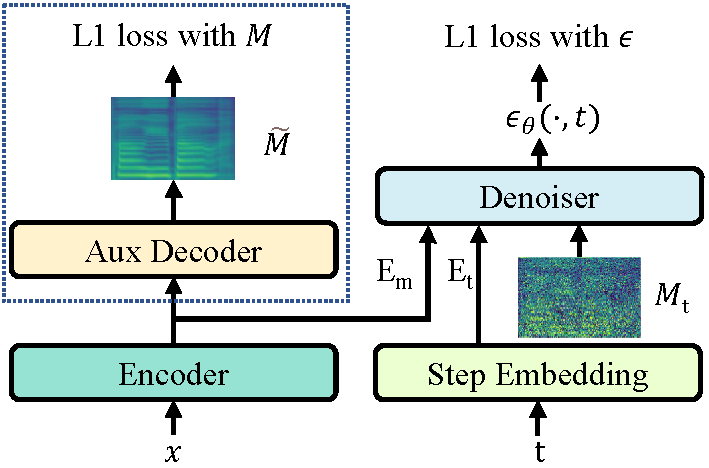 |
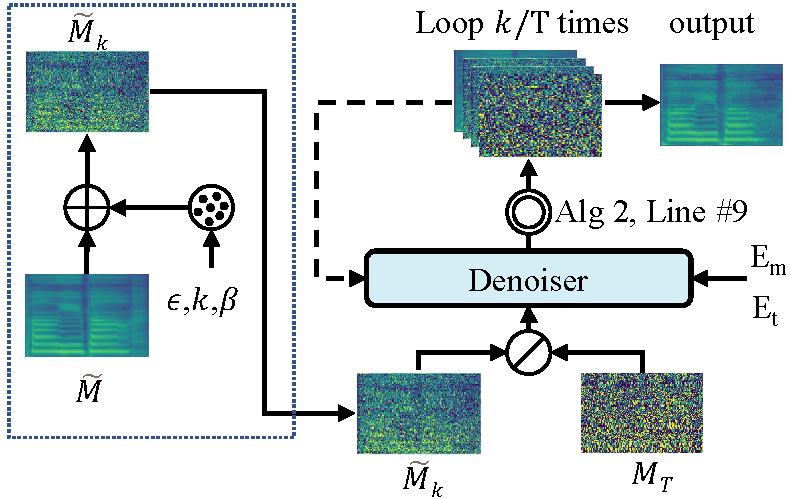 |
🎉 🎉 🎉 Updates:
- Sep.11, 2022: 🔌 DiffSinger-PN. Add plug-in PNDM, ICLR 2022 in our laboratory, to accelerate DiffSinger freely.
- Jul.27, 2022: Update documents for SVS. Add easy inference A & B; Add Interactive SVS running on HuggingFace🤗 SVS.
- Mar.2, 2022: MIDI-B-version.
- Mar.1, 2022: NeuralSVB, for singing voice beautifying, has been released.
- Feb.13, 2022: NATSpeech, the improved code framework, which contains the implementations of DiffSpeech and our NeurIPS-2021 work PortaSpeech has been released.
- Jan.29, 2022: support MIDI-A-version SVS.
- Jan.13, 2022: support SVS, release PopCS dataset.
- Dec.19, 2021: support TTS. HuggingFace🤗 TTS
🚀 News:
- Feb.24, 2022: Our new work, NeuralSVB was accepted by ACL-2022
 . Demo Page.
. Demo Page. - Dec.01, 2021: DiffSinger was accepted by AAAI-2022.
- Sep.29, 2021: Our recent work
PortaSpeech: Portable and High-Quality Generative Text-to-Speechwas accepted by NeurIPS-2021 . - May.06, 2021: We submitted DiffSinger to Arxiv .
Environments
conda create -n your_env_name python=3.8
source activate your_env_name
pip install -r requirements_2080.txt (GPU 2080Ti, CUDA 10.2)
or pip install -r requirements_3090.txt (GPU 3090, CUDA 11.4)
Documents
Tensorboard
tensorboard --logdir_spec exp_name
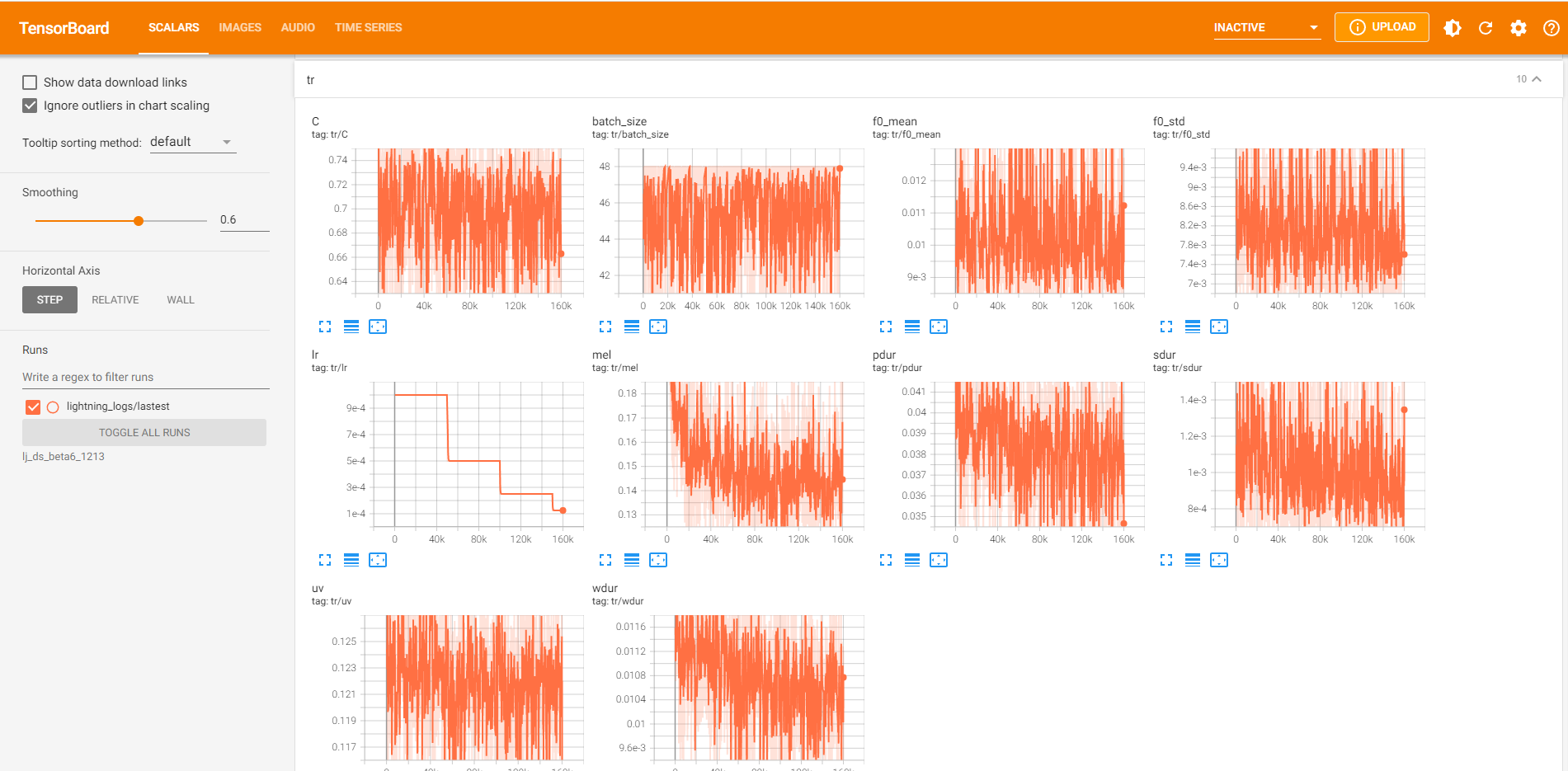 |
Audio Demos
Old audio samples can be found in our demo page. Audio samples generated by this repository are listed here:
TTS audio samples
Speech samples (test set of LJSpeech) can be found in demos_1213.
SVS audio samples
Singing samples (test set of PopCS) can be found in demos_0112.
Citation
@article{liu2021diffsinger,
title={Diffsinger: Singing voice synthesis via shallow diffusion mechanism},
author={Liu, Jinglin and Li, Chengxi and Ren, Yi and Chen, Feiyang and Liu, Peng and Zhao, Zhou},
journal={arXiv preprint arXiv:2105.02446},
volume={2},
year={2021}}
Acknowledgements
Our codes are based on the following repos:
Also thanks Keon Lee for fast implementation of our work.
No Description
Python Jupyter Notebook Text
Contributors (19)
yangqian_1015@icloud.com
33565655+yxlllc@users.noreply.github.com
jinglinliu@zju.edu.cn
54425948+oxygen-dioxide@users.noreply.github.com
 cyclekiller@
trueful@163.com
68263367+flutydeer@users.noreply.github.com
289601437@qq.com
fancy-tech-ai@
59153990+djkcyl@users.noreply.github.com
40847087+IceKyrin@users.noreply.github.com
109412646+autumn-2-net@users.noreply.github.com
44148390+colourfulspring@users.noreply.github.com
2544390577@qq.com
48796459+cyclekiller@users.noreply.github.com
55847490+SineStriker@users.noreply.github.com
cyclekiller@
trueful@163.com
68263367+flutydeer@users.noreply.github.com
289601437@qq.com
fancy-tech-ai@
59153990+djkcyl@users.noreply.github.com
40847087+IceKyrin@users.noreply.github.com
109412646+autumn-2-net@users.noreply.github.com
44148390+colourfulspring@users.noreply.github.com
2544390577@qq.com
48796459+cyclekiller@users.noreply.github.com
55847490+SineStriker@users.noreply.github.com


cyclekiller@
trueful@163.com
68263367+flutydeer@users.noreply.github.com
289601437@qq.com
fancy-tech-ai@
59153990+djkcyl@users.noreply.github.com
40847087+IceKyrin@users.noreply.github.com
109412646+autumn-2-net@users.noreply.github.com
44148390+colourfulspring@users.noreply.github.com
2544390577@qq.com
48796459+cyclekiller@users.noreply.github.com
55847490+SineStriker@users.noreply.github.com